Caffe Tutorial : 1.Blobs, Layers, and Nets (Kor)
Blobs, 계층들, 그리고 망들 : Caffe 모델 분석 (blobs, Layers, and Nets : Anatomy of a Caffe Model)
심층 네트워크(deep networks)는 수많은 데이터를 분석하는 내부 연결 계층의 집단으로써 표현되는 구조적 모델이다. Caffe는 그 자체 모델 개요에서 계층과 계층의 망으로 선언한다. 이러한 망은 입력데이터에서부터 손실까지 전체가 상향식(bottom to top)으로 정의된다. Caffe는 정방향과 역방향의 처리방식의 망을 통해 유도된 흐름과 데이터로써 저장하며 소통하고, 그리고 blobs로써 정보 덩어리를 다룬다.
Blob란 프레임워크에 대한 표준배열과 통합된 메모리의 인터페이스이다. 이 계층은 모델과 계산 양쪽 모두의 기반으로써 다음역할을 해준다. 망은 수집과 계층간 연결로 정의된다. Blob의 세부사항은 계층과 망 안이나 혹은 서로를 가로지르며 어떻게 정보를 저장하고 소통하는지를 묘사한다.
해결하는 것(Solving)이 최적화와 모델링을 나누어 분리해 따로따로 구성한다.
우리는 좀 더 자세하게 이러한 구성들을 살펴볼 것이다.
Blob는 Caffe로 나아가고 처리되는 실제 데이터로 빠르게 이동하며, 그리고 또한 hood가 CPU와 GPU 사이의 동일화 능력을 제공한다. 수학적으로, blob는 C와 유사한 방식으로 저장된 N차원의 배열이다. Caffe는 blobs를 사용해서 데이터를 저장하고 소통한다. Blobs는 이미지 일회 처리량, 모델 파라미터 그리고 최적화에 대한 유도체들 같은 데이터를 잡아두는 통합된 메모리 인터페이스를 제공한다. Blob는 필요한만큼 CPU 호스트부터 GPU 장치까지 동일화함에 의해 계산적이고 지능적으로 넘어서 이러과정을 하는 혼합된 CPU/GPU 작업을 보이지 않게한다. 호스트와 장치의 메모리는 효율적 메모리 사용을 위해 요구되는 만큼 할당된다. 이미지 데이터 일회 처리량에 대한 틀에 적용된 blob 차원은 N x K(채널) x H(높이) x W(밑변)로 나타낸다. Blob 메모리는 구성에서 행 우선이라 끝 쪽/ 가장 오른쪽 차원부터 제일 빠르게 전환된다. 예를 들어, 4차원 blob에서, 지표 (n,k,h,w)인덱스에 값은 물리적으로 ((n*K+k)*H+h)*W+w로 배치된다.
-
숫자 N은 데이터의 일회 처리량 사이즈이다. 일괄처리는 소통과 장치를 처리하는데 있어 좀 더 나은 처리율을 달성할 수 있다. 256 이미지 일회 처리량 훈련하는 이미지망에 대하여 N은 256이다
-
채널 K는 향후의 RGB이미지 K = 3에 대한 수이다.
비록 Caffe example속 많은 blob들이 이미지 어플리케이션에 대한 축들을 가진 4차원으로 제공할지라도, 이미지가 아닌 어플리케이션에 대하여 blob들을 사용하는 것도 유효한 방법임을 알아야한다. 예를들어 만약 간단히 틀에 적용된 다중계층 퍼셉트론 (학습능력을 갖는 패턴분류장치)와 같은 완전 접속망이 필요하다면, 2차원 blobs (shape(N, D))을 사용하고 우리가 후에 다룰 내부생산계층을 필요로 한다. 파라미터 blob 차원들은 계층의 구성과 타입에 따라 다양하다. 11 x 11 공간 차원에 대한 96개의 필터들로 구성된 컨볼루션 계층에대하여 3개 인풋 blob는 96 x 3 x 11 x 11이 된다. 100개 출력 채널과 1024 입력채널로 구성된 내부생성 / 완전 접속 계층에 해하여 파라미터 blob는 1000 x 1024이다.
