Complete font guide
- To judge font sharpness screenshots and gifs are provided. You should view these unscaled, 1:1, without the browser's image scaling, to properly asses the quality of text. Every image is clickable and opens up the image directly, so you can view it 1:1 in a new tab.
- Certain Nuklear back ends may use native, platform specific font rendering features. This guide does not apply in those cases. This includes the Windows GDI and GDI+ back ends, though they shouldn't be used due to some issues.
Details and build instructions around the Windows only GDI implantations
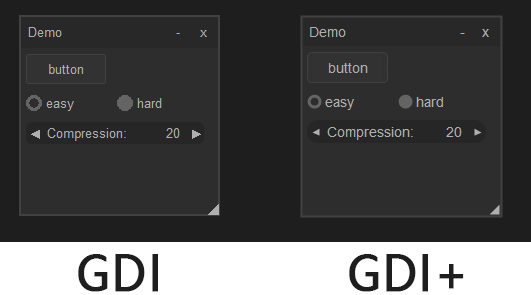
The demo folder has GDI and GDI+ back ends. The upside of using GDI, is that Windows takes care of the rendering and also side steps edge cases, like OpenGL over RDP being a possible issue. Most importantly this includes font rendering being taken care of by Windows' native rendering and pulling in features like ClearType.
Unfortunately these demo back ends are in an unusable state as they are. The GDI+ (gdip) implementation suffers from very slow performance, not managing even 30fps if the window is a bit larger and dropping to single digit fps when large nk_images are used, even though task manager reports the GPU being properly utilized. The GDI implementation does not suffer from this, but in its current state does not apply anti-aliasing to the drawn elements. Even conceptionally using GDI is probably a bad idea. Besides being Windows only, you get all the downsides of a non-native app, whilst not actually being a native app. Just use the DirectX11 back end if you want a Windows only app. When using DirectX11, Windows even provides a built-in fallback to software rendering if anything goes wrong.
If you want to try it out for yourself, download Visual CPP build-tools. Click install, or Modify if already installed. Under "Individual components" install MSVC v140 - VS 2015 C++ build tools (v14.00). Now double clicking build.bat will automatically build demo.exe.

The guide is written for all back ends that make use of Nuklear's font management, like DirectX, OpenGL, OpenGL ES etc.
By default Nuklear bakes any TrueType (.ttf) or OpenType (.otf) font file using stb_truetype.h and draws its widgets using the resulting font atlas if NK_INCLUDE_FONT_BAKING is defined. This happens every time you launch your program, there exists no persistent caching algorithm. If no font file is provided and NK_INCLUDE_DEFAULT_FONT is defined, then a base85 encoded version of ProggyClean.ttf is baked instead.
In its default configuration, Nuklear provides no other means of handling fonts, although the avenue of interfacing to another font handler is open. "If you already have font handling or do not want to use this font handler you don't have to define it."
Here is what a font atlas looks like. (Just the ASCII characters, to avoid cluttering the article)

