-
Notifications
You must be signed in to change notification settings - Fork 92
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
* added introduction * address whitewum's comments * added introduction * added introduction * added introduction
- Loading branch information
1 parent
dcf1ce7
commit a401e22
Showing
4 changed files
with
221 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,73 @@ | ||
| # 什么是Nebula Graph | ||
|
|
||
| Nebula Graph是一款开源的、分布式的、易扩展的原生图数据库,能够承载数十亿个点和数万亿条边的超大规模数据集,并且提供毫秒级查询。 | ||
|
|
||
| ## 什么是图数据库 | ||
|
|
||
| 图数据库是专门存储庞大的图形网络并从中检索信息的数据库。它可以将图形中的数据高效存储为点(vertex)和边(edge),还可以将属性(property)附加到点和边上。 | ||
|
|
||
|  | ||
|
|
||
| 图数据库适合存储大多数从现实抽象出的数据类型。世界上几乎所有领域的事物都有内在联系,像关系型数据库这样的建模系统会提取实体之间的关系,并将关系单独存储到表和列中,而实体的类型和属性存储在其他列甚至其他表中,这使得数据管理费时费力。 | ||
|
|
||
| Nebula Graph作为一个典型的原生图数据库,允许将丰富的关系存储为边,边的类型和属性可以直接附加到边上。 | ||
|
|
||
| ## Nebula Graph的优势 | ||
|
|
||
| ### 开源 | ||
|
|
||
| Nebula Graph是在Apache 2.0和Commons Clause 1.0条款下开发的。越来越多的人,如数据库开发人员、数据科学家、安全专家、算法工程师,都参与到Nebula Graph的设计和开发中来,欢迎访问[Nebula Graph GitHub主页](https://github.com/vesoft-inc/nebula-graph)参与开源项目。 | ||
|
|
||
| ### 高性能 | ||
|
|
||
| 基于图数据库的特性使用C++编写的Nebula Graph,可以提供毫秒级查询。众多数据库中,Nebula Graph在图数据服务领域展现了卓越的性能,数据规模越大,Nebula Graph优势就越大。详情请参见[Nebula Graph benchmarking](https://discuss.nebula-graph.io/t/nebula-graph-1-0-benchmark-report/581)。 | ||
|
|
||
| ### 易扩展 | ||
|
|
||
| Nebula Graph采用shared-nothing架构,支持在不停止数据库服务的情况下扩缩容。 | ||
|
|
||
| ### 易开发 | ||
|
|
||
| Nebula Graph提供Java、Python、C++和Go等流行编程语言的客户端,更多客户端仍在开发中。详情请参见Nebula Graph clients(TODO: doc)。 | ||