사용자 지정 데이터에 대하여 사용자 자신만의 데이터 계층이나 입력 준비 툴을 처리할 필요가 있다. 하지만 당신의 데이터를 넣기만한다면, 당신이 할 일은 끝난다. 계층의 모듈성 개선이 당신이 수행해야할 나머지 작업이다.
우리는 종종 blob의 기울기 만큼이나 값에 대해 흥미가 있기 때문에 blob는 “data”와 “diff”라는 메모리의 두 덩어리를 저장한다. "data"는 우리가 처리하는 평범한 데이터이고 후자는 네트워크에 의해 그래디언트로 계산된 것이다. 좀더 나아가 실제 값이 CPU와 GPU 모두에 저장되기 때문에. 이들에게 접근하는 방법은 2가지가 있다. 값을 변환하지 않는 “const” 방법, 그리고 값을 변환하는 “mutable” 방법이 존재한다.
Const Dtype * cpu_data() const;
Dtype* mutable_cpu_data;
이렇게 코딩을 하는 이유는 blob는 데이터 전송을 최소화하고 디테일을 동일화하는 과정을 보이지 않게 하기위해 CPU와 GPU사에이 값을 동일화하는 “SyncedMem” class를 사용한다. 당신이 값을 바뀌지 않길 원한다면 항상 const를 사용하되, 절대 자신의 객체의 포인터를 저장하지 마라. 매번 당신이 blob를 만들 때마다, “SyncedMem”이 언제 데이터를 복사할지 찾아낼 필요가 있기 때문에 포인터를 가지는 함수를 필요로한다. 실제로 GPU가 존재할 때, 디스크부터 CPU코드의 코드까지 데이터를 불러오면서 GPU 계산을 하는 장치 커널을 불러오고 그리고 고단계의 수행을 하는동안 저단계의 사항을 무시하면서 다음 계층으로 blob를 전송한다. 모든계층이 GPU수행능력을 가지고 있는 한, 모든 중속도 데이터(intermediate Data)와 그래디언트는 GPU에 남을 것이다. 만약 blob가 데이터를 복사해올 때, 확인하기를 원한다면 설명되어있는 예제를 다음과 같이 제시한다.
// 데이터가 CPU상에서 초기화 되었다고 가정하고, blob를 저장한다.
const Dtype* foo;
Dtype* bar;
foo = blob.gpu_data(); // data copied cpu->gpu.
foo = blob.cpu_data(); // no data copied since both have up-to-date contents.
bar = blob.mutable_gpu_data(); // no data copied.
// ... 과정 생략 ...
bar = blob.mutable_gpu_data(); // no data copied when we are still on GPU.
foo = blob.cpu_data(); // data copied gpu->cpu, since the gpu side has modified the data
foo = blob.gpu_data(); // no data copied since both have up-to-date contents
bar = blob.mutable_cpu_data(); // still no data copied.
bar = blob.mutable_gpu_data(); // data copied cpu->gpu.
bar = blob.mutable_cpu_data(); // data copied gpu->cpu.
계층은 계산의 핵심적인 단위와 모델이 필수적인데 계층은 필터들과 pool로 둘둘말려있으며, 내부 생산을 취하고, Rectified linear와 시그모이드, 그리고 다른 elementwise tramformation같은 비선형성을 적용하고, 일반화하며 데이터를 불러오고, 그리고 softmax나 hinge같은 손실을 계산한다. 모든 실행들은 계층 카탈로그를 보아라. 대부분의 타입들이 요구하는 최신 딥러닝 계층 역할들이 여기에 있다.
