
Цель: Научиться разбираться в любой СУБД зная только ее название. Описание/ инструкция выполнения домашнего задания: Вам необходимо сделать отчет и ответить на следующие вопросы. Ответы должны быть развернуты и желательно с рисунками или примерами кода.
- История развития СУБД
- Инструменты для взаимодействия с СУБД
- Какой database engine используется в вашей СУБД?
- Как устроен язык запросов в вашей СУБД? Разверните БД с данными и выполните ряд запросов.
- Распределение файлов БД по разным носителям?
- На каком языке/ах программирования написана СУБД?
- Какие типы индексов поддерживаются в БД? Приведите пример создания индексов.
- Как строится процесс выполнения запросов в вашей СУБД?
- Есть ли для вашей СУБД понятие «план запросов»? Если да, объясните, как работает данный этап.
- Поддерживаются ли транзакции в вашей СУБД? Если да, то расскажите о нем. Если нет, то существует ли альтернатива?
- Какие методы восстановления поддерживаются в вашей СУБД. Расскажите о них.
- Расскажите про шардинг в вашей конкретной СУБД. Какие типы используются? Принцип работы.
- Возможно ли применить термины Data Mining, Data Warehousing и OLAP в вашей СУБД?
- Какие методы защиты поддерживаются вашей СУБД? Шифрование трафика, модели авторизации и т.п.
- Какие сообщества развивают данную СУБД? Кто в проекте имеет права на коммит и создание дистрибутива версий? Расскажите об этих людей и/или компаниях.
- Создайте свои собственные данные для демонстрации работы СУБД.
- Как продолжить самостоятельное изучение языка запросов с помощью демобазы. Если демобазы нет, то создайте ее.
- Где найти документацию и пройти обучение
- Как быть в курсе происходящего
RocksDB — это высокопроизводительный, постоянный механизм хранения ключей и значений, созданный Facebook* в 2012 году на основе кодовой базы LevelDB от Google. В попытке расширить успех HDFS от анализа данных до рабочих нагрузок обслуживания запросов (эта рабочая нагрузка требует малой задержки), Дхруба Бортакур улучшил HBase и сделал его задержки в два раза медленнее, чем у сервера MySQL. Затем, когда появилось флэш-хранилище, стало ясно, что для эффективного обслуживания произвольной рабочей нагрузки необходим новый механизм хранения.
Он начал искать новые методы для создания хранилища ключей и значений следующего поколения, особенно для обслуживания данных, находящихся в быстром хранилище. Поскольку он использовал флэш-память, доступ к сетевым данным был на 50 % выше, чем доступ к локальным данным, а это означало, что встроенная база данных в приложении могла иметь гораздо меньшую задержку, чем приложения, которые обращаются к данным по сети.
В то время существовало несколько встраиваемых баз данных: BerkeleyDB, SQLite3, а также leveldb, который был самым быстрым по результатам бенчмарков с открытым исходным кодом, плюс он был написан на C++, поэтому leveldb стал первым выбором для его бенчмаркинга.
Вскоре он обнаружил, что leveldb не подходит для рабочих нагрузок Query Serving. leveldb хорошо работает только тогда, когда размер базы данных меньше размера оперативной памяти. Кроме того, однопоточного процесса сжатия leveldb было недостаточно для управления рабочими нагрузками сервера, и он не мог использовать все операции ввода-вывода, предлагаемые базовым флэш-хранилищем.
В конце концов, он решил, что лучший путь — разветвить код leveldb и изменить его архитектуру в соответствии с потребностями (использовать базу данных, которая может работать с быстрым оборудованием хранения), и тогда родилась RocksDB.
RocksDB - использует log-structured storage engine.
Log-structured storage engine(LSM-деревья):
log-structured storage engine индексирует данные в 2 структуры данных:
- Сбалансированная древовидная структура(memtable)
- Набор сегментов хранения(Sorted String Table)
Каждый сегмент представляет собой отсортированную коллекцию пар ключ-значение.
ччВот несколько свойств SSTables: - Ключи сортируются в определенном сегменте.
