![]()

.png)
.png)
.png)
.png)
.png)
.png)
.png)
raw data from multiple sources. compute any attributes from the raw data before combining it all ito one big data set Ingestion Service
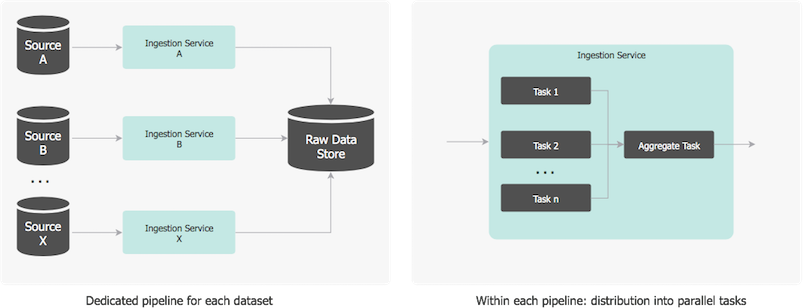
a composite orchestration service, which encapsulates the data sourcing and persistence. Internally, a repository pattern is employed to interact with a data service, which in return interacts with the data store. When the data is saved in the database, a unique batch-id is assigned to the dataset, to allow for efficient querying and end-to-end data lineage and traceability. To be performant, the ingestion distribution is twofold: • there is a dedicated pipeline for each dataset so all of them are processed independently and concurrently, and • within each pipeline, the data is partitioned to take advantage of the multiple server cores, processors or even servers. Spreading the data preparation across multiple pipelines, horizontally and vertically, reduces the overall time to complete the job.
- get basic stats
- impute missing data either by removing rows with missing data,or replacing with mean/mode
- look for outliers, trends, skewed distributions
- perform statistical test, t-test, ANOVA, chi squared, ect
Broadly speaking, a data preparation pipeline should be assembled into a series of immutable transformations, that can easily be combined.
- perform transformations
- rank features
- kick out features
https://miro.medium.com/max/1400/1*Abaj_g0TjFTnr0cwfcdTTQ.png
{kind=link}
These are the accepted type codes for data types in saga
-
Particle
- TYPE CHARACTERS:
- 'i' : Integer
- 'd' : Double
- 's' : String
- 'n' : Nan/Null
- 'o' : ordinal
- 'c' : Categorical
- 'D' : Distance
- 'O' : Object
- TYPE CHARACTERS:
-
Column
- TYPE CHARACTERS:
- 'T' : a target column
- 'M' : a meta column (one that isnt to be used in learning such as ID numbers)
- 'C' : a category column (such as red or blue)
- 'G' : a custom object column
- 'O' : a ordinal column (Ordered categorys such as A,B, and C grades)
- 'N' : a numerical column
- TYPE CHARACTERS:
- Threading Logic: When running a threaded implementation, threads are designed to work on one column or row at a time.