-
Notifications
You must be signed in to change notification settings - Fork 1
Home
Scribe was created by The Baki Project, a Newbook Digital Texts in the Humanities project. Researchers, primarily from the University of Washington (UW), Turkish transcriptionists, Ottomanist scholars, and a UW iSchool Informatics capstone team worked together to produce this tool designed to mitigate the faith gap between Arabic and Latin-based Turkish manuscripts.
It may take up to 30 seconds to load, depending on when the tool was last used.
- Developers who are interested in improving the tool
- Transcribers who are interested in learning about how this tool could be expanded upon and improved
Learn how to start transcribing with Scribe
The top-level README of this repository serves to explain some of the technology decisions behind how this tool works. Each file/component of the application has a description. Developers who are unfamiliar with the project can go there to learn how the internals of the tool work.
As of April 2020, the Reversible-Transcription Tool (Scribe) is purely a client-side React app hosted on Heroku. You can contact Sarah Ketchley (ketchley@uw.edu) for administrative access to the Heroku dashboard. There is no application storage beyond saving the current state of the tool to an archival .json file. These files have a consistent structure and are human-readable (with some effort). You can look at a sample one here.
Learn more in the Developer Overview
The tool was designed to line up with our user journey:
Information needs: Which works from a collection should I transcribe? How do I access manuscripts from libraries that are abroad? Do I have permission to transcribe these texts? Which fonts should I use? How can I create shortcuts that I can use in word processors to enter special Turkish characters?
Pain points: It takes a lot of overhead work to setup character shortcuts in word processors and review library copyright permissions. I can start once my personal system/process is set up.
Opportunity: Creating a standardized process will give me consistency and mitigate the need to set up a personal system for transcription.
Information needs: Why does transcribing take so long? Is there a better way to cross-compare the Ottoman Arabic script with the Latin based Turkish script rather than on paper? How should I indicate that some words and/or characters are illegible?
Pain points: It takes an enormous amount of time to transcribe. Texts are manually transcribed into the transcription alphabet (phonetic) on paper and then turned into the desired language in a word processor.
Opportunity: We will eliminate the need to manually transcribe on paper from one script to another. The proposed tool will take considerably less time to use and produce a wider range of outputs for the same amount of time transcribing.
Information needs: How do I know that the reverse-transcription is correct? What is the best way to manually compare one text to another? What notes should I enter to communicate editorial decisions that I've made?
Pain points: Many transcriptions have editorial decisions that were made but not documented, so those choices are unclear to the next reader.
Opportunity: We will allow transcribers to leave comments at every line (and maybe even for words or specific symbols) so that future readers know what and why choices were made. This also encourages collaboration in the field.
Information needs: How can I be sure that others can use my completed work? How can I be sure that others have not done this transcription work before?
Pain points: There is no collaboration in the current process. There is no way for me to thoroughly check if the work has already been done. I cannot securely publish my work for others to see.
Opportunity: We will allow the transcriber to have their own collections that they can save. And if they would like to publish, they submit for approval. Once approved, their transcription will appear in our archives.
Information needs: How do I ask questions of the transcriber who worked on this document? Is there a way that I can reach this transcriber?
Pain points: Previously published work might be incorrect and I may not have any way to reach the transcriber to ask about an editorial decision
Opportunity: We will create a notification system that sends out emails to a user if others post comments on their published work. This will alleviate people from having to check the Tool's archives consistently to see if anyone has commented.
We encourage developers and researchers to think critically about what they need from Scribe and separate need-to-have features from nice-to-have features.
NOTE: Write unit tests to protect against regressions in functionality before changing any of the internals.
- Upgrade to a newer release — The core text-editing framework powering Scribe is out of date. Upgrading to a newer release might fix some existing bugs or open up additional possibilities for transcription.
- Support other languages — The tool currently only supports the transcription of Turkish in Arabic/Latin script, but it is possible to add support for additional languages. One would need to create a different rules file and hook it up to some user selection when they wish to change languages.
- Add and change language rules — The current list of rules is not exhaustive and may require additions or changes based on transcribers' needs.
- Identify which rules are Turkish, Arabic, and Persian — Add another metadata field that records which language the rule is associated with.
- Help transcribers select an option — Allow transcribers to select an option using arrows on their keyboard or clicking rather than forcing the transcriber to type the option's number.
- Create a shared database to publish and save transcriptions — Finished archives made using Scribe can be uploaded to a website backed by a shared database. Since their standard JSON format is compatible with many database systems out of the box, one can easily imagine setting up a website that accepts uploads of users' work.
- Correct the output for "eyi" — Selecting the rule "eyi" uses the wrong output because "yi" is a valid combination. The tool uses the "yi" transcription rule in the output instead of "eyi." The tool needs to be updated to allow for longer strings that contain rules that are substrings.
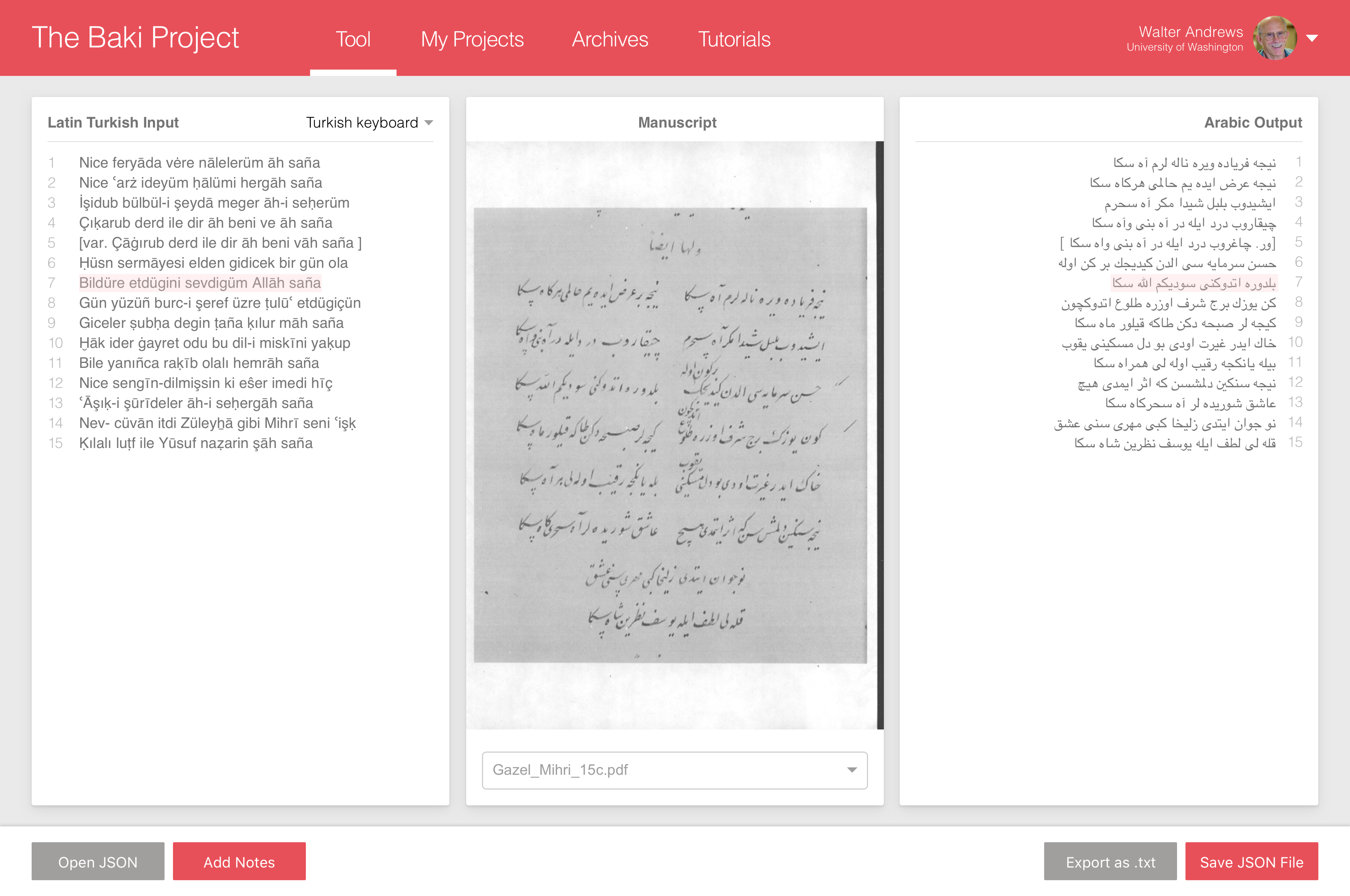
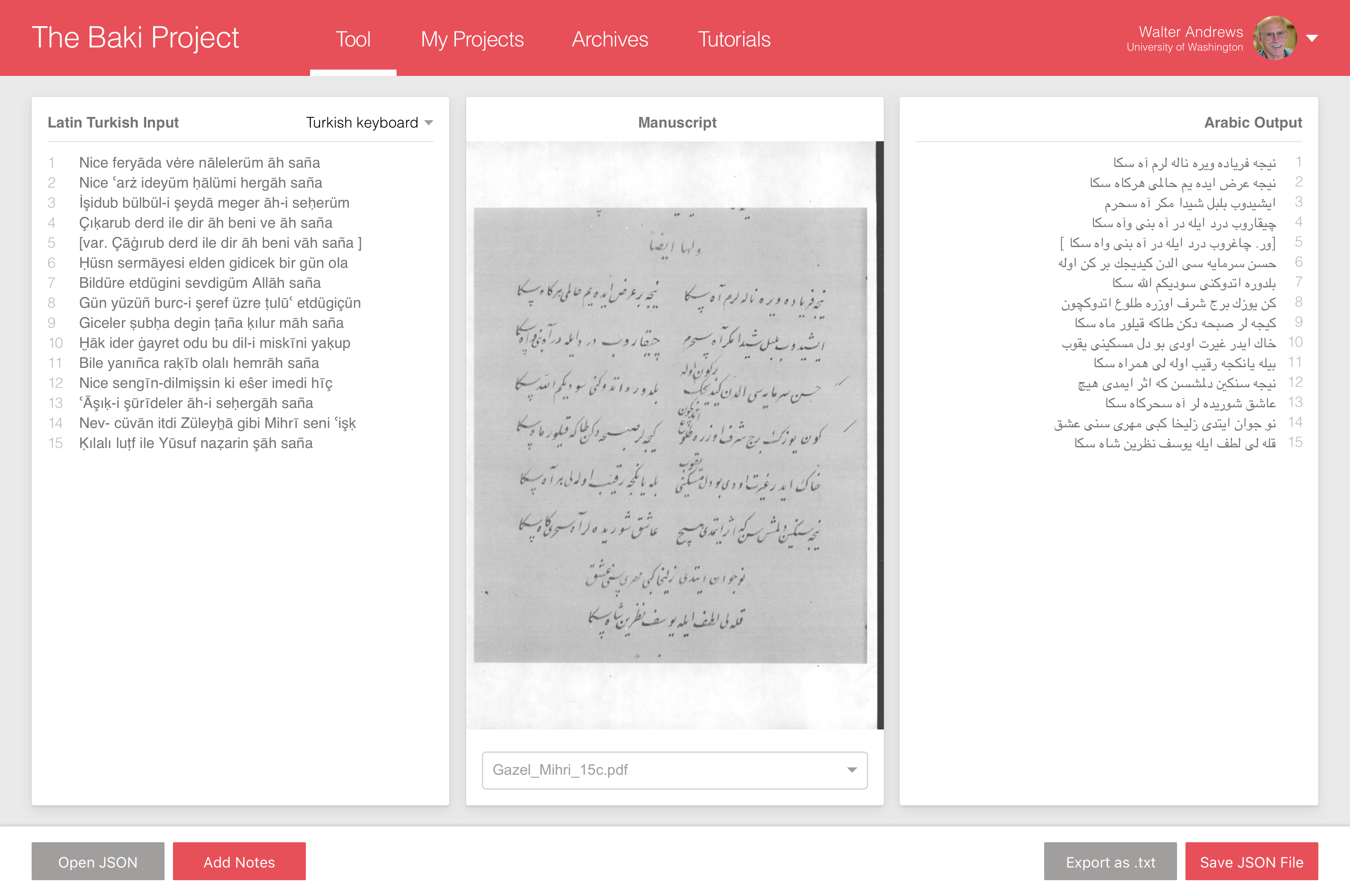
- View all transcriptions
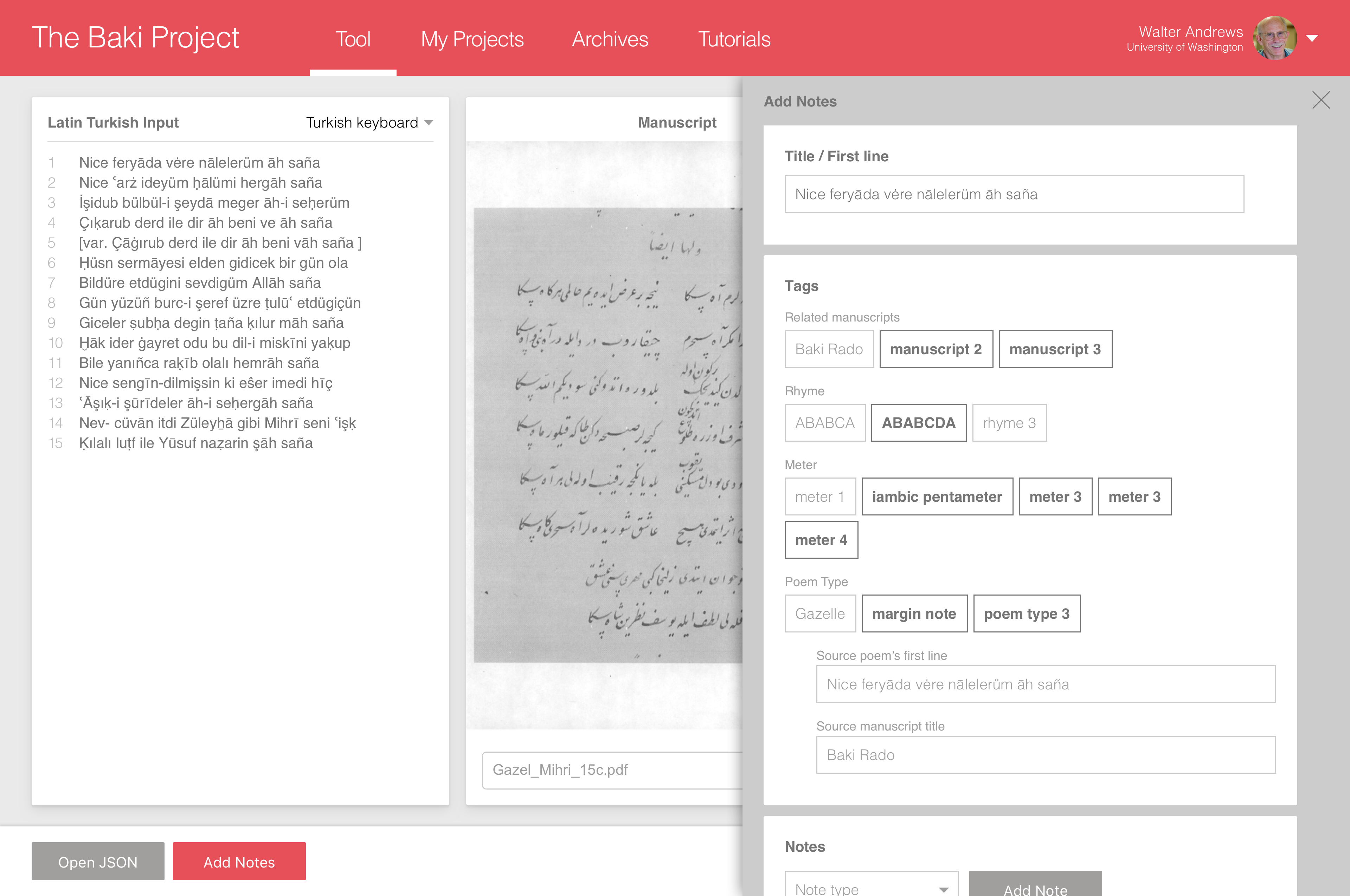
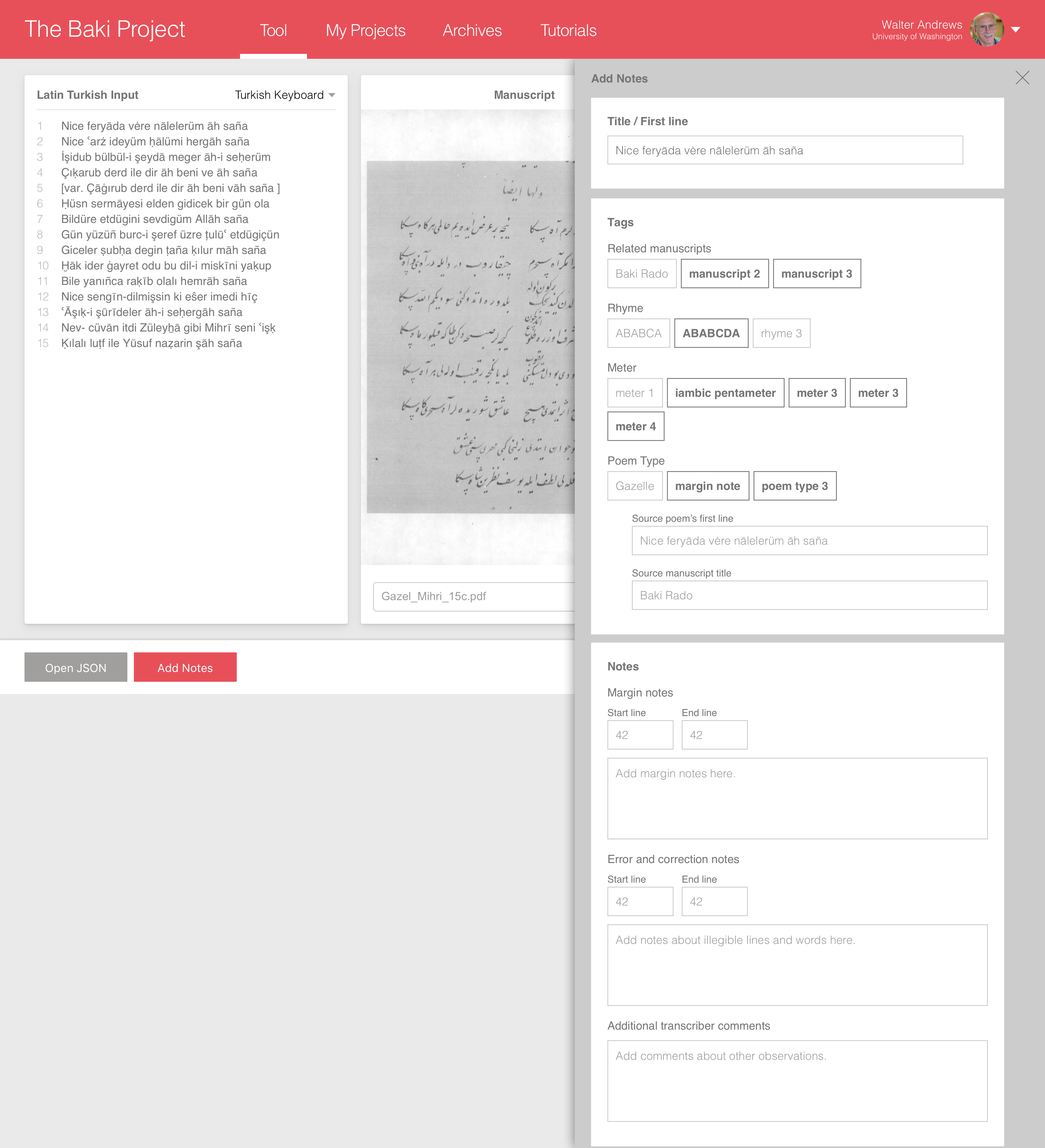
- Add transcription metadata
- Add transcription metadata (expanded)
- View lines with notes
{kind=link}
{kind=link}
{kind=link}
- Identify and apply machine learning opportunities — The output of Scribe is considered 'structured' data and machine-readable. Manuscript images and transcriptions could potentially be analyzed to identify how authors' handwriting, diction, and grammar changes over time.
- Introduce authentication to facilitate collaboration — See the projects mockup to get an idea of how finished transcriptions might be discoverable by others.
- Create a project management system — Allow transcribers to work on multiple transcriptions projects and save their work to those respective projects.
- Support offline functionality — Transcribers do not always have the means of being connected to the internet, especially when working from libraries, so they may need offline functionality once other collaboration features are added.
- Help transcribers read the manuscripts — Allow transcribers to zoom in and out in the manuscript image viewer so they can transcribe quickly and easily. Allow transcribers to upload and read multiple paged documents.
- Highlight the actively selected disambiguation rule in the dropdown
- Add a setting for whether or not the transcriber wants to include line numbers
{kind=link}