Set write_empty_chunks to default to False #853
Conversation
|
Sounds great to me :) Thanks for doing what I didn't have the courage to do. |
d83df68
to
f3280a7
Compare
|
@joshmoore wdyt? |
|
👍 from me. I think this is a much better default. |
|
There are some lines scattered throughout the tests like these zarr-python/zarr/tests/test_core.py Line 91 in edced8e zarr-python/zarr/tests/test_sync.py Line 103 in edced8e Do we want to update those as well? |
🤷 All this means is that more tests will run with the default True. This might be useful for historical reasons. Both True and False are explicitly tested so I don't think we need to worry. |
3e7dbea
to
6b461a7
Compare
|
This is now rebased on the latest master. |
|
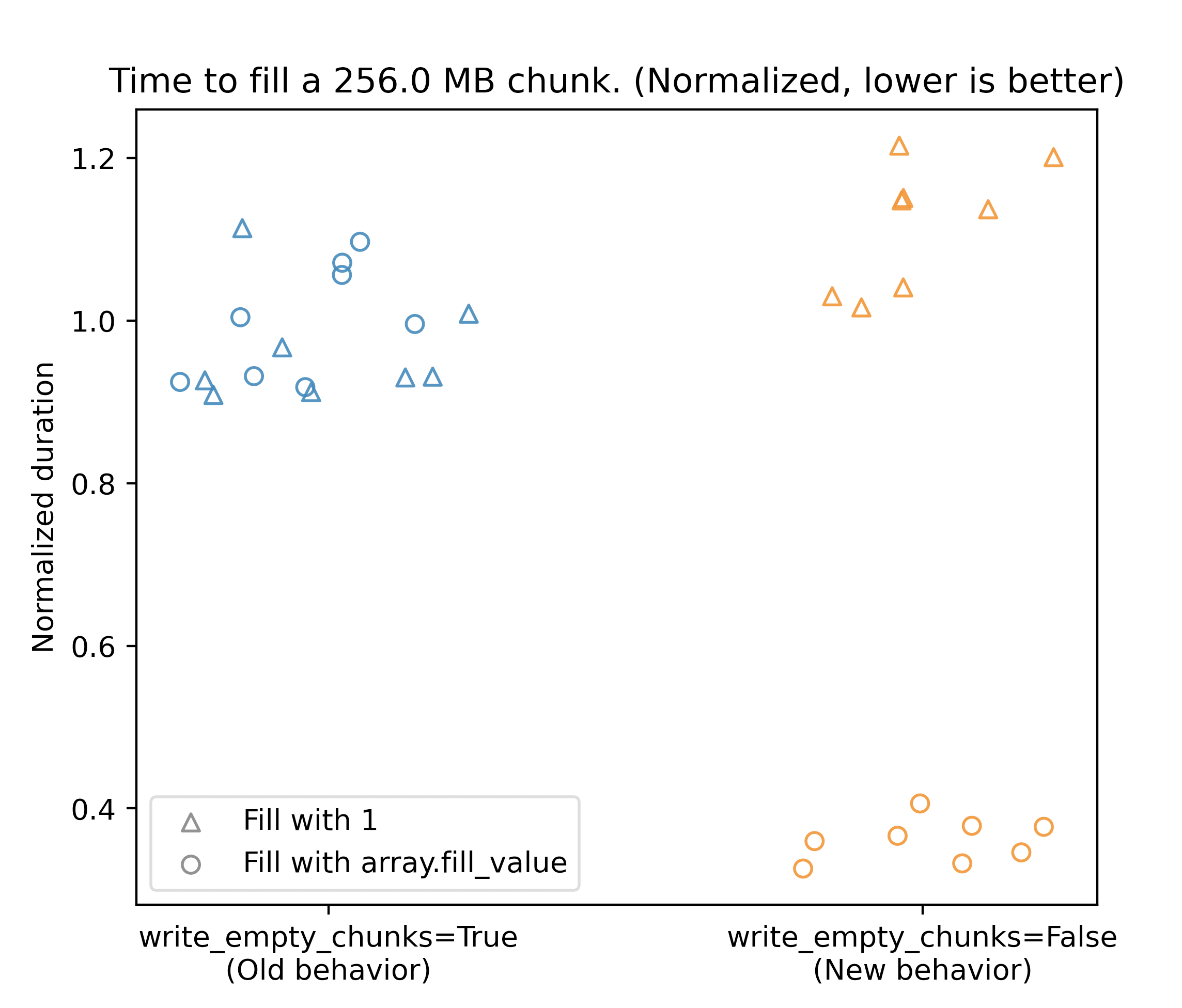
Capturing initial results from @d-v-b here: "users with "dense" data will see a ~15% increase in write times" |
|
N.B. that result doesn't include compression time. I will provide improved benchmarking code later today with a more realistic workflow. |
|
some interesting benchmarking results. see this repo for code: https://github.com/d-v-b/zarr-benchmarks Each test writes a 64 MB chunk 128 times with First, with no compressor: Next, with Blosc compression: And last, with GZip compression: Takeaways:
Happy to hear suggestions for changing the benchmark / plotting. E.g., maybe we want to show absolute duration instead of relative durations. |



|
What sort of local disk are you using? I can imagine very different results for SSD vs HDD vs cloud object stores. Extra copies are never desirable, but in most cases I would guess the overhead of checking is acceptable. |
|
@shoyer this is on an SSD, so pretty ideal in terms of storage latency. |
|
@joshmoore I added content to the tutorial docs, let me know if you want more or an expanded release note. I'm not sure the benchmarks are that illuminating or surprising, so maybe we don't really need to involve them? |
|
