-
Notifications
You must be signed in to change notification settings - Fork 1
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
Showing
222 changed files
with
2,493 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,56 @@ | ||
| --- | ||
| title: CORS-跨域相关问题 | ||
| categories: BOM、DOM | ||
| date: 2017-05-23 | ||
| --- | ||
| 近期出于工作原因,又折腾了跨域问题,nginx的配置变的生疏了,这次在这里做个总结... | ||
|
|
||
| #### 跨域问题如何产生的? | ||
| 跨域限制是浏览器特有的行为,出于安全考虑,浏览器不允许脚本获取其他域下资源。 | ||
| 同域需要同时满足以下3点 | ||
| 1. 协议: https和http属于不同协议,会产生跨域问题 | ||
| 2. 域名: 比如www.baidu.com与www.taobao.com; aaa.baidu.com与bbb.baidu.com 子域也都属于跨域 | ||
| 3. 端口: 8080、80不同端口号,当然也会产生跨域问题 | ||
|
|
||
| #### 服务器间通信存在跨域吗? | ||
| 不存在!跨域限制是浏览器行为,是浏览器为了保护用户隐私的一种策略,服务器是没有这个限制的。 | ||
| 即使存在跨域问题,在浏览器的network中也是可以看到http response的。 | ||
| 只是浏览器限制脚本去获取response内容。 | ||
|
|
||
| 1.正常情况下,没有开启跨域插件,fetch其他域的资源,可以看到报错,脚本无法获取response | ||
|  | ||
|
|
||
| 2.开启跨域插件,fetch其他域的资源,开启之后插件会对http req res做些修改,欺骗浏览器,脚本可以拿到response | ||
|  | ||
|
|
||
| #### 如何解决跨域问题? | ||
| 1. 跨域问题与服务器没有直接关系,但是想要跨域成功,仍然需要服务端做一些配合,也就是response header里面加一些字段 | ||
| ```bash | ||
| location / { | ||
| // 允许哪个域名来访问资源 | ||
| add_header 'Access-Control-Allow-Origin' "*"; | ||
|
|
||
| // 请求的返回内容里包含cookies | ||
| add_header 'Access-Control-Allow-Credentials' 'true'; | ||
|
|
||
| // 允许请求的method | ||
| add_header 'Access-Control-Allow-Methods' 'GET, POST, OPTIONS'; | ||
|
|
||
| add_header 'Access-Control-Allow-Headers' 'DNT,X-CustomHeader,Keep-Alive,User-Agent,X-Requested-With,If-Modified-Since,Cache-Control,Content-Type'; | ||
| } | ||
|
|
||
| ``` | ||
|
|
||
| 2. 使用服务器做转发,也就是脚本在本域下发起请求,由服务器做转发,这样就不会有跨域问题,以下是nginx配置 | ||
| ``` bash | ||
| location /api/baidu { | ||
| proxy_pass https://www.baidu.com; | ||
| proxy_redirect off; | ||
| proxy_set_header Host $host; | ||
| proxy_set_header X-Real-IP $remote_addr; | ||
| } | ||
| ``` | ||
|
|
||
| 3. jsonp方式 | ||
| 其实不难发现,我们的img标签经常会使用其他域下的图片资源,但是浏览器没有做限制。 | ||
| 所以之前也会有利用 src 属性做跨域请求的手段出现,但限制是只能是get请求,hack成份比较多,不推荐。 |
File renamed without changes.
File renamed without changes.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,38 @@ | ||
| --- | ||
| title: CSS-盒模型 | ||
| date: 2016-06-23 | ||
| categories: CSS | ||
| --- | ||
|
|
||
| html中所有元素都可以看作“盒子” | ||
|
|
||
| ### 正常盒模型 | ||
|
|
||
| - #### BLOCK:块级元素 | ||
| 1. block元素会独占一行,默认宽度自动填满其父元素宽度 | ||
| 1. 包括:内容(content)、填充(padding)、边框(border)、边界(margin)。 | ||
| 1. 总宽度/高度 = width/height + padding + border + margin | ||
|
|
||
| - #### INLINE:行内元素 | ||
| 1. 行内元素:一行排满才会换行,宽度随元素内容多少变化 | ||
| 1. inline元素属性:line-height设置高度,width、height无效,只有**水平方向的margin、padding**边距有效果,垂直方向的margin padding无效。 | ||
|
|
||
| ### 怪异模式盒模型 | ||
| - #### BLOCK:块级元素 | ||
| 1. 盒子的总宽度和高度是包含内边距padding和边框border宽度在内的 | ||
| 1. 总宽度/高度= width/height + margin = 内容区宽度/高度 + padding + border + margin; | ||
| 2. 注意:怪异模式下,width = 内容宽度 + padding + border ,width和内容宽度不是一个概念 | ||
|
|
||
|
|
||
| ### 外边距合并(叠加) | ||
| 普通文档流中块框的垂直外边距才会发生外边距合并,合并后的外边距的高度等于两个发生合并的外边距中较高的那个边距值 | ||
| <img src="./img/css-margin.png" width = "600" height = "430" align=center /> | ||
|
|
||
| ### 示例 | ||
| 关于block元素的height问题,直接看下图 | ||
| 元素的高度 | ||
| #### xx.offsetHeight: padding-top + padding-bottom + border-top + border-bottom + height | ||
| #### xx.clientHeight: padding-top + padding-bottom + height | ||
| #### xx.scrollHeight: margin-top + margin-bottom + padding-top + padding-bottom + border-top + border-bottom + height | ||
|
|
||
| <img src="./img/css-box.png" width = "610" height = "630" align=center /> |
File renamed without changes.
File renamed without changes.
File renamed without changes.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,38 @@ | ||
| --- | ||
| title: Express入门 | ||
| date: 2016-05-13 20:10:36 | ||
| categories: NodeJS | ||
| --- | ||
|
|
||
| 新手入门指引,如果你很熟悉express的用法那么就可以跳过教程到底部,到github看下源码 | ||
| https://github.com/zhentaoo/coconut | ||
|
|
||
| #### 1.首先需要安装node环境,版本最新比较好,最低4.0+吧,我本地的node环境是6.4: | ||
|  | ||
|
|
||
