带资进组(17组)|中软国际实习实训
本科生实训报告
实训单位 中软国际
组 长 张家冉
组 员 张怡桢
组 员 吴祎璠
组 员 张若迟
专 业 软件工程
年 级 2020级本科生
2022年8月
目录
[第一章 团队介绍 1](#第一章-团队介绍)
[1.1 团队成员介绍 1](#团队成员介绍)
[1.2 团队成员工作重点 1](#团队成员工作重点)
[第二章 系统需求分析 2](#第二章-系统需求分析)
[2.1 引言 2](#引言)
[2.2 项目概述 3](#项目概述)
[2.3 系统描述 4](#系统描述)
[2.4 产品介绍 5](#产品介绍)
[第三章 系统概要设计 5](#第三章-系统概要设计)
[3.1 概要设计 5](#概要设计)
[3.2 架构设计 6](#架构设计)
[第四章 系统详细设计 7](#第四章-系统详细设计)
[4.1 软件详细设计流程说明 7](#软件详细设计流程说明)
[4.2 主要模块设计 8](#主要模块设计)
[第五章 系统实现 9](#第五章-系统实现)
[5.1 yolov5口罩模型 9](#yolov5口罩模型)
[5.2 mtcnn口罩模型 24](#mtcnn口罩模型)
[5.3 特效工具类模块 30](#特效工具类模块)
[5.4 flask+vue前后端分离 31](#flaskvue前后端分离)
[5.5 前端模块 31](#前端模块)
[第六章 系统安装手册 33](#第六章-系统安装手册)
[6.1 软件平台安装说明 33](#软件平台安装说明)
[6.2 Python虚拟环境软件包安装说明 34](#python虚拟环境软件包安装说明)
[6.3 vue3环境搭建说明 35](#vue3环境搭建说明)
[第七章 系统用户手册 37](#第七章-系统用户手册)
[7.1 引言 37](#引言-1)
[7.2 用途 37](#用途)
[7.3 运行需求 37](#运行需求)
[7.4 其它需求 37](#其它需求)
[7.5 输入 37](#输入)
[7.6 输出 38](#输出)
[7.7 基本的数据流程和处理流程 38](#基本的数据流程和处理流程)
[7.8 安全与保密要求 38](#安全与保密要求)
[第八章 项目总结报告 38](#第八章-项目总结报告)
[8.1 个人项目总结报告 38](#个人项目总结报告)
张家冉:20级本科生,担任开发工程师,测试工程师,项目经理
张怡桢:20级本科生,担任软件工程师,测试工程师,开发经理
吴祎璠:20级本科生,担任前端工程师
张若迟:20级本科生,担任开发工程师,测试工程师,质量保障工程师
工作简介:负责mtcnn部分图片预处理、mtcnn与mobilenet模型的构建,负责特效部分的实现
详细介绍:搭建mtcnn和mobilenet模型,实现通过mtcnn选择出人脸区域,再通过mobilenet检测是否佩戴口罩。负责并实现给一个动态和静态的人脸添加特效,将添加特效的功能封装成一个工具类,以便后续与口罩识别模块的整合。
工作简介:负责mobilenet模型的训练与优化,负责前后端分离部分,负责特效强化整合,负责整合整个项目。
详细介绍:使用Mtcnn模型训练口罩识别项目,训练数据并调参达到较好的运行效果,负责并实现特效强化整合进人脸识别,负责并实现flask后端搭建与视频流前后端传输部分,实现两个后端与一个前端的连接与分离,整合整个项目。同时负责整个项目架构图,流程图等的制作与规划攥写。
工作简介:负责项目前端部分,协助完成项目前后端整合。
详细介绍:使用HTML+CSS+JS+VUE3完成项目前端部分的编写,使网站能完成用户登录、小组成员展示、菜单实现页面跳转、按钮实现页面跳转、口罩识别效果展示等功能,并对页面进行美化。
工作简介:负责Yolov5模型的训练与优化,负责特效强化整合与项目运行测试工作。
详细介绍:使用Yolov5模型训练口罩识别项目,训练数据并调参达到较好的运行效果,实现特效强化整合进入口罩佩戴识别,实现Yolov5项目在flask端的部署供前端负责人进行项目整合时的调用,对项目进行整体性测试,检测项目运行状况,保证项目质量,确保项目可靠运行。
随着新型冠状病毒疫情在全球持续蔓延,疫情常态化防控情况下,戴口罩可以阻挡空气和飞沫中的细菌、病毒,是预防呼吸道传染病最重要的措施。出入各种公众场所,我们都需要戴上口罩来防疫。在商场,超市,医院等人流量大的地方,我们总会看见有工作人员在对不戴口罩的人进行劝诫,为了节省人力资源,结合深度学习以及人脸识别,目标检测等相关理论知识,我们小组以“动态场景下口罩佩戴监测与特效提醒系统”为研究课题,开展了这次实训的项目工作。我们想要实现动态场景下人员流动时,摄像头自动识别人脸是否戴口罩并做出相应的判断,对于没有戴口罩的人,我们实现了特效强化的功能,提醒其戴上口罩。这项工作对于公共场合管理具有现实意义与一定的功能价值。
本项目从规范的开发流程角度去开发口罩识别平台,选择面向对象的开发方法,以结构化程序设计为基础。首先进行平台的实用分析,在明确用户需求的基础上进行概要设计和详细设计。此文档主要对整个项目的开发做规划和任务的分工,同时说明在开发过程中的注意事项。其次说明项目的开发周期、限定日期、进度安排和项目预算,给出项目的分工安排让项目各模块负责人都能对模块有详细的开发规划,最终达到让组内成员在技术能力和工程规范性上都能有所收获。
“动态场景下口罩佩戴监测与特效提醒系统”面向的用户类群主要是公共场合的管理人员,适用的场景是进出人口流量大的超市,商场,店铺,餐厅,医院,学校等公共场合门口,方便了管理人员对于人们佩戴口罩的管理,同时规范了疫情常态化下人们在公众场合戴口罩的行为。
a.实训过程中提供的需求档中引用的文件、资料
b.Vue官方文档[https://vuejs.bootcss.com/guide/\]
c. Flask 官方文档[https://flask.palletsprojects.com/en/2.2.x/\]
d. Yolov5官方文档[https://github.com/ultralytics/yolov5\]
e. MTCNN(中科院深圳先进技术研究院的乔宇老师团队)
论文地址[https://arxiv.org/ftp/arxiv/papers/1604/1604.02878.pdf\]
code地址[https://github.com/kpzhang93/MTCNN_face_detection_alignment\]2
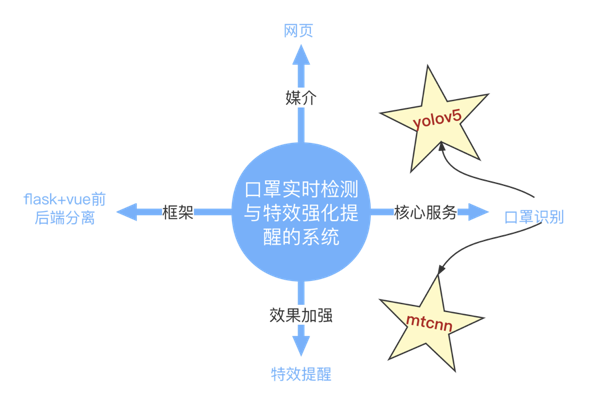
本项目以Flask+Vue前后端分离为框架,训练了两个口罩识别模型(Yolov5,Mtcnn)提供后端的服务,实现动态场景下口罩实时检测与特效强化提醒的功能。
-
对公共场所人流量观察,对入口处监督口罩是否配戴的这个流程进行观察
-
对网上的口罩佩戴图与各种图片进行爬取与收集
-
调查其它相关网站的数据集,分析其可用性
-
根据调研结果,统一处理,确定新系统的改进之处,建立模型
| 功能名称 | 实现效果 |
|---|---|
| Yolov5口罩识别 | 在动态场景下监测行人是否佩戴口罩 |
| Mtcnn+MobileNet口罩识别 | 在动态场景下监测行人是否佩戴口罩 |
| 特效提醒 | 对没有带口罩的人使用特效进行强化提醒 |
| 网页平台监测 | 在网页上可以实现实时检测功能 |
| 前端功能 | 前端实现登陆以及页面设计 |
| 模块名称 | 包含功能 |
|---|---|
| Yolov5模块 | 在动态场景下使用yolov5模型监测行人是否佩戴口罩 |
| Mtcnn+MobileNet模块 | 在动态场景下使用Mtcnn+MobileNet模型监测行人是否佩戴口罩 |
| 特效模块 | 对没有带口罩的人使用特效进行强化提醒,加入贴纸的特效 |
| 网页监测模块 | 在网页上可以实现实时检测功能,可以看到行人是否佩戴口罩的实时画面 |
| 前端设计模块 | 前端实现登陆、页面设计、页面跳转 |
实现动态场景下口罩实时检测与特效强化提醒的系统,以网页展示为媒介,以两种深度算法为核心,以flask+vue前后端分离为框架。
本产品适用于进出口人流量大,需要监督人员是否佩戴口罩的场所,比如,机场,医院,商场等的出入口。
本产品以web界面为展示的平台,可以在入口设置摄像头,在监控室内监控进出入人员佩戴口罩的情况,方便公共场合的管理。
产品可以进行登陆操作,可以据此设置管理员等,实现出入口口罩检测的自动化与智能化,同时UI界面好看且检测模型多样快速。
编写本设计说明书是为了更有效地指导项目的开发和便于客户的理解,规定设计中的一些问题、数据的定义方式和解决办法,使得项目进展可以顺利进行和软件能够得到有效地利用。
本说明书的预期读者为用户(普通用户、管理员等)、系统设计员以及其他开发人员和相关审核监测人员。
1) 方案论证。
确定论证内容(可能会影响本软件系统整体方案的关键点)、如果有需要论证的内容则通过正式的评价过程完成方案论证、形成初步方案、对方案确定中的潜在问题作为提交为项目风险加以正式管理。
2) 确定构架。
选择设计方法、识别关键技术、确定系统构架(由下一层的哪些组件组成)
3) 分配任务。
根据确定的系统的构架,确定组件之间的关键协作和关键接口,必要时识别可贡献的标准组件。
本文档为动态场景下口罩实时检测与特效强化提醒的系统的设计说明书,具体说明了软件设计中所注意的限制条件,功能目标、涉及约束等,本文还给出了全部的接口设计说明,以及系统的概要设计。
1)开发技术限制
前端采用vue技术进行设计,后端使用flask进行设计,深度学习模型采用yolov5与mtcnn。
2)工具约束
采用tensorflow、VS code,PyCharm,WebStorm等工具开发
3)设计约束
数据集的影响因素较多,人脸识别的准确率问题,以及目标检测的算法。
为了解决软件系统复杂度带来的问题。
其终极目标是:用最小的人力成本来满足构建和维护系统的需求。
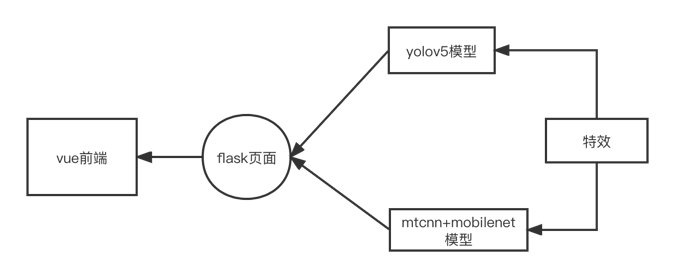
该应用的简单结构如上图所示,该应用具有两个后端以及一个前端web界面。
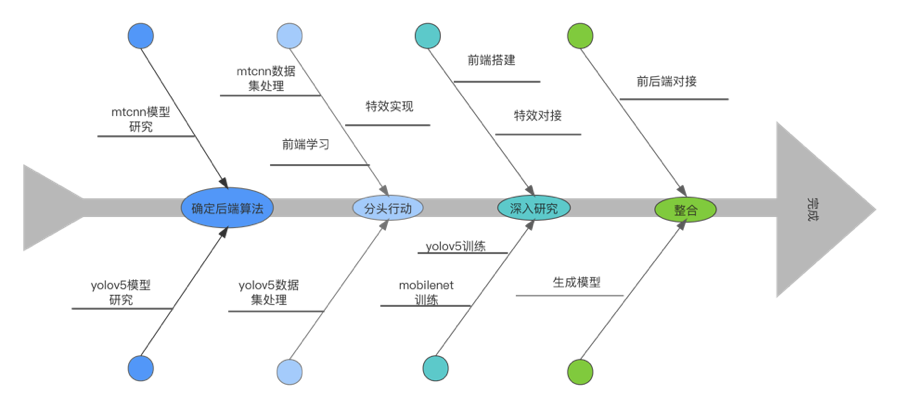
先从后端下手,主要抓住深度学习的各个步骤,分别从yolov5与mtcnn+mobilenet下手研究模型算法,针对其特征收集训练集,搭建模型而后实现口罩识别的初步模型,使用opencv处理的特效封装并整合进入两个口罩识别的模型,前端则使用vue先搭建一个web界面,实现登陆,页面跳转等功能,再使用flask连接前后端。
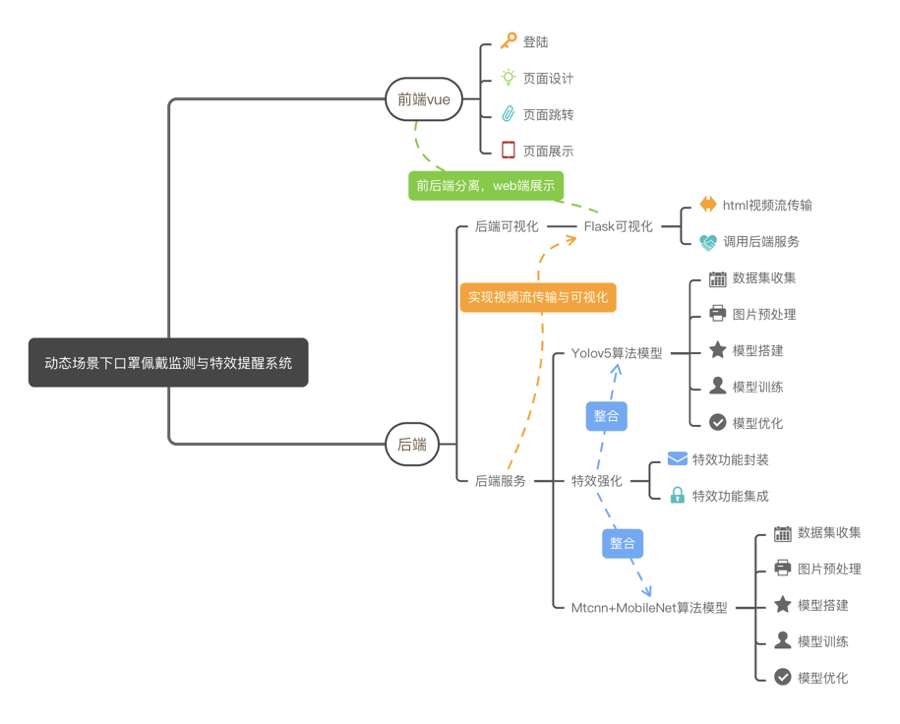
-
前端vue
-
登录页面
-
实现动态背景
-
实现登录功能
-
-
主页面
-
项目主题展示
-
小组成员展示
-
-
用户页面&关于页面
- 静态页面展示
-
开始体验页面
-
Mtcnn模型进行口罩检测的页面跳转
-
YOLOv5模型进行口罩检测的页面跳转
-
-
通用部分
-
顶部菜单栏
-
底部footer
-
按钮Button
-
-
-
后端
- 后端可视化|Flask可视化
html视频流传输;调用后端服务
-
后端服务
- Yolov5算法模型
数据集收集;图片预处理;模型搭建;模型训练;模型优化
- 特效强化
特效功能封装;特效功能集成
- Mtcnn+MobileNet算法模型
数据集收集;图片预处理;模型搭建;模型训练;模型优化
数据集总共包含图片1999张,经makedata.py按照4:1的比例划分为训练集和测试集,其中训练集含图片1597张,测试集含图片402张。训练集中mask图片共807张,测试集中mask图片共192张,命名上戴口罩图片含有test前缀和序号的后缀,而未佩戴口罩的图片命名前缀为人物当前动作,图片分辨率不做具体要求。示例如下:


yolov5模型只接收txt格式的特征标签,项目中使用的数据集已经打好标签,若要处理不含标签的图片,可安装python中的labeling包进行相关处理,此处不多做赘述。
yolov5已经提供了完整的神经网络模型,无需手动搭建,在此简述本项目使用的yolov5s模型结构。
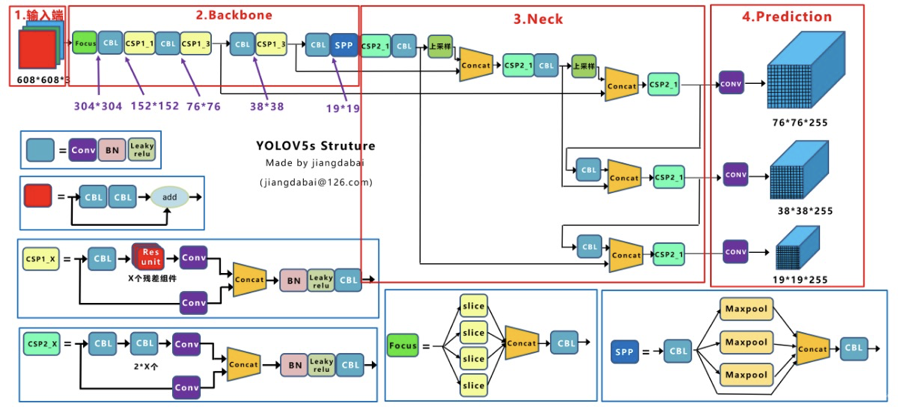
yolov5s模型结构图如上图所示,共分为输入端、Backbone、Neck、Prediction四个部分
①输入端
Mosaic数据增强
Yolov5的输入端采用了Mosaic数据增强的方式,Mosaic数据增强参考2019年提出的CutMix数据增强方式,将4张图片通过随机缩放、随机裁剪、随机排布的方式进行拼接。
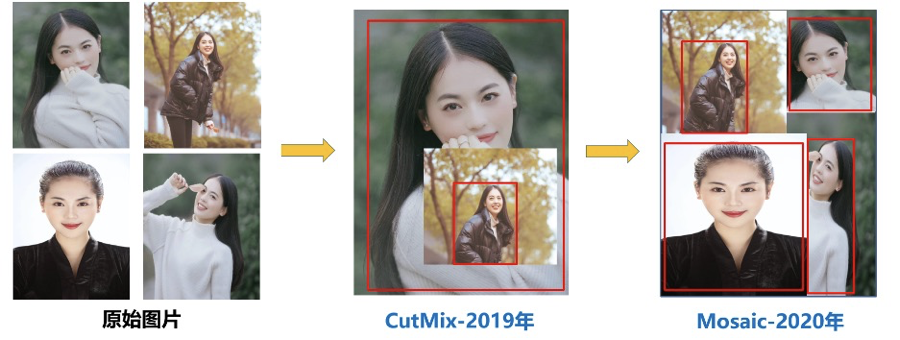
使用Mosaic数据增强的优点如下:
-
丰富数据集:随机使用4张图片,随机缩放,再随机分布进行拼接,大大丰富了检测数据集,特别是随机缩放增加了很多小目标,让网络的鲁棒性更好。
-
减小GPU训练压力:Mosaic增强训练时,可以直接计算4张图片的数据,使得Mini-batch大小并不需要很大,一个GPU就可以达到比较好的效果。
自适应锚框计算
Yolo算法对不同的数据集都会有初始设定长宽的锚框。在网络训练中,网络在初始锚框的基础上输出预测框,进而和真实框groundtruth进行比对,计算两者差距,再反向更新,迭代网络参数。如Yolov5在Coco数据集上初始设定的锚框:

Yolov5将此功能嵌入代码中,每次训练时,自适应的计算不同训练集中的最佳锚框值。
自适应图片缩放
在常见目标检测算法中,不同的图片长宽都不相同,因此常用的方式是将原始图片统一缩放到一个标准尺寸,再送入检测网络中。
比如Yolo算法中常用416×416,608×608等尺寸,比如对下面800*600的图像进行变换。

但在缩放填充后,两端的黑边大小都不同,而如果填充的比较多,则存在信息冗余,影响推理速度。
因此Yolov5代码中对此进行了改进,作者在Yolov5代码中datasets.py的letterbox函数中进行了修改,对原始图像自适应的添加最少的黑边。

图像高度上两端的黑边变少了,在推理时,计算量也会减少,即目标检测速度会得到提升。
计算步骤如下:
- 计算缩放比例
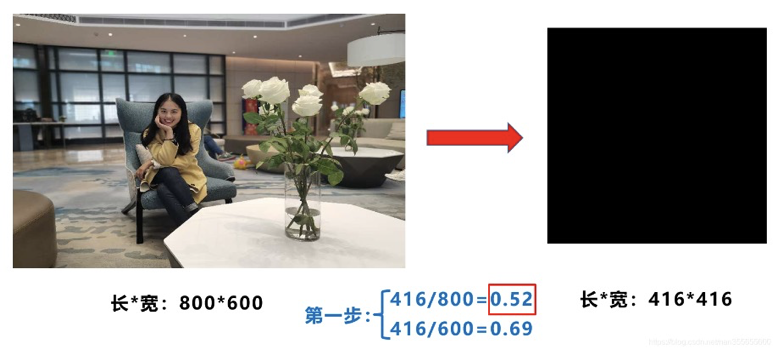
原始缩放尺寸是416×416,都除以原始图像的尺寸后,可以得到0.52,和0.69两个缩放系数,选择小的缩放系数0.52。
- 计算缩放后尺寸
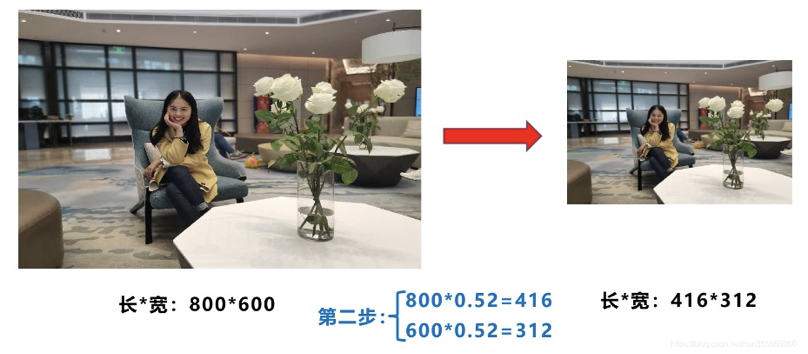
原始图片的长宽都乘以最小的缩放系数0.52,宽变成了416,而高变成了312。
- 计算黑边填充数值
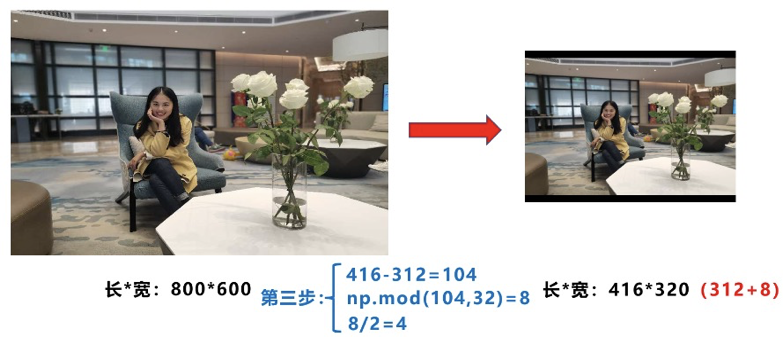
将416-312=104,得到原本需要填充的高度。再采用numpy中np.mod取余数的方式,得到8个像素,再除以2,即得到图片高度两端需要填充的数值。
注意:模型训练时没有使用缩减黑边的方式,只在模型推理时使用,提高目标检测的速度。
②Backbone
- Focus结构
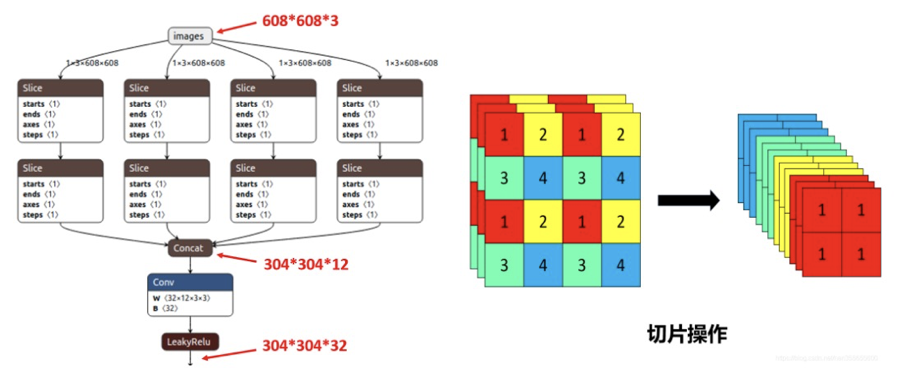
在Yolov5s中,原始608×608×3的图像输入Focus结构,采用切片操作,先变成304×304×12的特征图,再经过一次32个卷积核的卷积操作,最终变成304×304×32的特征图。
- CSP结构
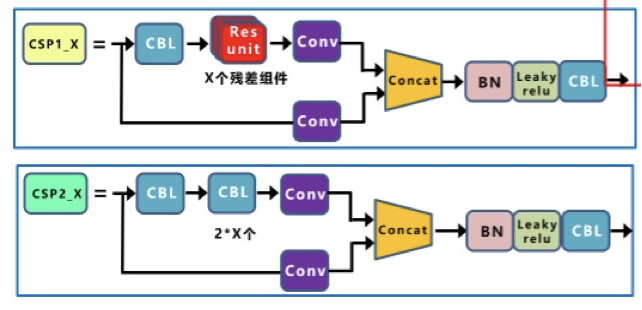
CSP结构是在Yolov4中,借鉴2019年CSPNet的经验产生的Backbone结构,每个CSP模块前面的卷积核的大小都是3×3,步长为2,因此可以起到下采样的作用,在网络中采用Leaky_relu激活函数。
而在Yolov5s中设计了两种CSP结构,CSP1_X结构应用于Backbone主干网络,另一种CSP2_X结构则应用于Neck中。
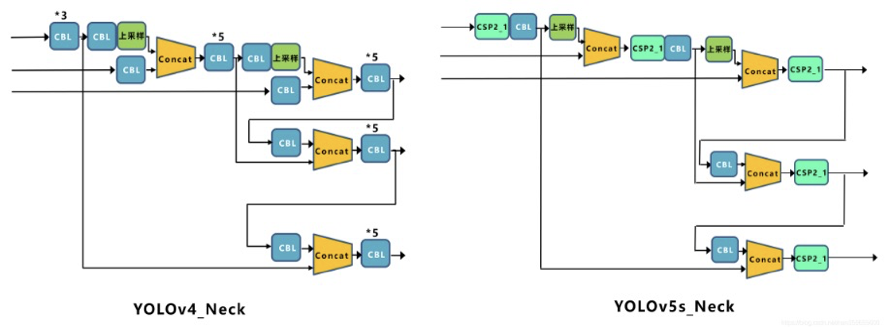
③Neck
Yolov5的Neck部分采用FPN+PAN的结构
FPN:
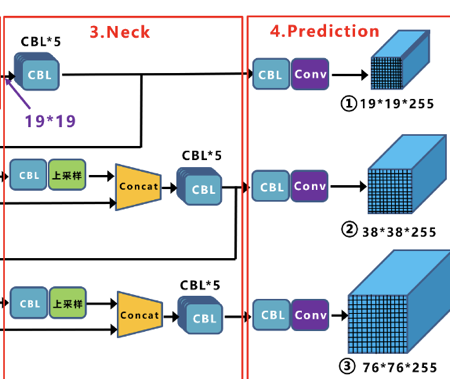
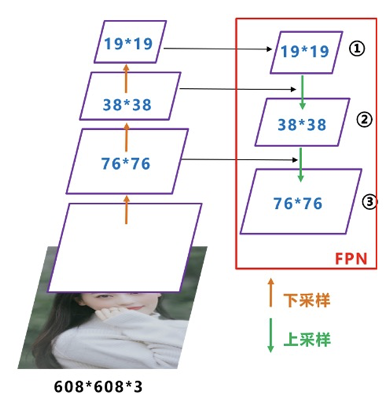
如图所示,FPN是自顶向下的,将高层的特征信息通过上采样的方式进行传递融合,得到进行预测的特征图。
PAN:
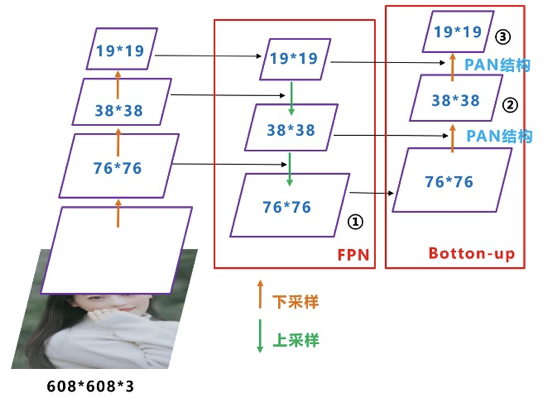
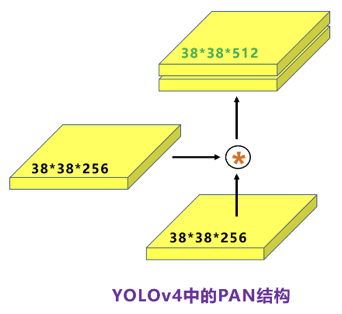
在FPN层的后面还添加了一个自底向上的特征金字塔,其中包含两个PAN结构,这样结合操作,FPN层自顶向下传达强语义特征,而特征金字塔则自底向上传达强定位特征,从不同的主干层对不同的检测层进行特征聚合。FPN层只使用最后的一个76×76特征图①,而经过两次PAN结构,输出预测的特征图②和③。
在Yolov5的Neck结构中,采用借鉴CSPNet设计的CSP2结构,加强网络特征融合的能力。
④输出端
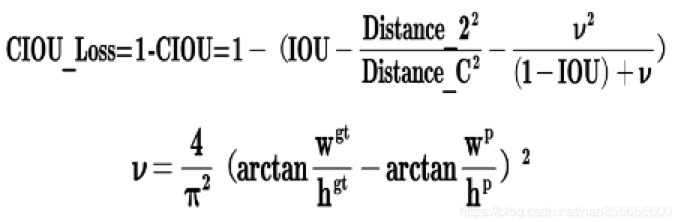
Yolov5采用CIOU_Loss做Bounding box的损失函数。

CIOU_Loss和DIOU_Loss前面的公式都是一样的,不过在此基础上还增加了一个影响因子,将预测框和目标框的长宽比都考虑了进去。其中v是衡量长宽比一致性的参数,定义为:
在目标检测的后处理过程中,针对很多目标框的筛选,通常需要nms操作。
Yolov4在DIOU_Loss的基础上采用DIOU_nms的方式,而Yolov5中仍然采用加权nms的方式。
可以看出,采用DIOU_nms,下方中间箭头的黄色部分,原本被遮挡的摩托车也可以检出。

在同样的参数情况下,将nms中IOU修改成DIOU_nms。对于一些遮挡重叠的目标,确实会有一些改进。
比如下面黄色箭头部分,原本两个人重叠的部分,在参数和普通的IOU_nms一致的情况下,修改成DIOU_nms,可以将两个目标检出。

最后附上yolov5s模型完整结构图,以供参考(图片过长,请点击下方链接查看!)
20200729111212853.png (2222×21178) (csdnimg.cn)
yolov5模型训练操作比较简单,分为以下步骤
①配置data/scripts/mask_recognize.yaml
复制该目录下的coco128.yaml文件,重命名并修改数据集路径、检测标签数量和标签名称,将此文件作为训练参数文件。
②配置models/mask_recognize.yaml
项目使用Yolov5s模型进行训练,复制一份yolov5s.yaml文件到目录下,重命名并修改检测类别数量为2。
③下载初始权重文件
前往yolov5官网下载yolov5s模型的初始权重文件yolov5s.pt,放入weights文件夹。
④配置训练初始设置
进入train.py文件,修改图中所示的相关参数。
运行train.py,开始模型训练。
训练完成后可在runs/train/exp/weights中看到best.pt和last.pt两个权重文件,模型预测使用best.pt
训练过程的相关图像如下:
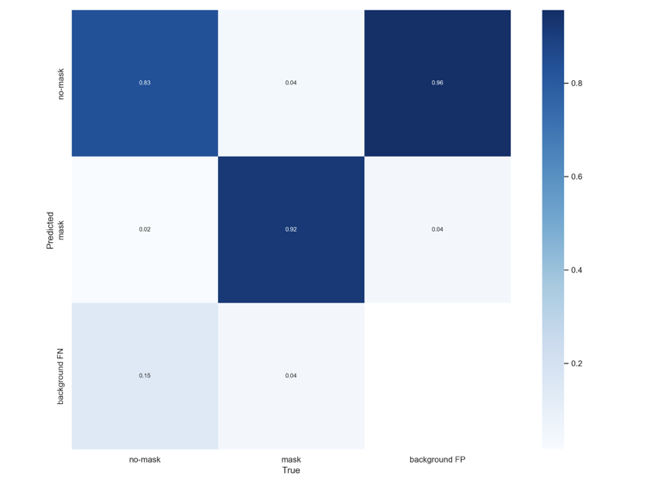
混淆矩阵
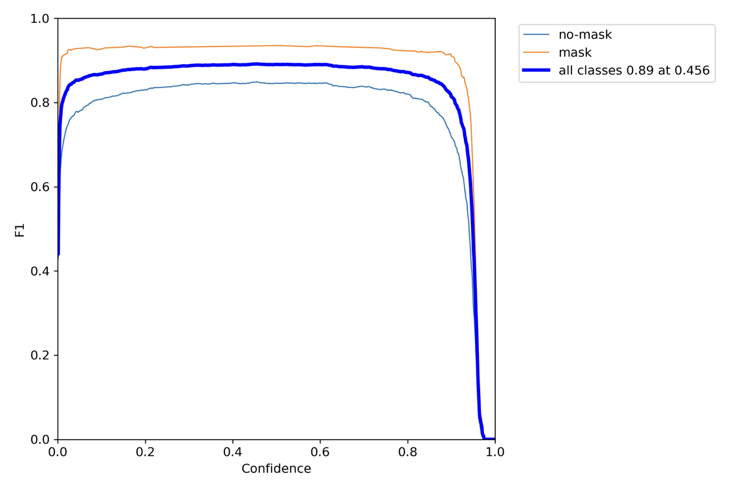
F1-curve
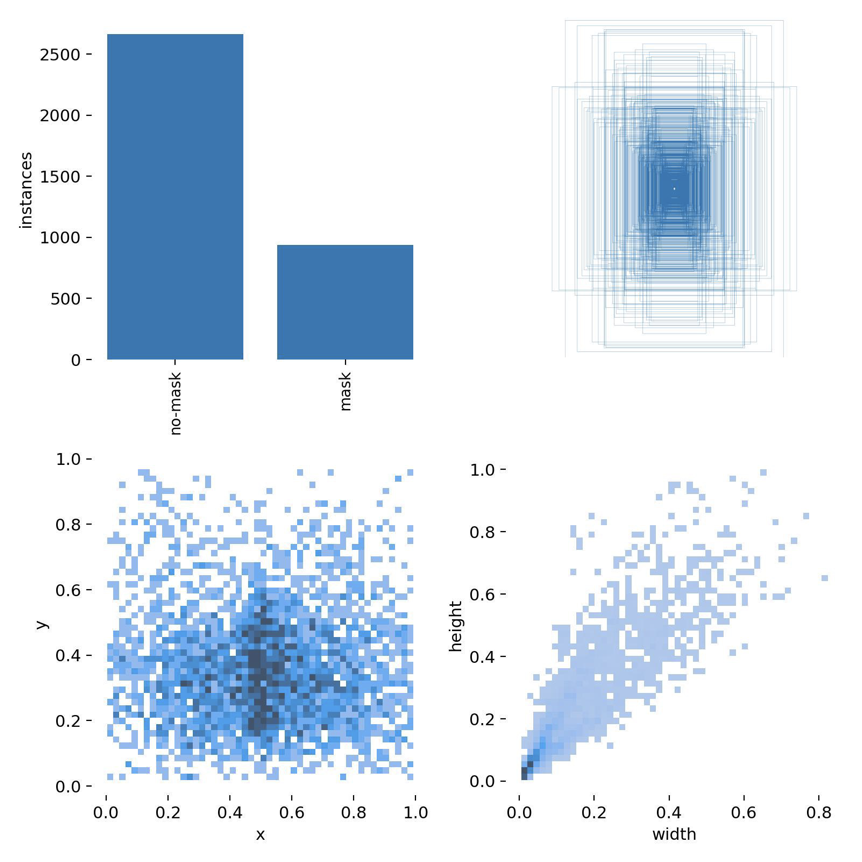
labels
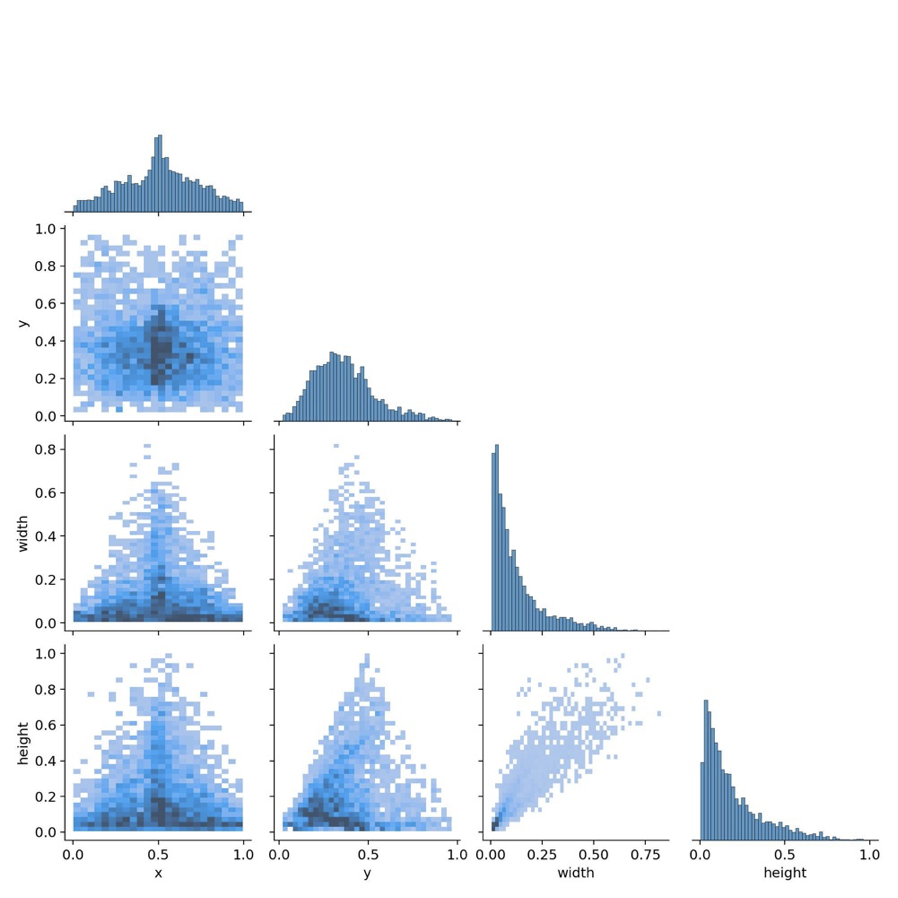
labels_correlogram
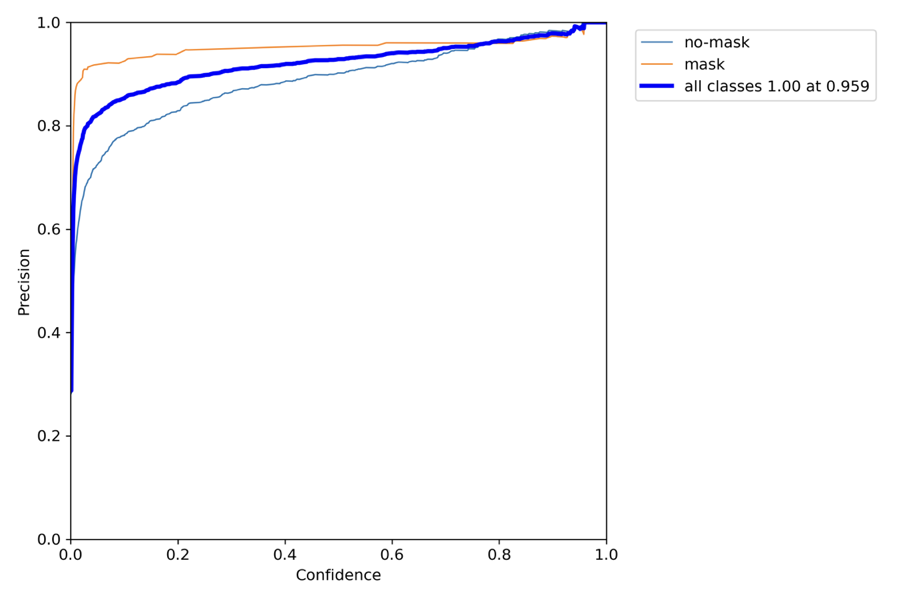
P_curve
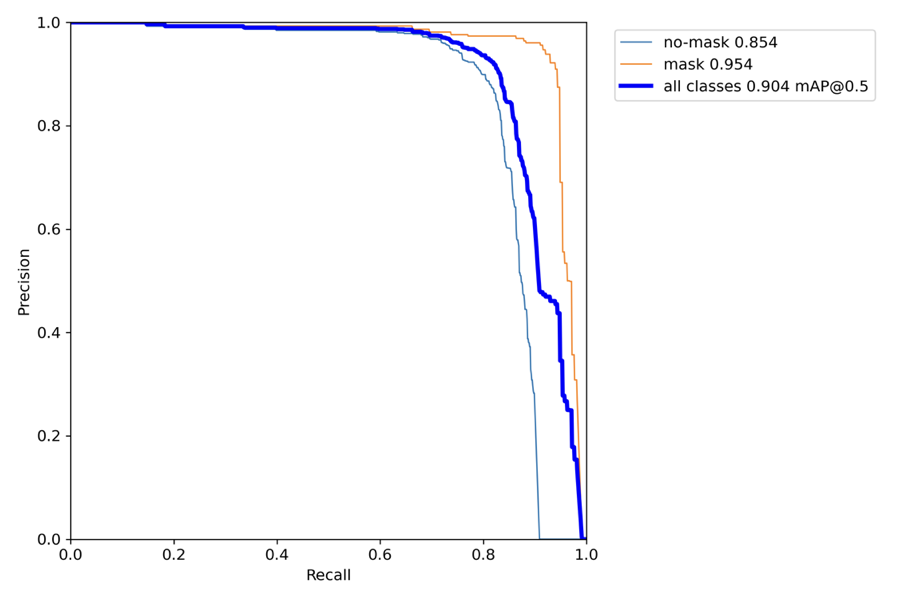
PR_curve
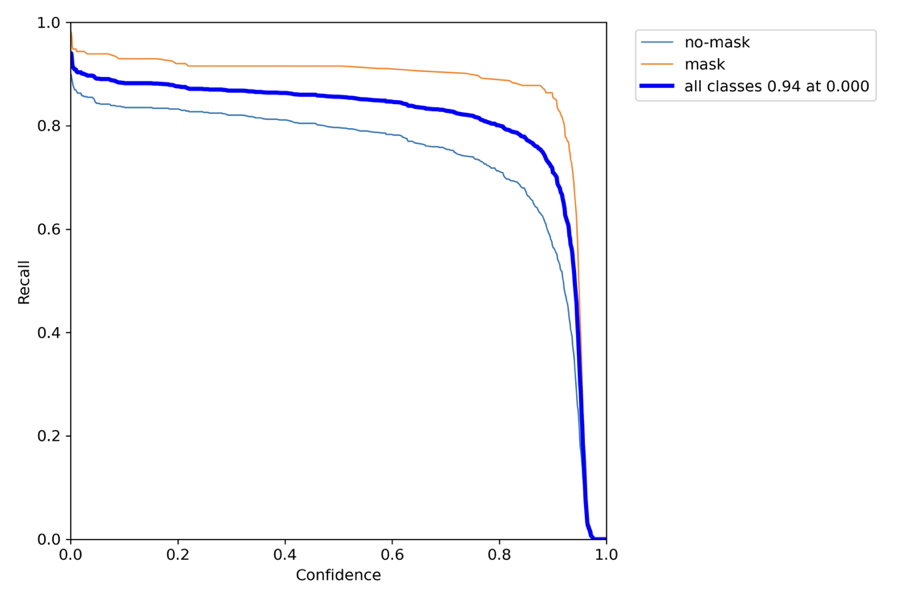
R_curve
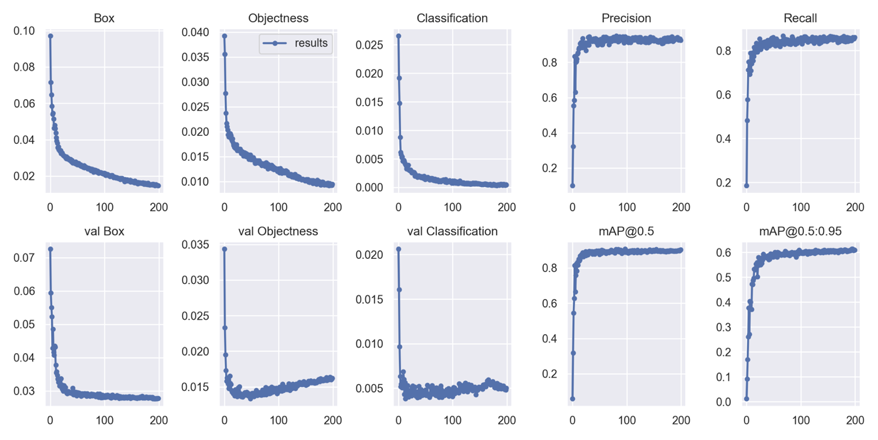
训练模型在测试集上的运行结果:

可见模型对于口罩佩戴的检测具有比较好的准确率
数据集包含mask图片313张,nomask图片443张。首先将训练图片存放在back-end/data/image/train文件夹下,图片的命名形式为图片中人戴口罩了则命名为mask_x.jpg,没有佩戴口罩则命名为nomask_x.jpg,利用图片的名字就可以对图片的类型进行判断,每一张图片的大小为Mobilenet模型输入的大小160*160。具体如下所示,下面的图片都是经过人脸对齐了的:

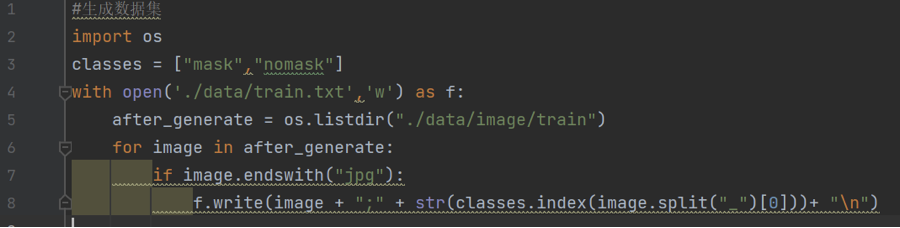
利用Gnerate_TrainTxT.py生成的train.txt, 可以看到训练集中的每张训练图片之间以行隔开,每一行代表一张训练图片,每一行的“ ; ”前面是我们事先命名图片的名字,“ ; ”后面是指这张图片所属的标签, mask的标签是:0,nomask的标签是:1 。训练的时候就会读取train.txt的每一行,获得每一张图片和其所属的标签。

mtcnn模型总体可分为P-Net、R-Net、和O-Net三层网络结构。
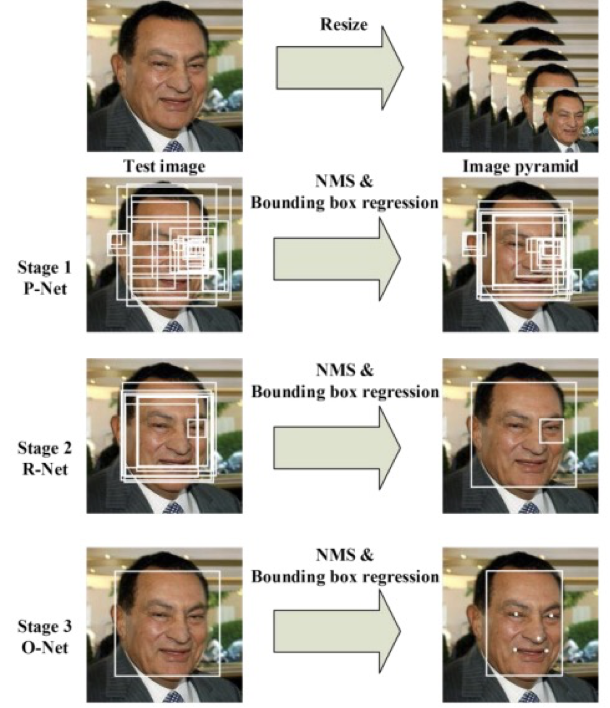
如上图所示,主要流程为:
①构建图像金字塔
首先将图像进行不同尺度的变换,构建图像金字塔,以适应不同大小的人脸的进行检测。
构建方式是通过不同的缩放系数factor对图片进行缩放,每次缩小为原来的factor大小。
示意图为:
②Pnet
Pnet基本的构造是一个全卷积网络。对上一步构建完成的图像金字塔,通过一个FCN进行初步特征提取与标定边框。

在完成初步提取后,还需要进行Bounding-Box Regression调整窗口与NMS进行大部分窗口的过滤。
Pnet有两个输出,classifier用于判断这个网格点上的框的可信度,bbox_regress表示框的位置。
bbox_regress并不代表这个框在图片上的真实位置,如果需要将bbox_regress映射到真实图像上,还需要进行一次解码过程。
解码过程利用detect_face_12net函数实现,其实现步骤如下:
-
判断哪些网格点的置信度较高,即该网格点内存在人脸。
-
记录该网格点的x,y轴。
-
利用函数计算bb1和bb2,分别代表图中框的左上角基点和右下角基点,二者之间差了11个像素,堆叠得到boundingbox 。
-
利用bbox_regress计算解码结果,解码公式为boundingbox = boundingbox + offset*12.0*scale。
③Rnet
Rnet基本的构造是一个卷积神经网络,相对于第一层的P-Net来说,增加了一个全连接层,因此对于输入数据的筛选会更加严格。在图片经过P-Net后,会留下许多预测窗口,将所有的预测窗口送入R-Net,这个网络会滤除大量效果比较差的候选框。
实现的示意图为:

最后对选定的候选框进行Bounding-Box Regression和NMS进一步优化预测结果。
Rnet有两个输出,classifier用于判断这个网格点上的框的可信度,bbox_regress表示框的位置。
bbox_regress并不代表这个框在图片上的真实位置,如果需要将bbox_regress映射到真实图像上,还需要进行一次解码过程。(具体参考函数filter_face_24net)
④Onet
Onet基本结构是一个较为复杂的卷积神经网络,相对于R-Net来说多了一个卷积层。O-Net的效果与R-Net的区别在于这一层结构会通过更多的监督来识别面部的区域,而且会对人的面部特征点进行回归,最终输出五个人脸面部特征点。
实现图片示意图如下:

最后对选定的候选框进行Bounding-Box Regression和NMS进一步优化预测结果。
Onet有三个输出,classifier用于判断这个网格点上的框的可信度,bbox_regress表示框的位置,landmark_regress表示脸上的五个标志点
bbox_regress并不代表这个框在图片上的真实位置,如果需要将bbox_regress映射到真实图像上,还需要进行一次解码过程。(具体参考函数filter_face_48net)
5.2.2.2 Mobilenet
在检测到人脸之后,再利用mobilent检测人脸是否佩戴口罩

MobileNet的网络结构如表1所示。首先是一个3x3的标准卷积,然后后面就是堆积depthwise separable convolution,并且可以看到其中的部分depthwise convolution会通过strides=2进行down sampling。然后采用average pooling将feature变成1x1,根据预测类别大小加上全连接层,最后是一个softmax层。
5.2.3.1 建立mobilenet模型,加载主干特征网络的权重
此处使用迁移学习的的思想,从['https://github.com/fchollet/deep-learning-models/releases/download/v0.6/'\]该网址下载其他模型的权重,并迁移到我的模型上,可以提高模型训练的准确度,同时减少自己训练的规模。
5.2.3.2 设置训练参数
checkpoint用于设置权值保存的细节,period用于修改多少epoch保存一次
reduce_lr用于设置学习率下降的方式
early_stopping用于设定早停,val_loss多次不下降自动结束训练,表示模型基本收敛
5.2.3.3 操作数据集
打开数据集,将数据集打乱,90%用于训练,10%用于估计。
5.2.3.4 模型训练(迁移思想|冻结训练与解冻训练)
这里使用的是迁移学习的思想,主干部分提取出来的特征是通用的,可以不训练主干部分先,因此训练部分分为两步,分别是冻结训练和解冻训练,冻结训练是不训练主干的,解冻训练是训练主干的。
冻结操作:在冻结阶段,模型的主干被冻结了,特征提取网络不发生改变。占用的显存较小,仅对网络进行微调。
解冻操作:在解冻阶段,模型的主干不被冻结了,特征提取网络会发生改变。占用的显存较大,网络所有的参数都会发生改变。
通过这两种训练之后,就可以完成迁移学习,将原来的比较好的权重结构迁移到我的模型上,生成last_one.h5文件。
后续调用该模型对人脸进行识别。
5.2.4.1 创建模型
1. 创建mtcnn的模型,用于检测人脸
2. 创建mobilenet的模型,用于判断是否佩戴口罩
5.2.4.2 识别人脸并检测画框
使用opencv摄像头读入图像信息,对该图像使用mtcnn检测人脸,对监测到的人脸进行编码,同时利用人脸关键点对人脸进行对齐,再使用mobile net模型对监测到的人脸进行口罩识别,识别后使用opencv对人脸进行画框标记。
主要使用opencv实现特效提醒,向未配戴口罩的人脸上贴贴纸。
实现步骤:
①准备处理好的透明底图片

②使用OpenCV安装目录中提供的已经训练好的Haar分类器模型文件(人脸检测、人眼检测)来找到人脸位置
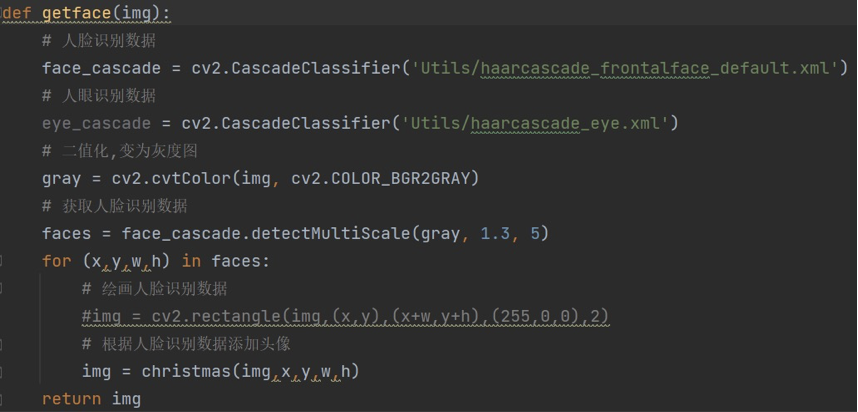
③从备选贴纸图片中随机获得一张
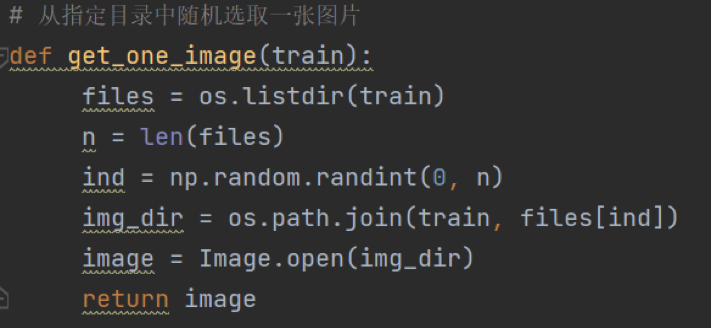
④将贴纸处理成适应人脸的大小后,使用PIL库中的composite()函数合成图像
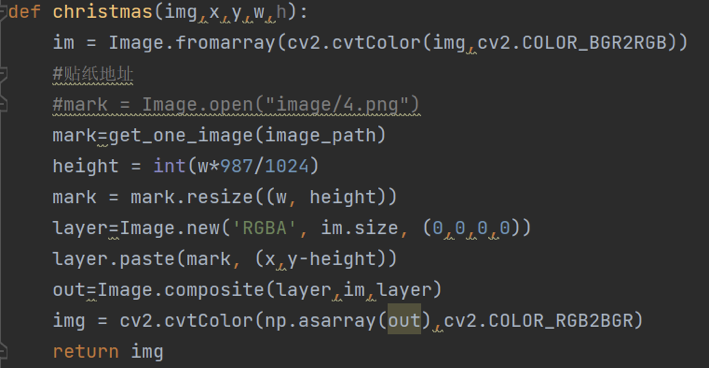
使用Flask实现在浏览器中播放rtsp实时流,且在flask web页面中处理摄像头的开启与关闭,同时在此处调用最终完成的口罩识别的封装函数来处理摄像头输入的视频数据,同时返回经过处理的视频数据,实现实时的口罩识别特效提醒,将该视频流yield到templates的index.html页面上,而在页面index.html上使用视频容器接受视频流,从而实现后端的可视化
在vue的对应的调用模型的两个页面上,使用iframe将flask实现的html页面嵌入vue的页面上,iframe的scr指向本地页面的静态网址,从而实现在前端页面上展示后端的服务的功能。
iframe与vue中监听数据传输的方法都是一直在监听的,当两边有数据发生变化时,相应的数据也会发生变化,页面的刷新可以采用reload等方式,或者重新加载,实时刷新的方式最好是通过iframe页面中的原生js去完成这个功能,在vue中通过监听事件的方式,会导致整个标签页面、弹窗刷新,达不到想要的效果,这个技术点对于最后的模型展示效果在速度上有所损耗。
下载node.js并全局安装vue3脚手架,创建vue3项目,选择手动模式,勾选Babel、router、Vuex以及CSS预设,选择vue3.0,路由配置采用哈希模式,CSS预设采用less,babel等配置选择单独保存,完成项目的创建。
删除App.vue中无用的代码,删除views文件夹下的两个自动产生的文件,删除router中对应的部分防止报错,此时运行项目无报错,表明项目初步配置完成。
在assets文件夹下新建styles文件夹,保存项目基本样式。在styles文件夹下新建base.css与variable.less文件。base.css存放基础的css样式,并在main.js中引入;variables.less中定义颜色变量,便于后期调色时统一进行更改。
在router文件夹下的index.js文件中配置路由。引入Layout.vue作为首页,其他页面均为按需引入。const routes中配置路由,实现匹配到对应路径时页面跳转的功能。共有Login、About、Homeview、Homeview2、twoMethods、user、Layout七个页面。
- 在components文件夹下创建AppTopNav.vue文件作为通用部件,实现顶部菜单通栏功能。使用无序列表编写<ul><li>编写菜单,a标签实现连接跳转,菜单栏的图标使用阿里巴巴图标库iconfont,通过标签引入public文件夹下的index.html内,在iconfont-我的项目里复制图标代码即可使用。引入vaiables.less文件使用设定好的颜色以使用定义好的颜色变量,便于后续统一风格。通过css样式设定使菜单项水平排列在顶部末端,并实现鼠标悬停时颜色的更改。
- 在components文件夹下创建MyFooter.vue文件作为通用部件,实现底部footer。引入vaiables.less文件使用设定好的颜色以使用定义好的颜色变量,便于后续统一风格。在style标签下设定背景及文字的css样式。
- 在views文件夹下创建Layout.vue作为网站主页面。引入通用部件AppTopNav及MyFooter,在容器中分别引入标签。二者之间插入容器,类名为main。main中引入span标签标明网站主题“动态场景下口罩佩戴监测与特效提醒系统”,在css中设定主图背景。在router文件夹下的index.js中配置路由,下同。
- 在views文件夹下分别创建About.vue和user.vue作为网站的关于页面与用户页面。引入通用部件AppTopNav及MyFooter,在容器中分别引入标签。二者之间插入容器,类名为aboutbg。背景图片的设定参考主页面,文字布局水平居中。
在components文件夹下创建Button.vue文件作为通用部件。绑定时间mousemove,样式为HSL格式的颜色,实现随鼠标移动而改变按钮颜色的效果。定义初始坐标为0,定义函数onMousemove获取鼠标的水平坐标并返回。在css中设定按钮的其他样式。
在views文件夹下创建twoMethods.vue作为网站“开始体验”页面。引入通用部件AppTopNav、Button及MyFooter,在容器中分别引入标签。外部容器类名为main。main中共有三个部分,分别是实现Mtcnn跳转部分、分隔线与实现YOLOv5跳转部分。第一、三部分中分别实现图片、按钮、文字的布局。按钮绑定事件鼠标点击与对应函数。函数中使用this.$router.replace('/xxx')实现跳转。在scripts标签下调整css样式。另外预留出Homeview.vue与Homeview2.view插入口罩佩戴监测效果的展示。
在views文件夹下创建Login.vue作为网站登录页面。登录页面包括三个重要部分:登录框的实现、登录功能的实现与动态背景绘制。
- 登录框的实现
使用form标签创建为用户提供输入的HTML表单。标题为Login。使用label控件实现用户名与密码的填写。其中用户名label控件的type为“text”,密码label控件的type为“password”,可以实现输入时自动替换为·(点)的效果。v-model实现双向绑定功能,即将页面上控件的值同步更新到相关绑定的data属性;同时,在更新data绑定属性时,也可以更新页面上输入控件的值。v-model.trim可以去掉输入框内首尾空格。
- 登录功能的实现
登录框的按钮绑定handlelogin函数,在methods中进行定义。首先匹配用户名与密码,若成功匹配则跳转至主页面;若提交时用户名或密码为空则弹出警示框:“用户名不为空”/“密码不为空”;若用户名及密码非空,但不匹配,则弹出警示框“账号不存在”。
- 动态背景绘制
容器标签为stars,使用v-for对star进行循环。在data中定义star的数量与间距。在mounted中实现star的运动。绑定元素后对每个元素设置旋转基点与旋转方式。背景的css中绘制带有径向渐变的黑色背景;stars的css中定义视距、旋转方式、动画属性;定义动画rotate开始和结束时的视距、移动位置,完成3D动态星空背景的效果。
项目运行软件平台为Pycharm Professional,版本号为2022.1.4,下载地址为
PyCharm: the Python IDE for Professional Developers by JetBrains
下载完成后可快速安装或自定义安装。启动Pycharm后请安装下述软件包。
项目运行的虚拟环境python版本为3.8.10,所需的软件包在以下列出,或参见项目根目录下requirements.txt文件,使用python3 -m pip install -r requirements.txt命令完成安装。
coremltools==5.2.0
Flask==2.2.2
keras==2.9.0
matplotlib==3.5.2
numpy==1.22.4
onnx==1.12.0
opencv_python==4.6.0.66
pafy==0.5.5
pandas==1.4.3
Pillow==9.2.0
requests==2.28.1
scipy==1.9.0
seaborn==0.11.2
setuptools==62.6.0
thop==0.1.1.post2207130030
torch==1.12.0+cu116
torchvision==0.13.0+cu116
tqdm==4.64.0
wandb==0.13.2
项目前端使用vue进行搭建,运行前需配置vue相关环境。
前往官网Download | Node.js (nodejs.org),选择Windows 64bit版本下载
此处建议自定义安装到设定路径下,如D:\Program Files \nodejs,安装完成后配置安装目录和缓存目录。
在node.js安装目录下创建两个文件夹【node_global】及【node_cache】分别作为默认安装目录和缓存日志目录。
执行下列命令,将npm的全局模块目录和缓存目录配置到刚才创建的目录
npm config set prefix "D:\Program Files \nodejs\node_global"
npm config set cache "D:\Program Files \nodejs\node_cache"
配置完成后,可运行npm config list命令查看是否配置成功。
node.js环境配置
“我的电脑”-右键-“属性”-“高级系统设置”-“高级”-“环境变量”,进入环境变量对话框
【系统变量】下新建【NODE_PATH】,输入【D:\Program Files\nodejs\node_modules 】
【系统变量】下的【Path】添加上node的路径【D:\Program Files\nodejs\】 一般默认安装的时候就配置了
【系统变量】和【用户变量】下的【Path】添加上 【D:\Program Files\nodejs\node_cache】,【D:\Program Files\nodejs\node_global】,这是nodejs默认的模块调用路径
配置淘宝镜像源
执行命令npm config set registry https://registry.npm.taobao.org
验证方式执行cnpm config get registry 或 cnpm config list
安装vue.js
执行命令npm install vue -g,完成安装后可执行npm info vue查看安装信息,执行npm list vue查看vue版本
安装webpack模板
在命令行中运行命令 npm install webpack -g ,然后等待安装完成。
安装脚手架vue-cli
在命令行中运行命令 npm install -g @vue/cli ,然后等待安装完成。
安装脚手架vue-router
在命令行中运行命令 npm install -g vue-router ,然后等待安装完成。
至此,项目运行环境配置完毕。
项目使用Python语言编写,主要使用了mctnn和yolov5两种算法对图像进行人脸范围的目标检测,并判断是否佩戴口罩,用醒目的贴纸特效做为未佩戴口罩人员的提醒方式,将结果简洁直观的呈现给用户,前端vue网页的美观、便捷的功能按钮保障了用户的良好使用体验。
本项目适用于公共场所下对人群口罩佩戴情况的实时监测,并对未佩戴口罩的人进行特效提醒。
运行项目时应满足第六章所述的软件平台要求,配置相关环境并安装所需的软件包。同时,为了运行前端web界面,用户机器上应安装一款web浏览器。
本项目相关训练和运行代码均基于GPU运算,用户机器上应装有支持神经网络计算的NVIDIA显卡,并配置好cuda相关运行环境,否则可能出现项目无法运行或者运行速度低下等情况。并且请避免在单摄像头机器上同时运行mtcnn和yolov5两个后端,这会导致两个后端对摄像头捕捉画面调用的冲突。
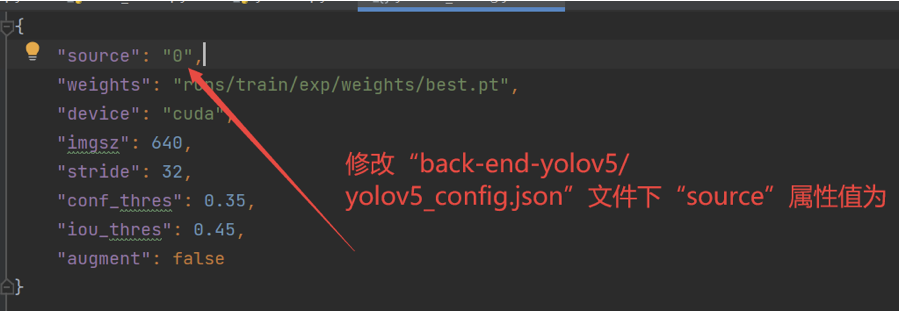
本项目默认直接从用户机器的摄像头中捕获画面进行处理,如有需求,用户也可修改源代码中输入源路径进行对现有图像或视频的处理。以yolov5模型为例,修改方法如下:
{kind=link}
项目输出为加上了人脸识别框和判别标签以及提醒特效(如未佩戴口罩)的输入文件,默认在web界面以视频流形式播放。
①从用户设备摄像头获取帧图像,作为程序输入。
②将输入图片转化为特征矩阵,送入mtcnn或yolov5对应模型中进行处理,得到图片对应的判别标签和人脸范围坐标,由相关函数进行绘制操作,结果图进行输出。
③输出结果送入flask中,转化为流文件,在web界面播放。
本项目不具备开发人员获取用户摄像头输入的功能,具有较可靠的安全性。项目源码完全开源,供广大爱好者共同学习,传播时请注明开发者信息。