|
|
||
| ### 高可靠访问控制 | ||
|
|
||
| Nebula Graph支持严格的角色访问控制和LDAP(Lightweight Directory Access Protocol)等外部认证服务,能够有效提高数据安全性。详情请参见验证和授权(TODO: doc)。 | ||
|
|
||
| ### 生态多样化 | ||
|
|
||
| Nebula Graph开放了越来越多的原生工具,例如[Nebula Graph Studio](https://github.com/vesoft-inc/nebula-web-docker)、[nebula-console](https://github.com/vesoft-inc/nebula-console)、[Nebula Graph Exchange](https://github.com/vesoft-inc/nebula-java/tree/master/tools/exchange)等。 | ||
|
|
||
| 此外,Nebula Graph还具备与Spark、Flink、HBase等产品整合的能力,在这个充满挑战与机遇的时代,大大增强了自身的竞争力。 | ||
|
|
||
| ### 兼容openCypher查询语言 | ||
|
|
||
| Nebula Graph查询语言,也称为nGQL,是一种声明性的、兼容openCypher的文本查询语言,易于理解和使用。详细语法请参见[nGQL指南](https://github.com/vesoft-inc/nebula-docs/tree/master/docs-2.0/3.ngql-guide)。 | ||
|
|
||
| ### 灵活数据建模 | ||
|
|
||
| 您可以轻松地在Nebula Graph中建立数据模型,不必将数据强制转换为关系表之类的结构,而且可以自由增加、更新和删除属性。详情请参见[数据模型](2.data-model.md)。 | ||
|
|
||
| ### 广受欢迎 | ||
|
|
||
| 腾讯、vivo、美团和京东数科等科技巨头都在使用Nebula Graph。详情请参见[Nebula Graph官网](https://nebula-graph.com.cn/)。 | ||
|
|
||
| ## 适用场景 | ||
|
|
||
| Nebula Graph可用于各种基于图的业务场景。为节约转换各类数据到关系型数据库的时间,以及避免复杂查询,建议您使用Nebula Graph。 | ||
|
|
||
| ### 欺诈检测 | ||
|
|
||
| 金融机构必须仔细研究大量的交易信息,才能检测出潜在的金融欺诈行为,并了解某个欺诈行为和设备的内在关联。这种场景可以通过图形建模,然后借助Nebula Graph,可以很容易地检测出诈骗团伙或其他复杂诈骗行为。 | ||
|
|
||
| ### 实时推荐 | ||
|
|
||
| Nebula Graph能够及时处理访问者产生的实时信息,并且精准推送文章、视频、产品和服务。 | ||
|
|
||
| ### 知识图谱 | ||
|
|
||
| 自然语言可以转化为知识图谱,存储在Nebula Graph中。用自然语言组织的问题可以通过智能问答系统中的语义解析器进行解析并重新组织,然后从知识图谱中检索出问题的可能答案,提供给提问人。 | ||
|
|
||
| ### 社交网络 | ||
|
|
||
