
- cpython/Objects/listobject.c
- cpython/Objects/clinic/listobject.c.h
- cpython/Include/listobject.h
- cpython/Objects/listsort.txt
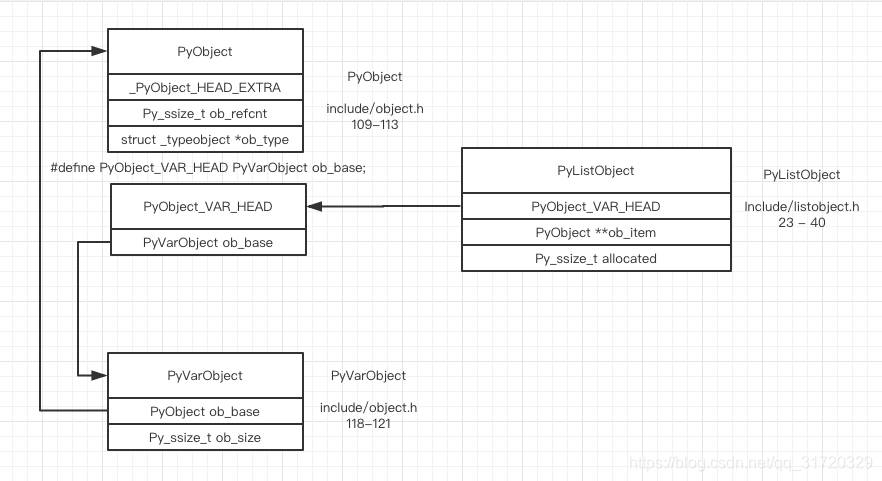
该基本类型的名称为 list, 中文翻译是列表, 但是它的实现方式和 C++ 中的 vector 更为相似
我们来初始化一个空的 list 看看
l = list()ob_size 存储了当前 list 的存储有意义的元素个数(len 操作就是从这个字段读取的), 它的类型是 Py_ssize_t, 这个类型通常情况下是 64 bit 大小的, 1 << 64 可以表示一个非常大的数字了, 通常情况下你会在碰到 ob_size 字段溢出这个问题之前先碰到 RAM 内存不足的问题

我们用 append 方法往 list 插入一些元素看看
l.append("a")ob_size 变成了 1, 并且 ob_item 会指向一个新申请的内存块大小, 它的长度是 4

l.append("b")
l.append("c")
l.append("d")现在 list 已经装满了

如果我们此时再插入一个新的元素
l.append("e")这是重新分配空间的核心代码
/* cpython/Objects/listobject.c */
/* 空间增长的规律是: 0, 4, 8, 16, 25, 35, 46, 58, 72, 88, ... */
/* 当前的: new_allocated = 5 + (5 >> 3) + 3 = 8 */
new_allocated = (size_t)newsize + (newsize >> 3) + (newsize < 9 ? 3 : 6);
你可以发现它确实是更像 C++ vector
插入操作会在 list 对象装满时触发内存的重新分配, 那删除操作呢?
>>> l.pop()
'e'
>>> l.pop()
'd'通过调用 realloc 对已有的空间进行缩小, 实际上 resize 函数会在每次调用 pop 时都会进行调用
但是 realloc 则只会在新申请的空间比当前已有的空间的一半还小的时候被调用
/* cpython/Objects/listobject.c */
/* allocated: 8, newsize: 3, 8 >= 3 && (3 >= 4?), 已经比一半还小了 */
if (allocated >= newsize && newsize >= (allocated >> 1)) {
/* 如果当前空间没有比原空间一半还小 */
assert(self->ob_item != NULL || newsize == 0);
/* 只更改 ob_size 这个字段里的值即可 */
Py_SIZE(self) = newsize;
return 0;
}
/* ... */
/* 3 + (3 >> 3) + 3 = 6 */
new_allocated = (size_t)newsize + (newsize >> 3) + (newsize < 9 ? 3 : 6);

CPython 用来对 list 对象排序的算法名称叫做 timsort, 它有一点复杂
>>> l = [5, 9, 17, 11, 10, 14, 2, 8, 12, 19, 4, 13, 3, 0, 16, 1, 6, 15, 18, 7]
>>> l.sort()我更改了一些源代码中的参数, 这样下面演示算法的时候会更方便一些, 后面会说明做了什么改动
一个叫做 MergeState 的 C 结构体会被用来辅助运行 timsort 算法

这是运行排序之前进行的一些初始化

假设 minrun 为 5, 我们后面会解释 minrun 是什么并且是怎么计算的, 现在我们先忽略一部分细节, 跑一遍算法看看

binary_sort 会用来对这些分好组的组内的元素进行排序, 这里一组元素的个数可以称为 run(minrun)
在 binary_sort 第一组后, nremaining 变为了 15, count_run 变成了 2, MergeState 中的 n 变为 1, 因为 pending 这个数组的大小是预先分配好的, pending 中的元素是没有意义的, n 表示 pending 数组中有多少个有意义的元素