The location looks good. Could I suggest we try to get two or four simple writes with the different flags and inputs. Something like: from https://github.com/d-v-b/zarr-benchmarks/blob/main/src/zarr-benchmarks/empty_chunks.py with some form of marker ("15% slower") for someone to see at a glance.
Agreed. Happy to have them in your repo. I find them pretty fascinating. ;) |
|
@d-v-b, did you have a chance to try the other flags Josh mentioned above? 🙂 |
… into default-write-empty-chunks-false
|
I added a short benchmark example, but I can't build the docs for some reason ( |
|
Oh and there's a new test failure in an unrelated part of the codebase. Not sure what's going on there. |
|
Oy vey. That's a new year for you. The new failures is related to the category filter. I don't remember anything that should impact it. Just starting to look at the docs failure. (Thanks for the benchmark example!) |
|
Ok, @d-v-b, that should fix the docs build. Let's see what's failing on this run. |
|
Hi both, I'm unclear about whether I need to do anything here, please ping me directly if you want me to update something. 😊 |
|
Sorry for dropping the ball here. Don't think there's anything needed from your side, @jni. Just very unsure what's up with this failing test. Other than that, I'd very much like to get 2.11 out ASAP. |
The call to `np.any(array)` in zarr.util.all_equal triggers the following ValueError: ``` > return ufunc.reduce(obj, axis, dtype, out, **passkwargs) E ValueError: invalid literal for int() with base 10: 'baz' ``` Extending the catch block allows test_array_with_categorize_filter to pass, but it's unclear if this points to a deeper issue.
|
Ok. Pushed a proposed fix related to @d-v-b's |
| @@ -670,7 +670,7 @@ def all_equal(value: Any, array: Any): | |||
| # optimized to return on the first truthy value in `array`. | |||
| try: | |||
| return not np.any(array) | |||
| except TypeError: # pragma: no cover | |||
| except (TypeError, ValueError): # pragma: no cover | |||
There was a problem hiding this comment.
What causes the ValueError? Is there a particular array type or value that np.any is raising on?
There was a problem hiding this comment.
It occurs when a category value (baz) gets passed to int().