| 人际关系信息是典型的图形数据,Nebula Graph可以轻松处理数十亿人和数万亿人际关系的社交网络信息,并在海量并发的情况下,提供快速的好友推荐和工作岗位查询。 |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,61 @@ | ||
| # 数据模型 | ||
|
|
||
| 本文介绍Nebula Graph的数据模型。数据模型是一种组织数据并说明它们如何相互关联的模型。 | ||
|
|
||
| ## 数据结构 | ||
|
|
||
| Nebula Graph数据模型使用5种数据结构来保存数据: | ||
|
|
||
| - **点(vertex)** | ||
|
|
||
| 点用来保存实体对象,特点如下: | ||
|
|
||
| - 点是用点标识符(`VID`)标识的。`VID`在同一图空间中唯一。 | ||
| - 点必须有至少一个标签(Tag)。 | ||
|
|
||
| - **标签(tag)** | ||
|
|
||
| 标签可以用于对点进行区分。具有相同标签的点共享相同的属性定义。 | ||
|
|
||
| - **边(edge)** | ||
|
|
||
| 边是用来连接点的,表示两个点之间的关系或行为,特点如下: | ||
|
|
||
| - 一条边有且仅有一个边类型。 | ||
| - 起点、边类型(edge type)、rank、终点可以唯一表示一条边。 | ||
| - 边是有指向的。`->`表示边的指向,边可以沿任意方向遍历。 | ||
| - 边必须有rank。rank是一个不可更改的、用户分配的、64位有符号整数。通过它才能识别两个点之间具有相同边类型的边。边按它们的rank排序,值大的边排在前面。默认rank为0。 | ||
|
|
||
| - **边类型(edge type)** | ||
|
|
||
| 边类型用于对边进行区分。具有相同边类型的边共享相同的属性定义。 | ||
|
|
||
| - **属性(properties)** | ||
|
|
||
| 属性是指以键值对(key-value)形式存储点或边的相关信息。 | ||
|
|
||
| ## 有向属性图 | ||
|
|
||
| Nebula Graph将数据存储在有向属性图中。有向属性图是指点和边构成的图,这些边是有方向的。有向属性图表示为: | ||
|
|
||
| **G = < V, E, P<sub>V</sub>, P<sub>E</sub> >** | ||
|
|
||
| - **V**是点的集合。 | ||
| - **E**是有向边的集合。 | ||
| - **P<sub>V</sub>** 是点的属性。 | ||
| - **P<sub>E</sub>** 是边的属性。 | ||
|
|
||
| 通过下面的示例图来介绍有向属性图的基本概念。 | ||
|
|
||
| 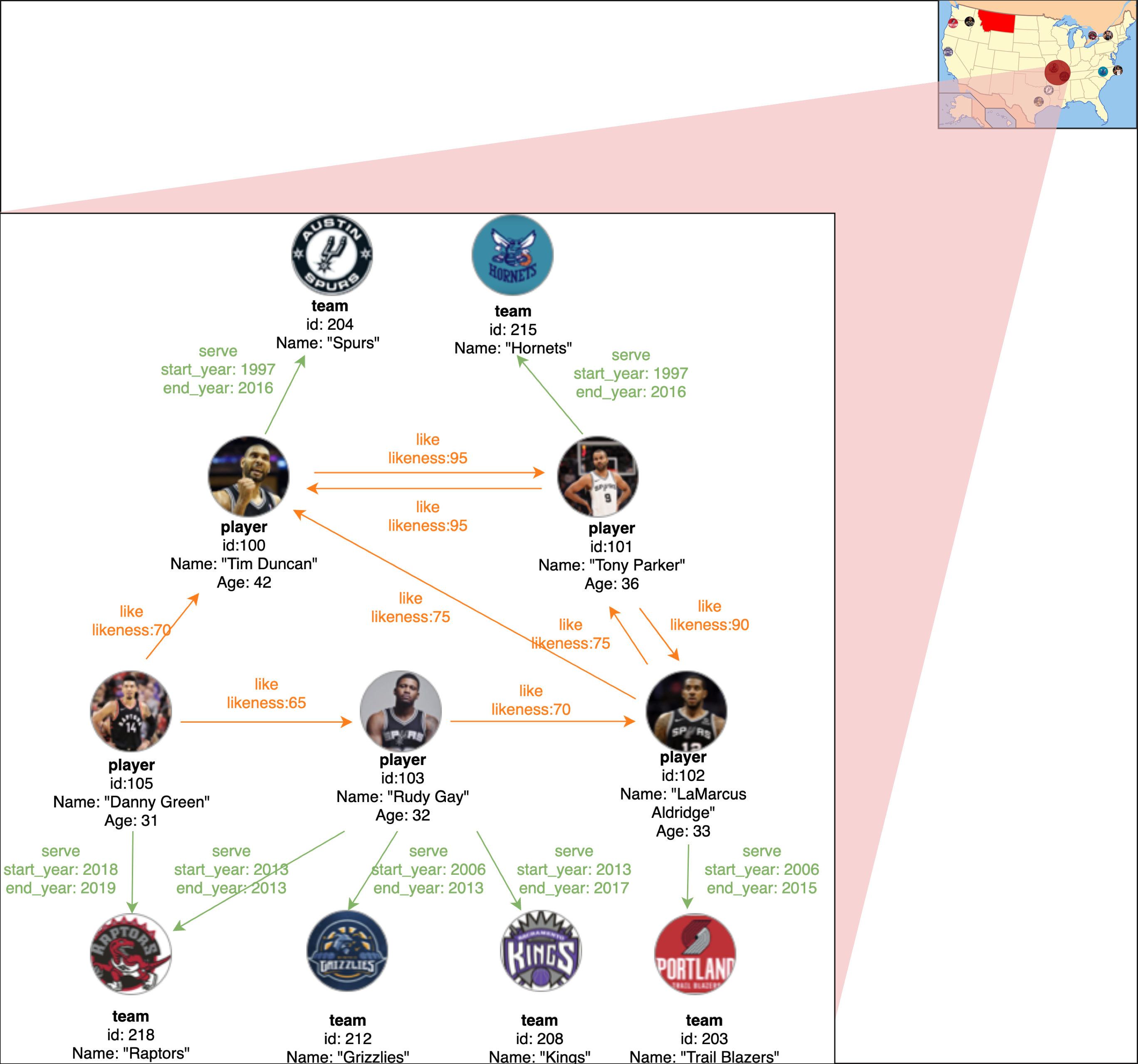 | ||
|
|
||
| 图片展示了一组关于NBA球员和球队的数据。有两种类型的点(**player**、**name**)和两种类型的边(**serve**、**like**)。 | ||
|
|
||
| 下表为图片数据模型的详细信息。 | ||
|
|
||
| | 类型 | 名称 | 属性名(数据类型) | 说明 | | ||
| | :--- | :--- | :---| :--- | | ||
| |tag| **player** | name (string) <br>age (int) | 表示NBA球员。 | | ||