| #### 2.express中文官网,在这里大家可以学习完整的express框架 | ||
| http://www.expressjs.com.cn/ | ||
|
|
||
| #### 3.到官网可以学一些express的基础用法,初始化一个项目seed可以使用express生成器 | ||
|
|
||
| ```js | ||
| npm install express-generator -g | ||
| ``` | ||
|  | ||
|
|
||
|
|
||
| #### 4.接下来用生成器初始化一个项目 | ||
| express tieba-node,我的项目叫做tieba-nonde,可以任意起name | ||
| 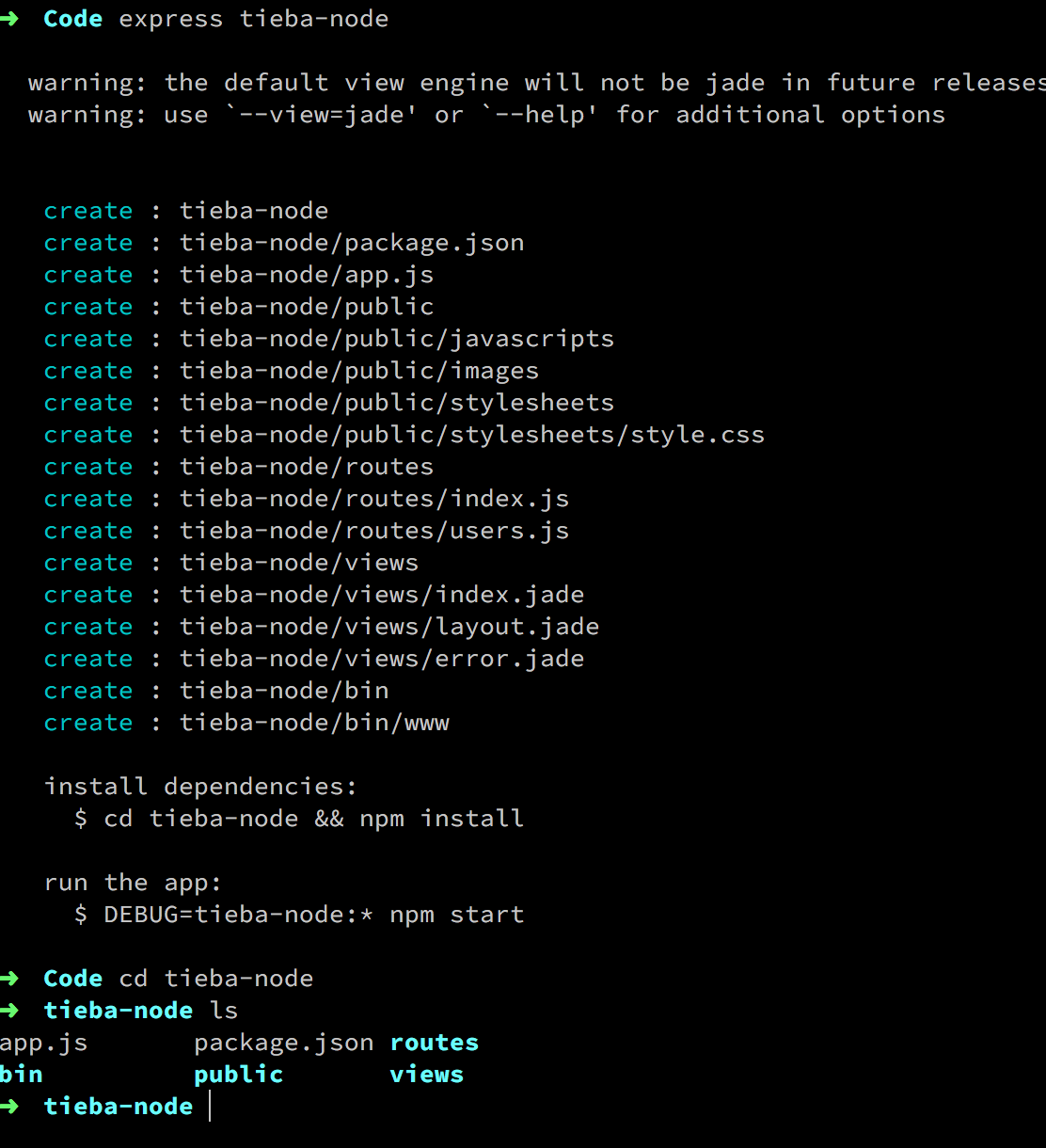 | ||
|
|
||
| #### 5.进入项目目录 ,执行npm install 安装项目所需要的依赖,看到下图的情况说明依赖安装完成 | ||
|  | ||
|
|
||
| #### 6.在项目目录下,执行npm start,运行项目,访问 http://127.0.0.1:3000即可看到效果,如果成功看到下图的效果,那么恭喜你,你已经成功了!! | ||
|  | ||
|
|
||
| #### 7.你已经学会的基本的express项目构建 | ||
| 接下来可以 访问https://github.com/zhentaoo/Coconut,学习完整的express blog 源码, | ||
|  | ||
|
|
||
| #### 8.项目线上运行实例:http://blog.zhentaoo.com/ |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,88 @@ | ||
| --- | ||
| title: 事件循环 | ||
| categories: JavaScript语言专题 | ||
| date: 2016-11-01 | ||
| --- | ||
| 参考:[http://blog.csdn.net/alex8046/article/details/51914205](http://blog.csdn.net/alex8046/article/details/51914205) | ||
| 消息队列:是一个先进先出的队列,它里面存放着各种消息。(消息就是注册异步任务时添加的回调函数。) | ||
| __事件循环__:事件循环是指主线程重复从消息队列中取消息、执行的过程。 | ||
|
|
||
| 用代码表示如下: | ||
| ```js | ||
| while(true) { | ||
| var message = queue.get(); | ||
| execute(message); | ||
| } | ||
| ``` | ||
| <img src="./img/eventloop.png" width = "580" height = "350" align=center /> | ||
|
|
||
| 异步的过程 : | ||
| 1. **主线程**发起一个**异步请求** | ||
| 2. 相应的**工作线程**接收请求并告知主线程已收到(异步函数返回); | ||
| 3. 主线程可以继续执行后面的代码,同时工作线程执行异步任务; | ||
| 4. 工作线程完成工作后,**通知**主线程; | ||
| 5. 主线程收到通知后,执行一定的动作(调用回调函数)。 | ||
|
|
||
| 从生产者,消费者角度来看异步的过程: | ||
| 1. 工作线程是生产者,主线程是消费者(只有一个消费者)。 | ||
| 2. 工作线程执行异步任务,执行完成后把对应的回调函数封装成一条消息放到消息队列中; | ||
| 3. 主线程不断地从消息队列中取消息并执行,当消息队列空时主线程阻塞,直到消息队列再次非空。 | ||
|
|
||
| JS异步过程: | ||
| 1. 由于JavaScript是单线程的,因此所有任务都需要排队 | ||
| 2. 同步任务会在主线程中执行,形成一个执行栈,栈底是全局上下文,栈顶是当前执行的函数上下文 | ||
| 3. 主线程如果遇到异步任务,则把该异步任务放置在工作线程(net/fs)中,该异步任务完成后放到task queue中 | ||
| 4. 等所有同步任务执行完成后,才会执行异步任务 | ||
