(Unofficial)-Re-Impementation of the model archiecture of CONTRASTIVE LEARNING OF GENERAL-PURPOSE AUDIO REPRESENTATIONS in PyTorch.
Paper: CONTRASTIVE LEARNING OF GENERAL-PURPOSE AUDIO REPRESENTATIONS
Paper's Official Code (In tensorflow): tf-code
git clone https://github.com/CVxTz/COLA_pytorch
cd COLA_pytorch
python -m pip install .
# Data download: download fma data and metadata
wget -c https://os.unil.cloud.switch.ch/fma/fma_metadata.zip
wget -c https://os.unil.cloud.switch.ch/fma/fma_small.zip
wget -c https://os.unil.cloud.switch.ch/fma/fma_large.zip
# Data preparation : prepare json with fma_small labels and pre-compute mel-spectrograms and save them as .npy
python supervised_examples/prepare_data.py --metadata_path "/media/ml/data_ml/fma_metadata/"
python audio_encoder/audio_processing.py --mp3_path "/media/ml/data_ml/fma_large/"
python audio_encoder/audio_processing.py --mp3_path "/media/ml/data_ml/fma_small/"
# Training
# Train with COLA
python audio_encoder/train_encoder.py --mp3_path "/media/ml/data_ml/fma_large/"
# Train Supervised
python supervised_examples/cnn_genre_classification.py --metadata_path "/media/ml/data_ml/fma_metadata/" \
--mp3_path "/media/ml/data_ml/fma_small/"
python supervised_examples/cnn_genre_classification.py --metadata_path "/media/ml/data_ml/fma_metadata/" \
--mp3_path "/media/ml/data_ml/fma_small/" \
--encoder_path "models/encoder.ckpt"
This post is a short summary and steps to implement the following paper:
The objective of this paper is to learn self-supervised general-purpose audio representations using Discriminative Pre-Training. The authors train a 2D CNN EfficientNet-B0 to transform Mel-spectrograms into 1D-512 vectors. Those representations are then transferred to other tasks like Speaker Identification or Bird Song detection.
The basic idea behind DPT is to define an anchor element, a positive element, and one or more distractors. A model is then trained to match the anchor with the positive example.
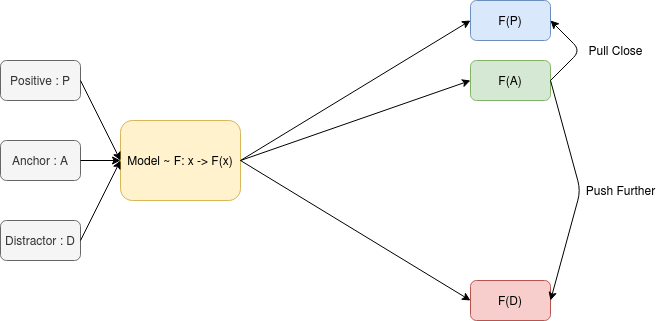
DPT — Image By Author
One such way of using DPT is to use the triplet loss along with the Cosine similarity measure to train the model such as Cosine(F(P), F(A)) is much higher than Cosine(F(D), F(A)). This will make it so the representation in the latent space of the Anchor is much closer to the Positive example than it is to the Distractor. The authors of the paper linked above used this approach as a baseline to show that their approach **COLA **works much better.
This approach is applied to the audio domain. For each audio clip, the authors pick a segment to be the anchor and another to be the positive example, for each of those samples (Anchor, Positive) they pick the other samples in the training batch as the distractors. This is a great idea for two reasons:
- There are multiple distractors, this makes the training task harder, forcing the model to learn more meaningful representations to solve it.
- The distractors are reused from other samples in the batch, which reduces the IO, computing, and memory cost of generating them.
COLA also uses a Bi-linear similarity, which is learned directly from the data. The authors show that Bi-Linear similarity works much better than Cosine, giving an extra 7% average accuracy on downstream tasks in comparison.
After computing the similarity between the anchor and the other examples, the similarity values are used in a cross-entropy loss that measures the model’s ability to identify the positive example among the distractors (Eq 2 in the paper).
Linear Model Evaluation
COLA is used to train an EfficientNet-B0 on AudioSet, a dataset of around 1M audio clips taken from YouTube. The feature vectors generated by the model are then used to train a linear classifier on a wide range of downstream tasks. The better the representations learned by the model are, the better its performance will be when used as input to a linear model that performs a supervised task. The authors found that COLA outperforms other methods like triplet loss by an extra 20% average accuracy on downstream tasks ( Table 2 of the paper)
Fine-tuning Evaluation
Another way to test this approach is to fine-tune the model on downstream tasks. This allowed the authors to compare a model pre-trained using COLA to one that is trained from scratch. Their results show that the pre-trained model outperforms the model trained from scratch by around 1.2% on average.
I don’t have the compute resources to reproduce the experiments of the paper, so I tried to do something similar on a much smaller scale. I pre-trained a model using COLA on FMA Large ( without the labels) for a few epochs and then fine-tune on music genre detection applied to FMA Small.
The results on FMA small are as follows:
- Random guess: 12.5%
- Trained from scratch: 51.1%
- Pre-trained using COLA:** 54.3%**
The paper Learning of General-Purpose Audio Representations introduces the COLA pre-training approach, which implements some great ideas that make self-supervised training more effective, like using batch samples as distractors and the bi-linear similarity measure. This approach can be used to improve the performance of downstream supervised audio tasks.