在 binary_sort 第二组之后

第二组内的元素被 binary_sort 排好序了, 并且 pending 的下一个空闲的位置存储了第二组相关的信息
我们从上图可以发现, pending 在这里的作用和调用栈的 stack 类似, 每次给下一组排完序之后, 这组相关的信息就会被压入这个栈中, 每次压入后, 一个名为 merge_collapse 的函数都会被调用
/* cpython/Objects/listobject.c */
/* 检查 stack 中的每一个 run, 在必要的时候合并相邻的 run 直到以下的条件都满足为止
*
* 1. len[-3] > len[-2] + len[-1]
* 2. len[-2] > len[-1]
*/
static int
merge_collapse(MergeState *ms)
{
struct s_slice *p = ms->pending;
assert(ms);
while (ms->n > 1) {
Py_ssize_t n = ms->n - 2;
if ((n > 0 && p[n-1].len <= p[n].len + p[n+1].len) ||
/* case 1:
pending[0]: [---------------------------]
pending[1]: [-----------------------] (n)
pending[2]: [-----------------------]
... (ms->n)
len(pending[0]) <= len(pending[1]) + len(pending[2])
*/
(n > 1 && p[n-2].len <= p[n-1].len + p[n].len)) {
/* case 2:
...
pending[3]: [-----------------------------------------------------------------]
pending[4]: [-----------------------------------------------------------------]
pending[5]: [-----------------------] (n)
pending[6]: [-----------------------]
pending[7]: [-----------------------] (ms->n)
len(pending[3]) <= len(pending[4]) + len(pending[5])
*/
if (p[n-1].len < p[n+1].len)
/* pending[0]: [-----------------] (new_n)
pending[1]: [-----------------------] (n)
pending[2]: [-----------------------]
*/
--n;
if (merge_at(ms, n) < 0)
return -1;
}
else if (p[n].len <= p[n+1].len) {
/* case 3:
pending[0]: [--------------] (n)
pending[1]: [--------------]
*/
if (merge_at(ms, n) < 0)
return -1;
}
else
break;
}
return 0;
}当前检查的时间会进到 case 3, merge_at 会合并 stack 中第 i 和 i+1 个数组
merge_at 包含了两部分, 一部分是 merge_sort, 另一部分是 galloping mode

在 merge_collapse 之后, 前两个 runs 被合并了, 并且 pending 的长度变回了 1

在 binary_sort 下一个 run 之后

此时 merge_collapse 不会合并任何的 run, 因为没有达到代码中的判定条件
在 binary_sort 最后一个 run 之后

此时达到了 case 1 的判定条件, 最后两个 run 会被合并

在 merge_collapse 中的 while 循环中, 会继续进入到 case 3, 并且再次进行合并, 在这次合并之后我们就完成了 timsort 排序算法, 此时 list 中所有的 ob_item 对象都是排好序的了

如果我们合并的是如下的两个数组

对于左边的数组, 我们可以用二叉搜索找到最大的并且小于右边第一个元素的位置, 把从开头到这个位置的元素一次性复制到新的数组中, 而不是一个一个的进行合并

同样的方式也可以从右到左进行

更多详情请参考 listsort.txt
在调用 binary_sort 这个函数之前, 一个叫做 count_run 会被用来计算出从下标0开始的最长的递增/递减的子数组的长度

计算之后, binary_sort 可以从下标 2 开始处理, 一直到下标 4 结束, 因为前面两个已经排好序了
在 start 之前的子数组已经是排好序的了, 我们只用处理 start 到最后一个元素

首先我们用一个名为 pivot 的变量存储 start 当前的值, 之后在前面排好序的子数组中进行二叉搜索, 找到第一个大于 pivot 的元素
do {
p = l + ((r - l) >> 1);
IFLT(pivot, *p)
r = p;
else
l = p+1;
} while (l < r);之后我们把 l 到 start 的每一个元素都往后移一格, 移完后把 start 这个位置的元素值设置为 pivot 的值

我们再做一次二叉搜索, 这次搜索结果为下标为 2 的元素, 我们再次把选中的下标到 start 的元素往前移一格

并把选中的下标的值设置为 pivot 的值

我们还需要再做最后一次二叉搜索

搜索结果为下标为 2, 在把 l 到 start 的每个值后移一格后

并把选中的下标(start)的值设置为 pivot 的值, 我们就完成了本次 binary_sort 算法

实际上 minrun 的值是通过下面这个函数进行计算的, 如果当前剩余未排序的长度小于 64, 则返回并用 binary_sort 进行分组内元素排序, 不然的话就一直对当前的剩余长度减半, 直到小于 64 为止, 返回并进行排序
上面的演示中我更改了这个阈值, 调小这个值使得图片能展示出完整的数组
static Py_ssize_t
merge_compute_minrun(Py_ssize_t n)
{
Py_ssize_t r = 0; /* becomes 1 if any 1 bits are shifted off */
assert(n >= 0);
while (n >= 64) {
r |= n & 1;
n >>= 1;
}
return n + r;
}timsort 的时间复杂度如下

#ifndef PyList_MAXFREELIST
#define PyList_MAXFREELIST 80
#endif
static PyListObject *free_list[PyList_MAXFREELIST];
static int numfree = 0;一个解释器进程会有一个叫做 free_list 的全局变量

如果我们创建一个新的 list 对象, 创建新对象的内存分配过程会用到 CPython 的 内存管理机制
a = list()
del alist 类型的析构函数会把这个对象存储到 free_list 中(如果 free_list 有位置的话)

下一次你创建一个新的 list 对象时, 会优先检查 free_list 中是否有可用的对象, 如果有的话则从 free_list 取, 如果没有的话, 再从 CPython 的 内存管理机制 申请
b = list()
把空闲的 list 对象缓存到 free_list 中有如下好处
- 提高性能
- 减小内存碎片