| 5. 主线程的event loop会循环遍历task queue,如果发现有异步任务,就会把这个异步任务对应的call back至于执行中并执行 | ||
|
|
||
| 异步模型: | ||
| 1. 同步模型:遇到网络IO等耗时较长的操作时,进程会一直等待,导致CPU空闲,整个系统资源被浪费 | ||
| 2. 多线程模型:在上述情况下,可能会同时等待多个IO请求,导致系统资源被严重浪费 | ||
| 3. 异步模型:会先把同步任务执行完,把异步任务丢到task queue中,等异步任务完成之后再执行对应的callback | ||
|
|
||
| 参考:[https://cnodejs.org/topic/57d68794cb6f605d360105bf](https://cnodejs.org/topic/57d68794cb6f605d360105bf) | ||
| 当Node.js启动时会初始化event loop, 每一个event loop都会包含按如下顺序六个循环阶段, | ||
| ```bash | ||
| ┌───────────────────────┐ | ||
| ┌─>│ timers │ | ||
| │ └──────────┬────────────┘ | ||
| │ ┌──────────┴────────────┐ | ||
| │ │ I/O callbacks │ | ||
| │ └──────────┬────────────┘ | ||
| │ ┌──────────┴────────────┐ | ||
| │ │ idle, prepare │ | ||
| │ └──────────┬────────────┘ ┌───────────────┐ | ||
| │ ┌──────────┴────────────┐ │ incoming: │ | ||
| │ │ poll │<─────┤ connections, │ | ||
| │ └──────────┬────────────┘ │ data, etc. │ | ||
| │ ┌──────────┴────────────┐ └───────────────┘ | ||
| │ │ check │ | ||
| │ └──────────┬────────────┘ | ||
| │ ┌──────────┴────────────┐ | ||
| └──┤ close callbacks │ | ||
| └───────────────────────┘ | ||
| ``` | ||
| - timers 阶段: 这个阶段执行setTimeout(callback) and setInterval(callback)预定的callback; | ||
| - I/O callbacks 阶段: 执行除了 close事件的callbacks、被timers(定时器,setTimeout、setInterval等)设定的callbacks-setImmediate()设定的callbacks之外的callbacks; | ||
| - idle, prepare 阶段: 仅node内部使用; | ||
| - poll 阶段: 获取新的I/O事件, 适当的条件下node将阻塞在这里; | ||
| - check 阶段: 执行setImmediate() 设定的callbacks; | ||
| - close callbacks 阶段: 比如socket.on(‘close’, callback)的callback会在这个阶段执行. | ||
|
|
||
|
|
||
| ```js | ||
| console.log(‘1’); | ||
|
|
||
| setImmediate(function () { | ||
| console.log(‘2’); | ||
| }); | ||
|
|
||
| setTimeout(function () { | ||
| console.log(‘3’); | ||
| },0); | ||
|
|
||
| process.nextTick(function () { | ||
| console.log(‘4’); | ||
| }); | ||
| ``` | ||
| ```1–4--2–3``` |
File renamed without changes.
