Ryuforcement is a fighting game AI. Our mains objective are :
- Develop a Reinforcement/Q-Learning algorithm.
- Train Ryuforcement, so he can become the Strongest Warrior !
Ryuforcement will learn to play Street Fighter II at first.
We're using Gym Retro to emulate Street Fighter II : Special Champion Edition, a Genesis game, and create an environnement for our AI.
Ryuforcement plays Ryu. SHORYUKEN!!
- Clone the repository with
git clone git@github.com:Camille-Gouneau/Ryuforcement.git Ryuforcement - Make sure you've installed all the Required Libraries.
- Follow the Quick Start part.
After the Installation Part,
Download a ROM of Street Fighter II : Special Championship Edition. We used this one : https://edgeemu.net/details-38235.htm !
Execute python3 -m retro.import <path_to_your_ROMs_directory>
We've put our rom in the folder roms, so we executed python3 -m retro.import roms
You should see "Importing 1 potential game" "Imported 1 games" written in your terminal. If you don't, refer yourself to Gym Retro Troubleshooting.
Now, execute ./Ryuforcement.py
A Note on "importing 1 potential game" "imported 0 games" combo. When you try to import a game, Gym Retro check the sha's rom.
You can find the required sha for the supported games here :
https://github.com/openai/retro/tree/master/retro/data/stable/ /rom.sha
Just find a rom with the same sha, and you're good to go !
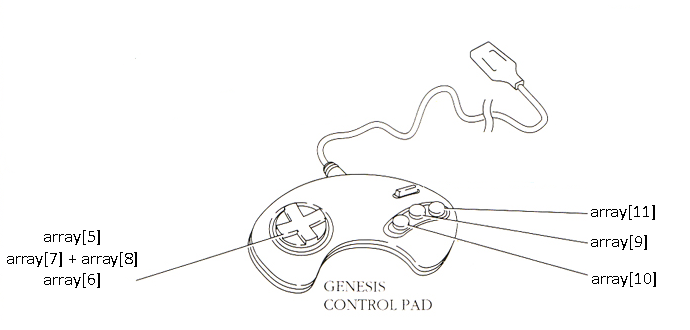
_obs, _rew, done, _info = env.step(action)
- Variable taken:
- action:
action = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
- action:
Actions are defined with an array of 12.
Each row correspond a button pressed or not.
Possible actions are :
- Movements :
- Neutral = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
- Right = [0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0]
- Left = [0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0]
- Crouch = [0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0]
- Crouch Right = [0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0]
- Crouch Left = [0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0]
- Jump Neutral = [0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0]
- Jump Right = [0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0]
- Jump Left = [0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0]
- Normals :
-
Standing Low Punch = [0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0]
-
Standing Medium Punch = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0]
-
Standing High Punch = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1]
-
Standing Low Kick = [0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
-
Standing Medium Kick = [1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
-
Standing High Kick = [0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0] # Doesn't seems to work
-
Crouching Low Punch = [0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0]
-
Crouching Medium Punch = [0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0]
-
Crouching High Punch = [0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1]
-
Crouching Low Kick = [1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0]
-
Crouching Medium Kick = [0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0]
-
Crouching High Kick = [0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0] # Doesn't seems to work
Specials :
This still need research and isn't implemented yet.
-
Slow Hadoken = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
-
Medium Hadoken = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
-
Fast Hadoken = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
-
Slow Shoryuken = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
-
Medium Shoryuken = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
-
Fast Shoryuken = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
-
Slow Tatsumaki = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
-
Medium Tatsumaki = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
-
Fast Tatsumaki = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
Throw :
This still need reseach and ins't implemented yet.
Left Throw = ? Right Throw = ?
-
Variables returned:
- _obs: array that represents the current screen :

- _rew: Reward of the AI
- done: bool who break the loop when the game is over
- _info:
{'enemy_matches_won': 0, 'score': 0, 'matches_won': 0, 'continuetimer': 0, 'enemy_health': 176,'health': 176}
http://cs231n.github.io/assets/conv-demo/index.html
More comonly known as "Recovery Lag" or "Ending Lag" in the FGC Community.
The Ending Lag is the delay between a move's effect finishing and another action being available to begin.
We had a problem while training our fighter. Since he was the Perfect Player, his input where so fast he never really stopped pressing button. The way Fighting Games works made this really annoying when we wanted to learn from his mistakes or even his good plays, since we weren't saving the action that was actually registered and executed by the game.
To fix this, we imported the Frame Data, and added it to our AI. When Ryu is in a Lag State, he doesn't press buttons anymore, and patiently wait the end of his move before inputing something again.
After some time, he started blocking certains attacks. He still sucks tho. We think that his opponent is too weak for him to learn effectively, since he will not get punished for a bad action every times.
Final Update : After some time, we figured a major problem. The environnement wasn't useful at all. We could only play against the original AI of the game. This alone makes it super hard to make progress. The project is now stopped, and we moved on to other projects.
0.0.1 : Game is emulated, thanks to Gym Retro 0.1.0 : Wrapping env() and Cleaning Up code. 0.1.1 : Added the first step of the Convolution Network 0.1.2 : Improving Convolution 0.2.0 : Finished Convolution and Implemented Neural Network. 0.2.1 : Debuging and Implemented Lag Frames on Input.
Look at the git logs for further details !
Our Project is under the MIT License, check LICENSE.txt for more info. Please source us if you re-use/modify our code and upload it somewhere !
Comming soon...
Specials Thanks to :
- OpenAI Gym Retro environnement for this incredible soft.
- Thibault Neveu who taught us all we needed for this project.
Specials No-Thanks You to :
- OpenAI Gym Retro environnement for his SHA requirement. >:(
Usefull documents:
