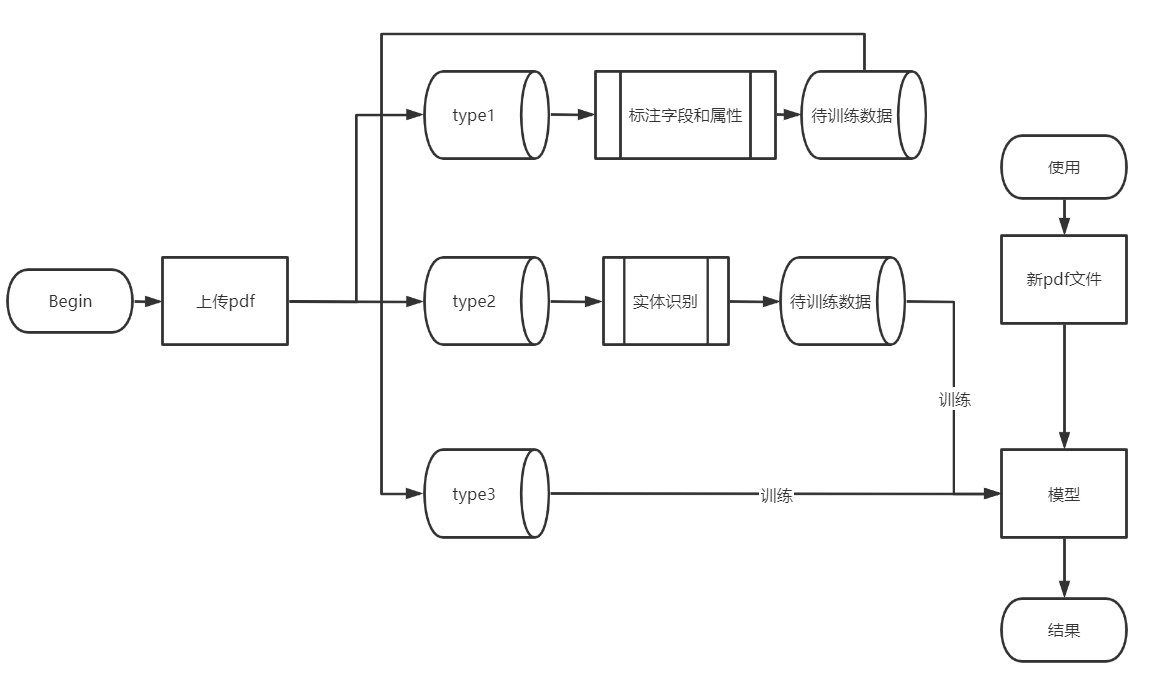
项目流程说明
- 上传训练pdf文件(5个以上)
- 标注pdf文件,采用{key:value}的样式,key是属性,包括{string,date,...},而value是pdf文件中的字段
- 训练模型
- 使用训练好的模型识别新的pdf文件,提取之前标注的字段
但是以上的方式,每一个训练数据都必须单独标注,且标注过程是高度重复的,因此有了以下新方法:
- 上传一个空白的pdf模板
- 标注需要生成数据的范围框,同时为框选定属性(用于生成),生成labels.json文件
- 后端使用模板和lables.json生成5个(自由选择).pdf文件和对应的pdf.fields.json文件
- 训练模型
- 使用训练好的模型识别新的pdf文件,提取标注的字段
- 上传5个以上pdf文件(已填好数据)
- 后端使用实体识别来分析上传的pdf文件,利用数据生成模块,生成对应的fields.json文件
- 训练模型
- 使用训练好的模型识别新的pdf文件,提取标注的字段