File renamed without changes.
File renamed without changes.
File renamed without changes.
File renamed without changes.
File renamed without changes.
File renamed without changes.
File renamed without changes.
File renamed without changes.
File renamed without changes.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,68 @@ | ||
| --- | ||
| title: 高级爬虫--Puppeteer初探 | ||
| date: 2017-08-17 | ||
| categories: NodeJS | ||
| --- | ||
| **首先介绍Puppeteer** | ||
| - Puppeteer是一个node库,他提供了一组用来操纵Chrome的API,理论上使用它可以做任何Chrome可以做的事 | ||
| - 有点类似于PhantomJS,但Puppeteer由Chrome官方团队进行维护,前景更好 | ||
| - Puppeteer的应用场景会非常多,就爬虫领域来说,远比一般的爬虫工具功能更丰富,性能分析、自动化测试也不在话下,今天先探讨爬虫相关 | ||
| - [Puppeteer官方文档请猛戳这里](https://github.com/GoogleChrome/puppeteer/blob/master/docs/api.md#puppeteerlaunchoptions) | ||
|
|
||
| ### Puppeteer 核心功能 | ||
| 1. 利用网页生成PDF、图片 | ||
| 2. 爬取SPA应用,并生成预渲染内容(即“SSR” 服务端渲染) | ||
| 3. 可以从网站抓取内容 | ||
| 4. 自动化表单提交、UI测试、键盘输入等 | ||
| 5. 帮你创建一个最新的自动化测试环境(chrome),可以直接在此运行测试用例 | ||
| 6. 捕获站点的时间线,以便追踪你的网站,帮助分析网站性能问题 | ||
|
|
||
| ### 基本熟悉之后,接下来进行Puppeteer的爬虫教学: | ||
| 1. 运行Puppeteer | ||
| ```js | ||
| puppeteer.launch().then(async browser => { | ||
| ...... | ||
| what you want | ||
| ...... | ||
| }) | ||
| ``` | ||
|
|
||
| 2. 跳转至 [阮一峰老师的ES6博客](http://es6.ruanyifeng.com/#README) | ||
| ```js | ||
| let page = await browser.newPage(); | ||
| await page.goto('http://es6.ruanyifeng.com/#README'); | ||
| ``` | ||
|
|
||
| 3. 分析博客左侧导航栏的dom结构,并拿到所有链接的href、title信息 | ||
| ```js | ||
| let as = [...document.querySelectorAll('ol li a')]; | ||
| return as.map((a) =>{ | ||
| return { | ||
| href: a.href.trim(), | ||
| name: a.text | ||
| } | ||
| }); | ||
| ``` | ||
|
|
||
| 4. 使用Puppeteer打印当前页面的PDF | ||
| ```js | ||
| await page.pdf({path: `./es6-pdf/${aTags[0].name}.pdf`}); | ||
| ``` | ||
|
|
||
| 5. 完整代码在: https://github.com/zhentaoo/puppeteer-deep | ||
|
|
||
| 6. 项目运行 | ||
| - git clone https://github.com/zhentaoo/puppeteer-deep | ||
| - npm install (puppeteer在win下100+M、mac下70+M,请耐心等候) | ||
| - npm run es6 | ||
|
|
||
| ### 最终效果如下,不过要注意几个问题: | ||
|
|
||
| 1. 如果在page go之后马上进行pdf抓取,此时页面还未完成渲染,只能抓到loading图(如下),所以需要用timeout做点简单处理 | ||
| <img src="./img/puppeteer.png" width = "600" height = "290" align=center /> | ||
| 2. 最终爬取效果如下,PDF的尺寸、预览效果、首页重复就不做过多整理, 预览效果如下,如果想要自己处理,可以设置一下chrome尺寸,打印页数 | ||