- Конкретный ключ может появиться только один раз в конкретном сегменте.
- Ключ может повторяться в нескольких сегментах, но должен быть уникальным в конкретном сегменте.
- Размер SSTables зависит от количества содержащихся в нем ключей, поэтому разные SSTables могут иметь разные размеры. Как обрабатываются записи? После поступления записи:
- Запись добавляется в memtable
- Каждый раз, когда размер memtable превышает какое-то значение, он сбрасывается на диск в отсортированном ввиде в SSTable Как обрабатываются чтения?
- Сначала memtable сканируется на наличие ключа. Если найдено, возвращается значение.
- Иначе, ключ ищется в последнем сегменте, если там нет, то в предпоследней и т.д.


| Операция | Описание |
|---|---|
| Get key:value | получить одно значение по ключу |
| Put key | установить одно значение по ключу |
| Delete key | удалить ключ из БД |
| ... |
#include <cstdio>
#include <string>
#include <iostream>
#include "rocksdb/db.h"
#include "rocksdb/slice.h"
#include "rocksdb/options.h"
using ROCKSDB_NAMESPACE::DB;
using ROCKSDB_NAMESPACE::Options;
using ROCKSDB_NAMESPACE::PinnableSlice;
using ROCKSDB_NAMESPACE::ReadOptions;
using ROCKSDB_NAMESPACE::Status;
using ROCKSDB_NAMESPACE::WriteBatch;
using ROCKSDB_NAMESPACE::WriteOptions;
#if defined(OS_WIN)
std::string kDBPath = "C:\\Windows\\TEMP\\rocksdb_simple_example";
#else
std::string kDBPath = "/tmp/rocksdb_simple_example";
#endif
int main() {
DB* db;
Options options;
// Optimize RocksDB. This is the easiest way to get RocksDB to perform well
options.IncreaseParallelism();
options.OptimizeLevelStyleCompaction();
// create the DB if it's not already present
options.create_if_missing = true;
// open DB
Status s = DB::Open(options, kDBPath, &db);
assert(s.ok());
// Put key-value
std::cout << "put key1:value\n";
s = db->Put(WriteOptions(), "key1", "value");
std::cout << "okey";
assert(s.ok());
std::string value;
// get value
std::cout << "get key1\n";
s = db->Get(ReadOptions(), "key1", &value);
std::cout << value <<"\n";
assert(s.ok());
assert(value == "value");
// atomically apply a set of updates
{
WriteBatch batch;
batch.Delete("key1");
std::cout << "delete key1\n";
batch.Put("key2", value);
std::cout << "put key2:value\n";
s = db->Write(WriteOptions(), &batch);
}
std::cout << "get key1\n";
s = db->Get(ReadOptions(), "key1", &value);
assert(s.IsNotFound());
std::cout << "not found\n";
std::cout << "get key2\n";
db->Get(ReadOptions(), "key2", &value);
assert(value == "value");
std::cout << value << "\n";
delete db;
return 0;
}

RocksDB не распределённая СУБД, поэтому файлы хранятся на одном носителе.
Изначально RocksDB — это библиотека C++.
В 2018 году на официальном сайте rocsdb опубликовали пост, говорящий о том, что разработчики внедрили хэш-индекс блоков данных в RocksDB. В частности, они добавили компактную хеш-таблицу в конец блока данных для эффективной индексации. Он обратно совместим с базой данных, созданной без этой функции. После включения функции хеш-индекса существующие данные постепенно конвертируются в формат хэш-индекса.
Пример от разработчиков, как это использовать:
Хэш-индекс по умолчанию отключен, если только BlockBasedTableOptions::data_block_index_type не установлено значение data_block_index_type = kDataBlockBinaryAndHash. Коэффициент использования хеш-таблицы регулируется с помощью BlockBasedTableOptions::data_block_hash_table_util_ratio, что допустимо только в том случае, если data_block_index_type = kDataBlockBinaryAndHash.
// the definitions can be found in include/rocksdb/table.h
// The index type that will be used for the data block.
enum DataBlockIndexType : char {
kDataBlockBinarySearch = 0, // traditional block type
kDataBlockBinaryAndHash = 1, // additional hash index
};
// Set to kDataBlockBinaryAndHash to enable hash index
DataBlockIndexType data_block_index_type = kDataBlockBinarySearch;
// #entries/#buckets. It is valid only when data_block_hash_index_type is
// kDataBlockBinaryAndHash.
double data_block_hash_table_util_ratio = 0.75;
Чтобы найти правильное место, где может находиться ключ, с помощью бинарного поиска, требуется множественный анализ и сравнение ключей. Каждое ветвление бинарного поиска приводит к промаху кеша ЦП, вызывая большую загрузку ЦП.
Разработчики реализовали хэш-карту в конце блока для индексации ключа, чтобы уменьшить нагрузку на ЦП при двоичном поиске. Хэш-индекс — это просто массив указателей, указывающих на индекс двоичного поиска.
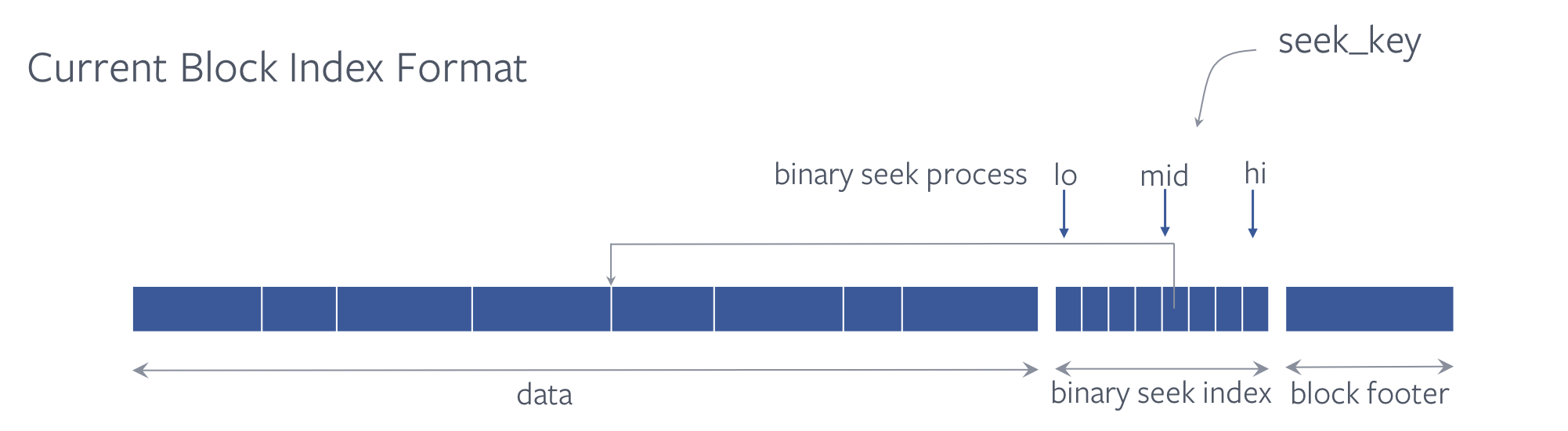
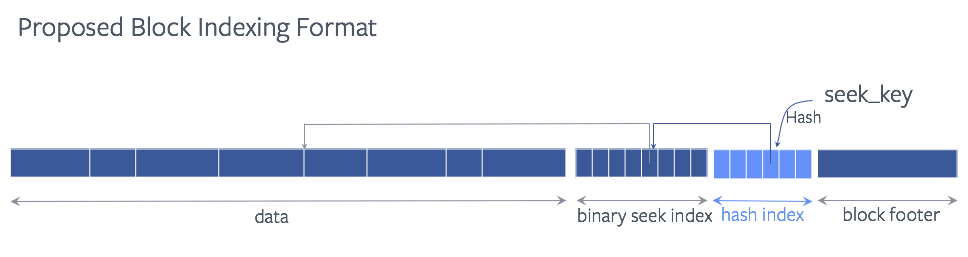
Запросы выполняются последовательно, остальные ситуации рассмотрены тут
Нет
Поддерживаются ли транзакции в вашей СУБД? Если да, то расскажите о нем. Если нет, то существует ли альтернатива?
RocksDB поддерживает транзакции при использовании TransactionDB или OptimisticTransactionDB(pessimistic и optimistic concurrency control).
Optimistic concurrency control(OCC) - это метод управления параллелизмом, применяемый к транзакционным системам. OCC предполагает, что несколько транзакций часто могут выполняться, не мешая друг другу. Во время выполнения транзакции используют ресурсы данных, не блокируя эти ресурсы. Перед фиксацией каждая транзакция проверяет, что никакая другая транзакция не изменила прочитанные ею данные. Если проверка выявляет конфликтующие модификации, фиксирующая транзакция откатывается и может быть перезапущена.
Pessimistic concurrency control(PCC) - это метод управления параллелизмом, применяемый к транзакционным системам. PCC предполагает худшее — что два или более пользователей захотят обновить одну и ту же запись одновременно, а затем предотвращает эту возможность, блокируя запись, нет. независимо от того, насколько маловероятны конфликты на самом деле. Блокировки устанавливаются, как только осуществляется доступ к любой части строки, что делает невозможным одновременное обновление строки двумя или более пользователями. В зависимости от режима блокировки ( совместно используемого , монопольного или обновляемого ) другие пользователи могут читать данные, даже если на них установлена блокировка.
TransactionDB
При использовании TransactionDB все записанные ключи блокируются внутри RocksDB для обнаружения конфликтов. Если ключ не может быть заблокирован, операция вернет ошибку. Когда транзакция зафиксирована, она гарантированно будет успешной до тех пор, пока в базу данных можно будет производить запись. TransactionDB может быть лучше для рабочих нагрузок с большим параллелизмом по сравнению с OptimisticTransactionDB. Однако при использовании TransactionDB возникают небольшие затраты на блокировку.А также TransactionDB выполняет проверку конфликтов для всех операций записи (Put, Delete и Merge), включая записи, выполняемые вне транзакции.
OptimisticTransactionDB
Оптимистичные транзакции обеспечивают упрощенное управление оптимистичным параллелизмом для рабочих нагрузок, которые не предполагают высокой конкуренции/интерференций между несколькими транзакциями.Оптимистичные транзакции не блокируются при подготовке к записи. Вместо этого они полагаются на обнаружение конфликтов во время фиксации, чтобы убедиться, что никакие другие писатели не изменили ключи, записываемые текущей транзакцией. Если есть конфликт с другой записью (или он не может быть определен), коммит вернет ошибку и никакие ключи не будут записаны.Оптимистичный контроль параллелизма полезен для многих рабочих нагрузок, которым требуется защита от случайных конфликтов записи. Однако это может быть не лучшим решением для рабочих нагрузок, где часто возникают конфликты записи из-за того, что множество транзакций постоянно пытаются обновить одни и те же ключи. Для этих рабочих нагрузо лучше подходит использование TransactionDB. OptimisticTransactionDB может быть более производительным, чем TransactionDB для рабочих нагрузок с большим количеством нетранзакционных операций записи и небольшим количеством транзакций.
Чтение из транзакции
Транзакции также поддерживают легкое чтение состояния ключей, которые в данный момент объединены в данную транзакцию, но еще не зафиксированы.
Защита от конфликтов чтения-записи
Если эта транзакция была создана с помощью TransactionDB, то либо тайм-аут, либо блокировка до тех пор, пока транзакция не будет зафиксирована или прервана. Если бы эта транзакция была создана с помощью OptimisticTransactionDB, то транзакция завершилась бы успешно, но при Commit вызове транзакция завершилась бы ошибкой.
Setting a Snapshot
По умолчанию проверка конфликтов транзакций подтверждает, что никто другой не записал ключ после того, как ключ был впервые записан в этой транзакции. Этой гарантии изоляции достаточно для многих случаев использования.