There was a problem hiding this comment.
from failing build
______________________ test_array_with_categorize_filter _______________________
def test_array_with_categorize_filter():
# setup
data = np.random.choice(['foo', 'bar', 'baz'], size=100)
flt = Categorize(dtype=data.dtype, labels=['foo', 'bar', 'baz'])
filters = [flt]
for compressor in compressors:
> a = array(data, chunks=5, compressor=compressor, filters=filters)
zarr/tests/test_filters.py:172:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
zarr/creation.py:366: in array
z[...] = data
zarr/core.py:1285: in __setitem__
self.set_basic_selection(pure_selection, value, fields=fields)
zarr/core.py:1380: in set_basic_selection
return self._set_basic_selection_nd(selection, value, fields=fields)
zarr/core.py:1680: in _set_basic_selection_nd
self._set_selection(indexer, value, fields=fields)
zarr/core.py:1732: in _set_selection
self._chunk_setitem(chunk_coords, chunk_selection, chunk_value, fields=fields)
zarr/core.py:1994: in _chunk_setitem
self._chunk_setitem_nosync(chunk_coords, chunk_selection, value,
zarr/core.py:2002: in _chunk_setitem_nosync
if (not self.write_empty_chunks) and all_equal(self.fill_value, cdata):
zarr/util.py:672: in all_equal
return not np.any(array)
<__array_function__ internals>:180: in any
???
/usr/share/miniconda/envs/minimal/lib/python3.10/site-packages/numpy/core/fromnumeric.py:2395: in any
return _wrapreduction(a, np.logical_or, 'any', axis, None, out,
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
obj = array(['baz', 'baz', 'baz', 'bar', 'foo'], dtype='<U3')
ufunc = <ufunc 'logical_or'>, method = 'any', axis = None, dtype = None
out = None, kwargs = {'keepdims': <no value>, 'where': <no value>}
passkwargs = {}
def _wrapreduction(obj, ufunc, method, axis, dtype, out, **kwargs):
passkwargs = {k: v for k, v in kwargs.items()
if v is not np._NoValue}
if type(obj) is not mu.ndarray:
try:
reduction = getattr(obj, method)
except AttributeError:
pass
else:
# This branch is needed for reductions like any which don't
# support a dtype.
if dtype is not None:
return reduction(axis=axis, dtype=dtype, out=out, **passkwargs)
else:
return reduction(axis=axis, out=out, **passkwargs)
> return ufunc.reduce(obj, axis, dtype, out, **passkwargs)
E ValueError: invalid literal for int() with base 10: 'baz'
/usr/share/miniconda/envs/minimal/lib/python3.10/site-packages/numpy/core/fromnumeric.py:86: ValueError
There was a problem hiding this comment.
Interesting. Looks like the error message and type changed from NumPy 1.21 to 1.22. Don't think that was intentional, but could be wrong. Raised issue ( numpy/numpy#20898 )
In any event this workaround seems reasonable in the interim
There was a problem hiding this comment.
Great, thanks! Once this is green, I'll move forward with 2.11.0.
e.g. was just mentioning to @MSanKeys963 how cool the use case from https://forum.image.sc/t/data-store-and-library-backend-for-napari-plugin/61779 is ;) (....still waiting on actions...) |
|
Trying to reopen to get tests to complete. |
|
I've not been able to get the 3.8 and 3.9 tests to run on this PR yet. (3-4 retries) |
|
Looks like some of the past commits in this PR (though not all) had the same issue |
|
Oddly py 3.7 is still spinning here compared to #951 |
|
Power cycling for CI. |
|
Holy moly that was an adventure! Looks like we're good to move forward with 2.11. (🍺 🍸 or similar all around this weekend) |
In #738, despite general agreement that most people expect write_empty_chunks to default to False, @d-v-b decided to go the safe, uncontroversial route to get the PR merged, and made the default value True. All this PR does is set the default to False.
Convenient links to discussion suggesting write_empty_chunks=False should be the default:
There were performance concerns with FSSpec bulk delete items, but it seems that they were addressed upstream.
TODO: