pipelines extra steps
- Jenkins
- API auth
- Tune your pipelines/spark cluster size
- Migrate uuid job
- Your layers
- State/provinces layers and bitmaps
- SDS layers bitmaps
- stateProvincesCenterPoints.txt
- Assertions and Cassandra
- Running locally
- End
This page describe some extra steps to setup a pipelines cluster (but also useful if you want to run pipelines locally).
If you have a medium or big size LA portal is recommend to use the pipelines jenkins service.
pipelines needs to call some API services (collectory, images) with authentication via an API call. The la-toolkit + ala-install generates and configure for you this API keys, but you can configure them also manually. At the end your generated local extras should look like:
(...)
collectory:
wsUrl: https://collections.l-a.site/ws/
httpHeaders:
Authorization: XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX
imageService:
wsUrl: https://images.l-a.site
httpHeaders:
apiKey: XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX
(...)
and these API keys should be valid. Verify them in your auth.l-a.site/apikey service.
The inventories are generated with the default values of a typical production pipelines cluster, but you should adapt these values to your cluster size and hardware. This can be done using ansible and customizing some variables. Typically copy the values of the spark and pipelines section of your inventories in your local-extras inventory so have precedence and adapt this section.
For instance:
[spark:vars]
# http://spark-configuration.luminousmen.com/
# SPARK-DEFAULTS.CONF
# but. with .dots.
spark_default_parallelism = 144
spark_executor_memory = 22G
spark_executor_instances = 17
spark_driver_cores = 6
spark_executor_cores = 8
spark_driver_memory = 6G
spark_driver_maxResultSize = 8G
spark_driver_memoryOverhead = 819
spark_executor_memoryOverhead = 819
spark_dynamicAllocation_enabled = false
spark_sql_adaptive_enabled = true
# Recommended configuration:
spark_memory_fraction = 0.8
spark_scheduler_barrier_maxConcurrentTasksCheck_maxFailures = 5
spark_rdd_compress = true
spark_shuffle_compress = true
spark_shuffle_spill_compress = true
spark_serializer = org.apache.spark.serializer.KryoSerializer
spark_executor_extraJavaOptions = -XX:+UseG1GC -XX:+G1SummarizeConcMark
spark_driver_extraJavaOptions = -XX:+UseG1GC -XX:+G1SummarizeConcMarke1SummarizeConcMark
interpret_spark_parallelism = {{ spark_default_parallelism }}
interpret_spark_num_executors = {{ spark_executor_instances }}
interpret_spark_executor_cores = {{ spark_executor_cores }}
interpret_spark_executor_memory = '{{ spark_executor_memory }}'
interpret_spark_driver_memory = '{{ spark_driver_memory }}'
image_sync_spark_parallelism = {{ spark_default_parallelism }}
(...)
sensitive_spark_executor_memory = '{{ spark_executor_memory }}'
sensitive_spark_driver_memory = '{{ spark_driver_memory }}'
index_spark_parallelism = 500
index_spark_num_executors = {{ spark_executor_instances }}
index_spark_executor_cores = {{ spark_executor_cores }}
index_spark_executor_memory = '{{ spark_executor_memory }}'
index_spark_driver_memory = '{{ spark_driver_memory }}'
jackknife_spark_parallelism = 500
jackknife_spark_num_executors = {{ spark_executor_instances }}
jackknife_spark_executor_cores = {{ spark_executor_cores }}
jackknife_spark_executor_memory = '{{ spark_executor_memory }}'
jackknife_spark_driver_memory = '{{ spark_driver_memory }}'
clustering_spark_parallelism = 500
clustering_spark_executor_memory = '{{ spark_executor_memory }}'
clustering_spark_driver_memory = '{{ spark_driver_memory }}'
solr_spark_parallelism = 500
solr_spark_num_executors = 6
solr_spark_executor_cores = 8
solr_spark_executor_memory = '20G'
solr_spark_driver_memory = '6G'
# ALA uses 24 cores and 28G, tune this in your local inventories for adjust it
spark_env_extras = { 'SPARK_WORKER_CORES': 24, 'SPARK_WORKER_MEMORY': '24g', 'SPARK_LOCAL_DIRS': '/data/spark-tmp', 'SPARK_WORKER_OPTS': '-Dspark.worker.cleanup.enabled=true -Dspark.worker.cleanup.interval=300 -Dspark.worker.cleanup.appDataTtl=300 -Dspark.network.timeout=180000' }
[pipelines:vars]
(...)
pipelines_jvm_def_options = -Xmx16g -XX:+UseG1GC
(...)
Common problems if you don't do this part correctly:
- When a job is configured with too much resources that your workers have the job not starts never and stay in "WAITING".
- If you configure spark with too much memory, the jobs are killed by the kernel with OOM. You have to low the memory used by spark for this job or similar.
If you are using cassandra in your LA portal and you want to migrate to use pipelines, you'll want to preserver the occurrences UUIDs. For that there is a jenkins job, but you will need several things to run this job. In your production cassandra:
- Create this directory
# mkdir /data/uuid-exports/
# chown someuser:someuser /data/uuid-exports/ # optionally
- copy in
/data/uuid-exports/uuid-export.shthis script and give execution permissions.
# chmod +x /data/uuid-exports/uuid-export.sh
- Be sure that you can connect ssh passwordless from your pipelines jenkins to your cassandra, from the spark user to
someuserin cassandra that can run the previous script. - Adapt the migration-uuid job to fit to your infrastructure and users
- Verify that you have
la-pipelines-migrationinstalled in your pipelines master. Verify that theMigrate-uuidpipelines job JAR is pointing to/usr/share/la-pipelines/la-pipelines.jar. See this issue.
Do a tar with your layers and put in a public website. Configure your inventories to use them:
[pipelines:vars]
(...)
geocode_state_province_layer = provincias
geocode_state_province_field = nameunit
pipelines_shapefiles_extra_url = https://l-a.site/others/layers/extra-layers.tgz
pipelines_shapefiles_extra_checksum = sha1:1f04efd7b03690f9bc5c27e42315d3be69cadbb1
sds_layers_with_bitmaps_url = https://l-a.site/others/layers/extra-layers.tgz
sds_layers_with_bitmaps_checksum = sha1:1f04efd7b03690f9bc5c27e42315d3be69cadbb1
We use bitmaps of layers to decrease the number of WS call. See this PR and this script about how to generate them.
The same with your SDS layers
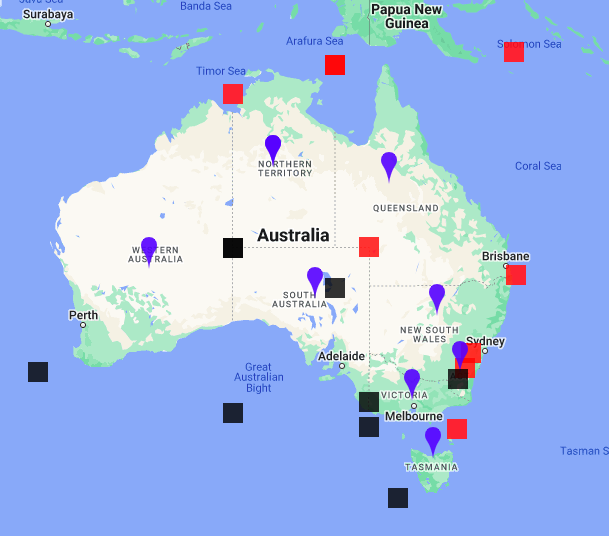
This file is a csv (tab delimiter) with the name of your state or provinces, the centroid latitude, the longitude and 4 more values with the bounding box of the province/state.
A typical stateProvince centroids file and the bbox (Marker of the centroid in blue, SW in black, NE in red):
 .
.
A node js snippet to generate your stateProvinceCentrePoints.txt:
const shapefileToGeojson = require("shapefile-to-geojson");
const bbox = require('geojson-bbox');
const centroid = require('@turf/centroid').default;
const { stringify } = require('csv-stringify/sync');
const provinces = [];
shapefileToGeojson.parseFiles("/data/pipelines-shp/provincias.shp", "/data/pipelines-shp/provincias.dbf").then((geoJSON) => {
for (let prov of geoJSON.features) {
let bounds = bbox(prov.geometry);
let cent = centroid(prov.geometry).geometry.coordinates;
// The name of the field in your DBF with the state or provinces names (in our case NAMEUNIT)
let name = prov.properties.NAMEUNIT;
provinces.push([name, cent[1], cent[0], bounds[3], bounds[2], bounds[1], bounds[0]]);
}
// Warn: the delimiter is a TAB
const output = stringify(provinces, { delimiter: " "});
console.log(output);
});
You can verify the generated stateProvinceCentrePoints.txt using for instance https://mobisoftinfotech.com/tools/plot-multiple-points-on-map/ and pasting the result of:
cat stateProvinceCentrePoints.txt | awk -F" " '{print $2","$3",blue,marker,\""$1" Center\"\n"$4","$5",red,square,\""$1" NE\"\n"$6","$7",black,square,\""$1" SW\"" }'
Again, the delimiter (-F) is a TAB.
Configure later like this in your inventories:
[pipelines:vars]
(...)
state_province_centre_points_file = {{inventory_dir}}/files/stateProvinceCentrePoints.txt
TODO, FIXME: how to do this part in new and existing biocache-store portals.
You can install in your computer the la-pipelines package, https://github.com/AtlasOfLivingAustralia/documentation/wiki/Testing-Debian-Packaging#testing-la-pipelines-package If you want to play, it's easy. You'll need also a nameindex service and solr if you want to do all the process: https://github.com/gbif/pipelines/tree/dev/livingatlas#running-la-pipelines
Some /data/la-pipelines/config/la-pipelines-local.yaml:
collectory:
wsUrl: https://collections.l-a.site/ws/
httpHeaders:
Authorization: XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX
imageService:
wsUrl: https://images.l-a.site
httpHeaders:
apiKey: XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX
speciesListService:
wsUrl: https://lists.l-a.site
sampling:
baseUrl: https://spatial.l-a.site/ws/
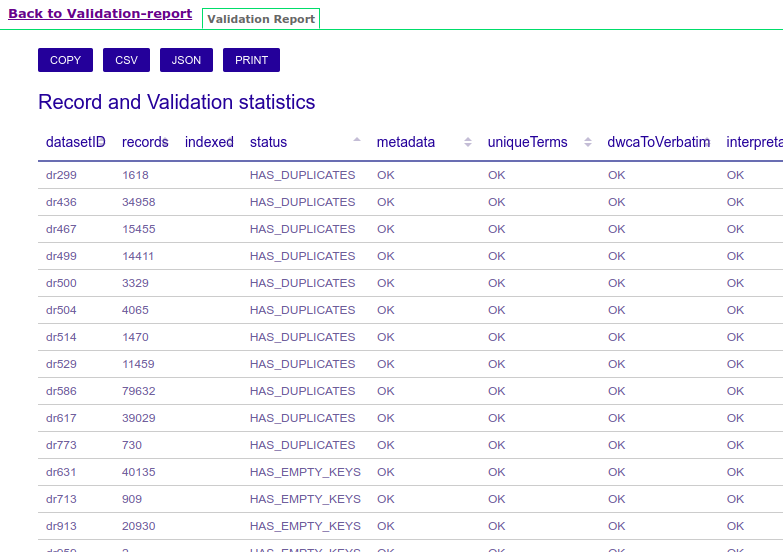
The validation-report step and jenkins job generate some useful html reports to summarize the whole process results:
 .
.
In order to make the html work in jenkins (using localhost works without problem) you have to "relax" the content security policy : https://wiki.jenkins.io/JENKINS/Configuring-Content-Security-Policy.html
System.setProperty("hudson.model.DirectoryBrowserSupport.CSP", "sandbox allow-scripts; default-src 'self' 'unsafe-inline'; img-src 'self'; style-src 'self' 'unsafe-inline';")
probably this setting can be improved and restricted a bit.
Currently if you are using the unattended-upgrades package to keep you servers up-to-date, it will upgrade too these three packages. We pin them via this task:
- hosts: namematching
roles:
- role: jnv.unattended-upgrades
unattended_origins_patterns:
- 'origin=Ubuntu,archive=${distro_codename}-security'
- 'o=Ubuntu,a=${distro_codename}-updates'
# - '. bionic:bionic'
- "site=apt.gbif.es"
unattended_package_blacklist: [la-pipelines,ala-sensitive-data-service,ala-namematching-service]
unattended_mail: 'sysadmins@gbif.es'
when: ansible_distribution == 'Ubuntu'
tags: unat
That adds this:

to /etc/apt/apt.conf.d/50unattended-upgrades.