| |tag| **team** | name (string) | 表示NBA球队。 | | ||
| |edge type| **serve** | start_year (int) <br> end_year (int) | 表示NBA球员的行为。<br>该行为将球员和球队联系起来,方向是从球员到球队。 | | ||
| |edge type| **like** | likeness (int) | 表示NBA球员的行为。<br>该行为将两个球员联系起来,方向是从一个球员到另一个球员。 | |
37 changes: 37 additions & 0 deletions
37
docs-2.0/1.introduction/3.nebula-graph-architecture/1.architecture-overview.md
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,37 @@ | ||
| # 架构总览 | ||
|
|
||
| Nebula Graph由三种服务构成:Graph服务、Meta服务和Storage服务。 | ||
|
|
||
| 每个服务都有可执行的二进制文件和对应进程,您可以使用这些二进制文件在一个或多个计算机上部署Nebula Graph集群。 | ||
|
|
||
| 下图展示了Nebula Graph集群的经典架构。 | ||
|
|
||
|  | ||
|
|
||
| ## Meta服务 | ||
|
|
||
| 在Nebula Graph架构中,Meta服务是由nebula-metad进程提供的,负责数据管理,例如Schema操作、集群管理和用户权限管理等。 | ||
|
|
||
| Meta服务的详细说明,请参见[Meta服务](2.meta-service.md)。 | ||
|
|
||
| ## Graph服务和Storage服务 | ||
|
|
||
| Nebula Graph采用计算存储分离架构。Graph服务负责处理计算请求,Storage服务负责存储数据。它们由不同的进程提供,Graph服务是由nebula-graphd进程提供,Storage服务是由nebula-storaged进程提供。计算存储分离架构的优势如下: | ||
|
|
||
| - 易扩展 | ||
|
|
||
| 分布式架构保证了Graph服务和Storage服务的灵活性,方便扩容和缩容。 | ||
|
|
||
| - 高可用 | ||
|
|
||
| 如果提供Graph服务的服务器有一部分出现故障,其余服务器可以继续为客户端提供服务,而且Storage服务存储的数据不会丢失。服务恢复速度较快,甚至能做到用户无感知。 | ||
|
|
||
| - 节约成本 | ||
|
|
||
| 计算存储分离架构能够提高资源利用率,而且可根据业务需求灵活控制成本。如果使用[Nebula Graph Cloud](https://cloud.nebula-graph.com.cn/ "Nebula Graph Cloud official website"),可以进一步节约成本。 | ||
|
|
||
| - 开放更多可能性 | ||
|
|
||
| 基于分离架构的特性,Graph服务可以在多种存储引擎上单独运行,Storage服务也可以为多种计算引擎提供服务。 | ||
|
|
||