Данные большинства приложений RocksDB реплицируются на нескольких хостах, и часто они выполняют проверки согласованности, сравнивая контрольные суммы реплик. При обнаружении несоответствия контрольной суммы поврежденная реплика отбрасывается и заменяется правильной. Однако это жизнеспособный вариант только до тех пор, пока правильная реплика все еще существует и доступна. Сегодня RocksDB выполняет контрольные суммы файловых данных на нескольких уровнях, чтобы выявить повреждения, которые могли произойти в нижележащих слоях.
Блочные контрольные суммы, унаследованные от LevelDB, предотвращают раскрытие клиенту данных, поврежденных в файловой системе или ниже. В частности, к каждому блоку SSTable или фрагменту WAL прикреплена контрольная сумма, генерируемая при создании данных. В отличие от контрольной суммы файла, которая проверяется только при перемещении файла, эта контрольная сумма проверяется каждый раз при чтении блока либо для обслуживания запроса от приложения, либо для сжатия из-за меньшего объема.
Контрольные суммы файлов SSTable, добавленные в 2020 году, защищают от повреждения, вызванного базовой системой хранения, от распространения на другие реплики, а также от повреждения, вызванного в процессе передачи файлов SSTable по сети. Таким образом, каждая SSTable защищена собственной контрольной суммой, генерируемой при создании таблицы. Контрольная сумма SSTable записывается в записи файла метаданных SSTable и проверяется с помощью файла SSTable, куда бы он ни передавался.
Изначально все данные типа «ключ-значение» хранились в одном семействе столбцов RocksDB: «по умолчанию». Но начиная с одной из версий(bluestore) начали использовать несколько типов данных «ключ-значение», хранящихся в RocksDB. Каждому типу данных назначается уникальный префикс. Благодаря этому стало возможным разделить данные на несколько семейств столбцов RocksDB. Когда ключи имеют одинаковую частоту доступа, частоту модификации и время жизни, такой способ выигрывает от лучшего кэширования и более точного сжатия. Это повышает производительность, а также требует меньше места на диске при сжатии, поскольку каждое семейство столбцов меньше и может сжиматься независимо от других.

RocksDB хранит данные и не занимется их анализом.
Есть шифрование потока через BlockAccessCipherStreamс ROT13 блочным шифром. Режим работы счетчика использует начальный счетчик и случайный вектор инициализации. Оба создаются случайным образом для каждого файла и сохраняются в блоке размером 4 КБ (размер по умолчанию), который добавляется к этому файлу. Большая часть префиксного блока также зашифрована, и там остается место для конкретных настроек/значений/ключей реализации.
{kind=link}
Какие сообщества развивают данную СУБД? Кто в проекте имеет права на коммит и создание дистрибутива версий? Расскажите об этих людях и/или компаниях.
RocksDB разрабатывается и поддерживается командой разработчиков баз данных Facebook*.
Facebook* - крупнейшая социальная сеть в мире, основанная в 2004 году Марком Цукербергом и его соседями по комнате во время обучения в Гарвардском университете. Facebook* позволяет создать профиль с фотографией и информацией о себе, приглашать друзей, обмениваться с ними сообщениями, изменять свой статус, оставлять сообщения на своей и чужой «стенах», загружать фотографии и видеозаписи, создавать группы (сообщества по интересам).

Так как rocksdb это библиотека, то можно добавить базу данных для демонстрации следующим кодом, n можно поменять, на желаемое
DB* db;
Options options;
Status s = DB::Open(options, kDBPath, &db);
n = 100
for( int i = 0; i < n; ++i) {
s = db->Put(WriteOptions(), ("key" + string(i)), ("value" + string(i)));
}
Как продолжить самостоятельное изучение языка запросов с помощью демобазы. Если демобазы нет, то создайте ее.
Демобазу и примеры можно найти тут.
Вся документация находится по ссылке: https://github.com/facebook/rocksdb/wiki
Информация на официальном гитхабе: https://github.com/facebook/rocksdb Вопросы и обсуждения приветствуются в общедоступной группе RocksDB Developers на Facebook* и в списке адресов электронной почты в группах Google.
*Meta, которая владеет Facebook и Instagram, признана экстремистской организацией на территории России.