| <img src="./img/es6-pdf.png" width = "700" height = "300" align=center /> | ||
| <img src="./img/es6.png" width = "680" height = "600" align=center /> | ||
|
|
||
|
|
||
| #### 最后声明,生成的PDF很粗糙,应该不会对阮老师产生什么影响,如有问题可以第一时间联系我.... |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,58 @@ | ||
| --- | ||
| title: 前端监控--Puppeteer终探 | ||
| date: 2017-10-14 | ||
| categories: NodeJS | ||
| --- | ||
| **先谈谈前端监控的现状** | ||
| 目前市面上的前端监控系统,多是记录资源加载时长、系统抛错、统计埋点、UV/PV... | ||
| 对开发人员来说就是嵌入监控js脚本,监控的前提是:**该监控脚本能正常加载并执行** | ||
| 那么问题就来了,**假如某个站点CDN、DNS出现异常,监控脚本完全没机会加载(更不用说运行了)** | ||
| 站点Owner可能很长时间都不知道自己的网站挂了?!监控服务形同虚设... | ||
|
|
||
| 本文提到的监控改良,便是为解决此痛点 | ||
|
|
||
| ### 改良思路 | ||
| **Q:** 假如站点DNS出现问题,请求根本打不到站点,监控脚本无法加载,要怎么应对这种情况呢? | ||
| ~~A: 人肉运维啊,找个人每天盯着,5分钟刷下页面,看网站正不正常,不就行了嘛!~~ | ||
| **A:** 咳,基本思路其实就是这样,不过把人肉运维改成Puppeteer,做个定时任务,每5分钟去跑一下监控站点,如果发现站点白屏则马上警报(短信通知),可以算是监控的最终兜底策略 | ||
|
|
||
| **系统具体设计思路,代码:https://github.com/zhentaoo/hawk-eye** | ||
| <img src ="./img/zhentaoo.png"> | ||
|
|
||
|
|
||
| ### 项目分析 | ||
| **开发时截图(Atom默认主题+ZSH)** | ||
| <img src ="./img/run.png"> | ||
|
|
||
| **1. 定时脚本 [/hawk-eye/scripts/monitor-pp.js](https://github.com/zhentaoo/hawk-eye/blob/master/scripts/monitor-pp.js)** | ||
| - 该脚本每5分钟,访问一次zhentaoo.com,稍作等待后,观察其是否渲染正常 | ||
| - 如果正常: 删除上次的正常图片,保存此次的图片,然后请求 monitor 接口 | ||
| - 如果异常: 删除上次的异常图片,保存此次的图片,然后请求 monitorerr 接口 | ||
| - 这里很难出现异常情况,于是我在每次脚本启动时,random了一个值,如果大于 > 0.7 则认为异常 | ||
|
|
||
| **2. Restful API** | ||
| 这里为了简单,我直接用了ThinkJS框架生成Restful API,大家有兴趣也可以看下使用方法,简单易上手 | ||
| - 文档: https://thinkjs.org/zh-cn/doc/3.0/rest.html#toc-b15 | ||
| - 安装2.0脚手架:`npm install -g thinkjs@2` | ||
| - 初始化项目:`thinkjs new hawk-eye` | ||
| - 创建restful api:`thinkjs controller home/monitor -r` | ||
| - 创建restful api:`thinkjs controller home/monitorerr -r` | ||
|
|
||
| **3. MongoDB** | ||
| 这里就不进行mongodb的安装教学了,如果不习惯命令行的同学,推荐使用robomongo客户端 | ||
|
|
||
| <img src ="./img/robomongo.png"> | ||
|
|
||
| **4.项目线上部署图,PM2做为Node进程的管理工具** | ||
| <img src ="./img/run-pp.png"> | ||
|
|
||
| **5.项目运行效果,监控对象行为记录** | ||
| <img src ="./img/hawk-eye.png"> | ||
|
|
||
|
|
||
|
|
||
| ### 后话 | ||
| 关于Puppeteer,也已经研究、试水了一段时间,多数应用场景也都有考虑,并在github上写了些不成熟的项目和思路 | ||
| 接下来我可能会试水其他东西,或者用它搞点事 | ||
| 希望各位看官可以结合自己的需求/业务场景,充分挖掘Puppeteer功能 | ||
| 有兴趣的话加群讨论,😄 |
File renamed without changes.
Oops, something went wrong.