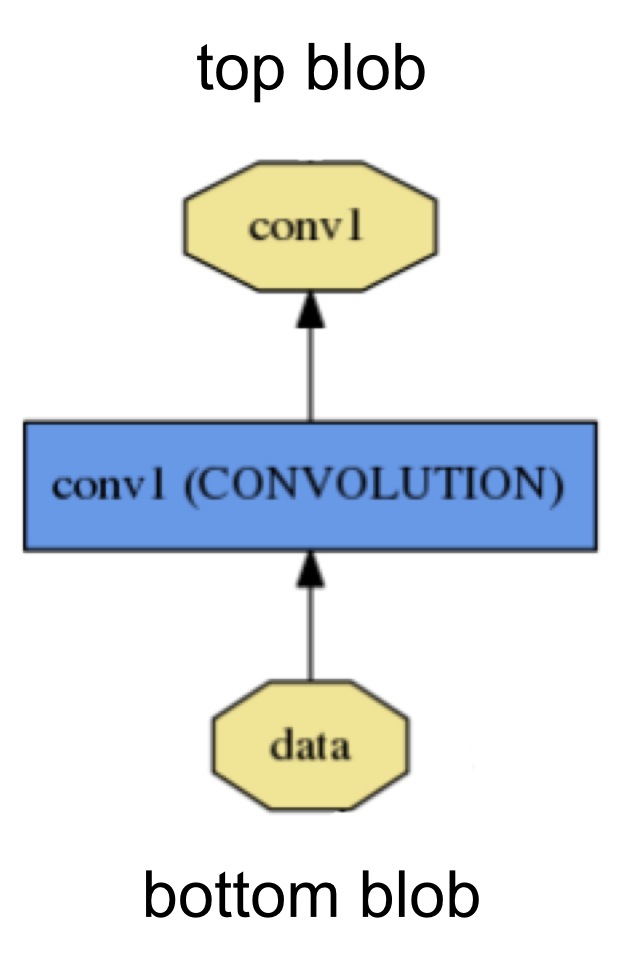
위와 같은 계층은 bottom연결을 통하여 입력을 받고, top연결을 통한 출력을 만들어 낸다 각각의 계층타입은 3가지의 중요한 연산인 setup, forward, backward으로 정의된다.
- Setup : 모델 초기화와 동시에 계층과 계층간 연결을 초기화한다.
- Forward : bottom으로부터 받은 입력을 계산하여 top으로 출력을 보낸다.
- Backward : top 그래디언트 w.r.t.를 출력 그래디언트 w.r.t를 인풋으로 계산하여 bottom으로 전송한다. 파라미터로 구성된 계층은 그 파라미터로 w.r.t.를 계산하여 이를 내부에 저장한다.
좀 더 자세하게 Forward와 Backward 기능은 하나는 CPU에서, 하나는 GPU에서 계산을 할 것이다. 만약 GPU 버전에서 수행할 수 없다면, 계층이 백업 옵션으로 CPU기능으로 후퇴한다. 비록 추가적인 데이터 전송 비용이 발생하더라도 빠른 테스트를 원한다면 이 방법이 유용할 수도 있다.(입력이 GPU부터 CPU까지 복사할 것이고, 아웃풋이 역으로 CPU에서 GPU까지 복사할 것이다.) 계층들은 전체 네트워크의 실행에 있어 두가지 중대한 임무이 있는데, 입력을 받아 출력을 생성하는 정방향 과정과, 출력에 대한 그래디언트를 입력과 파리미터에 대하여 그래디언트를 연산하여 취하는 역방향 과정이 있는데 이는 초기 계층으로 back-propagated 하는 것이다. 이러한 과정들이 각각 계층의 forward와 backward의 구조이다.
사용자 정의 계층들을 개발하는 것은 코드의 모듈성과 네트워크의 구조적 특성에 의해 최소의 노력을 필요로 한다. 계층에 대한 설정, 정방향과 역방향을 정의하라. 그 다음은 망(net)의 내용에 대해서 언급할 것이다.
망은 부분적으로 함수와 함수그래디언트를 구성과 자동 차별화를 통해 정의한다. 모든 계층에서 출력의 구성은 주어진 역할을 하는 함수를 계산하고, 모든 계층에서 역방향 구성은 손실에서 역할를 학습하는 것까지의 그래디언트를 계산한다. Caffe 모델들은 종단 기계학습 엔진이다.
망은 Computation graph(Direct Acyclic graph (DAG)를 사용한다.)로 연결된 계층들의 집합이다. Caffe는 정방향과 역방향 과정의 정확도를 확실히 하기위해 모든 과정을 기록한다. 전형적인 망은 디스크에서 호출하는 데이터 계층으로 시작해서 분류화나 복구 같은 역할에 대한 오브젝티브를 계산하는 손실 계층으로 끝을 맺는다.
망은 계층의 집단으로 선언되고 평서문 모델링 언어로 그들의 연결이 정의된다. 간단히 logistic regression classifier는 다음과 같이 정의 된다.
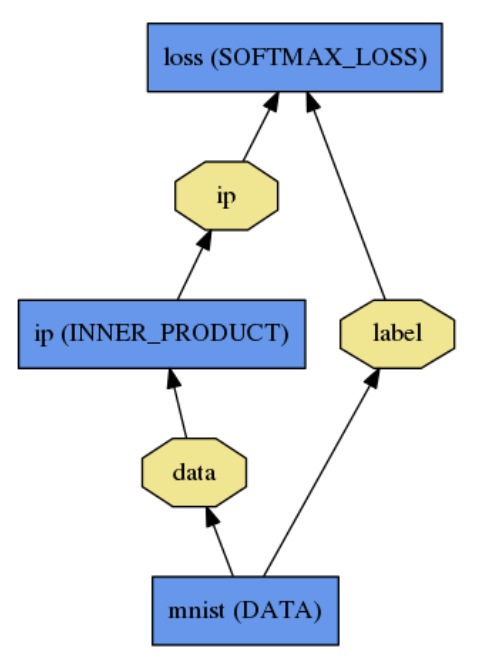
name: "LogReg"
layer {
name: "mnist"
type: "Data"
top: "data"
top: "label"
data_param {
source: "input_leveldb"
batch_size: 64
}
}
layer {
name: "ip"
type: "InnerProduct"
bottom: "data"
top: "ip"
inner_product_param {
num_output: 2
}
}
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "ip"
bottom: "label"
top: "loss"
}
모델 초기화는 “Net :: Init()”로 다루어 진다. 초기화는 주로 두가지 역할을 한다. 계층들의 “SetUp()” 기능을 호출하며, 계층들과 blobs를 생성함에 의해 전체 DAG 발판을 마련한다. (C++ Geeks에서는 망은 생존시간동안 계층과 bolb의 소유권을 유지한다.) 또한 다른 것들의 집단에 대하여 과정을 적는데 이를 테면 전체 네트워크의 설계구조의 정확도를 유효하게 하는것과 같은 것들을 기록해둔다. 또, 초기화하는동안, 망은 다음과 같은 INFO에 로깅함으로써 초기화를 설명한다.
I0902 22:52:17.931977 2079114000 net.cpp:39] Initializing net from parameters:
name: "LogReg"
[...model prototxt printout...]
# 계층간의 네트워크를 구성한다.
I0902 22:52:17.932152 2079114000 net.cpp:67] Creating Layer mnist
I0902 22:52:17.932165 2079114000 net.cpp:356] mnist -> data
I0902 22:52:17.932188 2079114000 net.cpp:356] mnist -> label
I0902 22:52:17.932200 2079114000 net.cpp:96] Setting up mnist
I0902 22:52:17.935807 2079114000 data_layer.cpp:135] Opening leveldb input_leveldb
I0902 22:52:17.937155 2079114000 data_layer.cpp:195] output data size: 64,1,28,28
I0902 22:52:17.938570 2079114000 net.cpp:103] Top shape: 64 1 28 28 (50176)
I0902 22:52:17.938593 2079114000 net.cpp:103] Top shape: 64 (64)
I0902 22:52:17.938611 2079114000 net.cpp:67] Creating Layer ip
I0902 22:52:17.938617 2079114000 net.cpp:394] ip <- data
I0902 22:52:17.939177 2079114000 net.cpp:356] ip -> ip
I0902 22:52:17.939196 2079114000 net.cpp:96] Setting up ip
I0902 22:52:17.940289 2079114000 net.cpp:103] Top shape: 64 2 (128)
I0902 22:52:17.941270 2079114000 net.cpp:67] Creating Layer loss
I0902 22:52:17.941305 2079114000 net.cpp:394] loss <- ip
I0902 22:52:17.941314 2079114000 net.cpp:394] loss <- label
I0902 22:52:17.941323 2079114000 net.cpp:356] loss -> loss
# 손실을 설정하고 역방향 과정을 구성한다.
I0902 22:52:17.941328 2079114000 net.cpp:96] Setting up loss
I0902 22:52:17.941328 2079114000 net.cpp:103] Top shape: (1)
I0902 22:52:17.941329 2079114000 net.cpp:109] with loss weight 1
I0902 22:52:17.941779 2079114000 net.cpp:170] loss needs backward computation.
I0902 22:52:17.941787 2079114000 net.cpp:170] ip needs backward computation.
I0902 22:52:17.941794 2079114000 net.cpp:172] mnist does not need backward computation.
# 출력을 결정한다.
I0902 22:52:17.941800 2079114000 net.cpp:208] This network produces output loss
# 초기화를 마치고 메모리 사용치를 보고한다.
I0902 22:52:17.941810 2079114000 net.cpp:467] Collecting Learning Rate and Weight Decay.
I0902 22:52:17.941818 2079114000 net.cpp:219] Network initialization done.
I0902 22:52:17.941824 2079114000 net.cpp:220] Memory required for data: 201476
네트워크의 구조는 단말기에 상관없이 소프트웨어 프로그램이나 시스템을 사용 가능하다. 앞에서 우리가 설명했던 것을 돌이켜 보면, bolb와 계층은 모델 선언으로부터 보이지않는 곳에서 수행하는 사항들이라고 하였다. 구조를 만든 후에, 네트워크는 “Caffe::mode()”에서와 정의되고 “Caffe::set_mode()”에서 설정된 단일 스위치를 설정함에 의해서 CPU나 GPU상에서 작동한다. 계층들은 동일한 결과를 만들어내는 CPU와 GPU틀에 상응하는 것에 딸려있다. (수많은 에러가 등장하지만 이를 막는 테스트도 함께한다.) CPU/GPU 스위치는 매끄럽고 모델 선언에 대해 독립적이다. 이것은 연구나 배치 같은 들을 위하여 모델과 수행을 나누어 정의하는 최상의 방법이다.
Binary protocol buffer (binaryproto) Caffemodel files로써 학습된 모델을 급수화 하는 동안 모델은 Plaintext Protocol Buffer Schema (prototxt)로 선언된다. Model 형태는 caffe.proto 안의 protobuf schema에 의해 정의된다. 소스파일의 대부분 라인들이 설명이 존재하기 때문에 확인하는 것이 좋다. Caffe는 다음과 같은 강점에 대하여 Google Protocol Buffer를 사용한다. Minimal-size binary strings (급수화 할때, - Serialized), Efficient Serialization, 아주 확실한 C++과 Python, 다양한 언어에서 효율적인 인터페이스 수행 그리고 이진수 버전과 사람이 읽을 수 있는 글 형태이다. 이러한 모든 것들은 Caffe에서 모델링에대한 확장성과 유연성에 기여한다.