| Graph服务和Storage服务的详细说明,请参见Graph服务 (TODO: doc) 和Storage服务(TODO: doc)。 |
50 changes: 50 additions & 0 deletions
50
docs-2.0/1.introduction/3.nebula-graph-architecture/2.meta-service.md
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,50 @@ | ||
| # Meta服务 | ||
|
|
||
| 本文介绍Meta服务的架构和功能。 | ||
|
|
||
| ## Meta服务架构 | ||
|
|
||
| 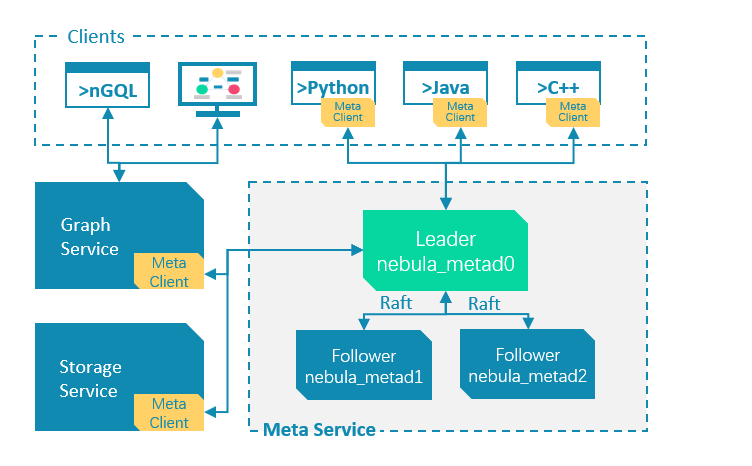 | ||
|
|
||
| Meta服务是由nebula-metad进程提供的,您可以根据场景配置nebula-metad进程数量: | ||
|
|
||
| - 测试环境中,您可以在每个机器上配置1个或3个nebula-metad进程。 | ||
| - 生产环境中,建议您在每个机器上都配置3个nebula-metad进程以保证高可用。 | ||
|
|
||
| 所有nebula-metad进程构成了基于Raft协议的集群,其中一个进程是leader,其他进程都是follower。 | ||
|
|
||
| leader是由多数派选举出来,只有leader能够对客户端或其他组件提供服务,其他follower作为候补,如果leader出现故障,会在所有follower中选举出新的leader。 | ||
|
|
||
| >**说明**:leader和follower的数据通过Raft协议保持一致,因此leader故障和选举新leader不会导致数据不一致。 | ||
| ## Meta服务功能 | ||
|
|
||
| ### 管理用户账号 | ||
|
|
||
| Meta服务中存储了用户的账号和权限信息,当客户端通过账号发送请求给Meta服务,Meta服务会检查账号信息,以及该账号是否有对应的请求权限。 | ||
|
|
||
| 更多Nebula Graph的访问控制说明,请参见验证和授权(TODO: doc)。 | ||
|
|
||
| ### 管理分片 | ||
|
|
||
| Meta服务负责存储和管理分片的位置信息,并且保证分片的负载均衡。 | ||
|
|
||
| ### 管理图空间 | ||
|
|
||
| Nebula Graph支持多个图空间,不同图空间内的数据是安全隔离的。Meta服务存储所有图空间的元数据(非完整数据),并跟踪数据的变更,例如增加或删除图空间。 | ||
|
|
||
| ### 管理Schema信息 | ||
|
|
||
| Nebula Graph是强类型图数据库,它的Schema包括标签、边类型、标签属性和边类型属性。 | ||
|
|
||
| Meta服务中存储了Schema信息,同时还负责Schema的添加、修改和删除,并记录它们的版本。 | ||
|
|
||
| 更多Nebula Graph的Schema信息,请参见[数据模型](../2.data-model.md)。 | ||
|
|
||
| ### 管理基于TTL的数据回收 | ||
|
|
||
| Meta服务提供基于TTL(time to live)的自动数据回收和空间回收。 | ||
|
|
||
| ### 管理作业 | ||
|
|
||
| Meta服务中的作业管理模块负责作业的创建、排队、查询和删除。 |