Mouse cursors are always baked by default as well, always with a fixed size as defined in Nuklear's source code. This is in case you enable the additional drawing of a mouse cursors and disable the operating system's mouse cursor, or are in an environment without mouse cursor support at all. It can be considered a short coming, that cursors are baked in every atlas, even if another atlas already has them. Though a 180x27 pixel rectangle isn't a lot.
Before we jump into managing and configuring sharp fonts and icons, let's quickly go over what Nuklear is not...
The following features were often requested and discussed in the past and are not part of Nuklear yet. I wanted to write the font related ones down here for future reference. PRs always welcome! Maybe code bounties could be a way forward.
A modern way of rendering text. In it's full 4-channel MTSDF variant as generated by msdf-atlas-gen, this form of text rendering unlocks real time resizing without the need to bake multiple sizes, effects like soft shadows, hard shadows, bold fonts without the need to bake a bold variant and some more fancy text styling. Pulling in this feature set whilst staying true to what Nuklear is, is quite the challenge.
Theoretically nothing stops you from saving the atlas as an image file and including it in the binary to skip the baking process. This is impossible in Nuklear's current form, as the atlas coordinates and image baking are handled in the same function nk_font_bake. If such an optimization is desired, nk_font_bake would need to be split to output the coordinates and skip the baking process. A suitable file format to implement such a task is the Artery Atlas Font format.
Nuklear is fully aware of every unicode codepoint it requires. After building the command queue, but before rendering it, a call to stb_truetype could be made to bake the needed Glyphs. On the backend side this update could be pushed with glTexSubImage2D() in the case of OpenGL to update the GPU texture. This would remove the need to bake huge atlases to cover the vast character possibilities in non-western languages.
You may setup and switch between as many fonts as you wish. Different text sizes are treated as their own separate fonts. Styles (italics, bold, etc.) are also treated as their own fonts! Different font styles are usually provided by different font files. (Sometimes there is no italics font variant and font systems are supposed to derive their own, refered as synthetic fallback. This is not possible with Nuklear + stb_truetype.h. So if you require specific styles make sure the font provides them.)
Each variation of font, size and style requires you to setup and bake them.
If NK_INCLUDE_DEFAULT_FONT is undefined, you are required to setup at least one font. Otherwise your program will hit an assert or SegFault if asserts are disabled. If you use one of the provided back ends, configuring a font consists of:
- Creating a struct nk_font
struct nk_font * latin, * icons, * japan;This name is how you will access and switch the fonts in your GUI definition
- Creating a struct nk_font_atlas for a font each (There are ways of combining multiple fonts into a single atlas, but it's a bit more involved)
struct nk_font_atlas *atlas;
struct nk_font_atlas *atlas_icon;
struct nk_font_atlas *atlas_jap;- For each font: Creating a
struct nk_font_configand initializing it withnk_font_config()(no need to specify font size yet, thus 0)
struct nk_font_config cfg_latin = nk_font_config(0);
struct nk_font_config cfg_icons = nk_font_config(0);
struct nk_font_config cfg_japan = nk_font_config(0);- Creating an array consisting of nk_runes to define which characters should be baked into the atlas. Make sure you don't allocate this nk_rune array on the stack, but malloc() some space for it or put it into a struct to extend the array's scope until the rendering, if you render Nuklear from a different function or thread. Nuklear just gets the nk_rune array pointer and will not be able to find ranges_latin, as a result showing either the fallback character or crash!
nk_rune ranges_latin[] = {
0x0020, 0x007E, /* Ascii */
0x00A1, 0x00FF, /* Symbols + Umlaute */
0x0410, 0x044F, /* Main Cyrillic */
0
};
nk_rune ranges_icons[] = {
0xF07C, 0xF07C, /* */
0xF083, 0xF083, /* */
0xF0AD, 0xF0AD, /* */
0xF021, 0xF021, /* */
0
};
nk_rune ranges_japan[] = {
0x0020, 0x007E,
0x3001, 0x3003, /* 、。〃 */
0x3005, 0x301F, /* 々〆〇 and brackets */
0x3036, 0x3036, /* 〶 */
0x3041, 0x309F, /* Hiragana */
0x30A0, 0x30FF, /* Katakana */
/* 0x4E00, 0x9FFF, */ /* All Kanji */
/* Joyo Kanji List */
#include "joyo-unicode.txt"
0
};Here you may specify in as much detail as you wish, which Unicode ranges you need. The Unicode ranges do not need to be in ascending order, but the array always needs to end with a zero. Check online the requirements of your target languages. Consider how a user is supposed to interact with your system, so in Japanese maybe you need both Half-Width and Full-Width Kana? Stuff like this. What happens if a user enters a character not existing is discussed in the sub-chapter "Always bake the question mark". Including the whole CJK block for eastern languages may lead to some startup delay, as ~21000 glyph are being baked. Performance is talked about in the sub-chapter "Texture size limits and performance".
Specifically for languages using the CJK block, check that you pick the correct font-file with the corresponding regional character variants. I provided some info around this here. If you choose wrong, you may get nasty differences like Chinese character variants appearing in Japanese text and vice-versa:

Nuklear also includes some default functions to give you those ranges. nk_font_default_glyph_ranges() gives you ASCII + Umlaute for German and other European languages, nk_font_chinese_glyph_ranges() ASCII + most of the CJK block, nk_font_cyrillic_glyph_ranges() ASCII + Cyrillic + Extended Cyrillic and nk_font_korean_glyph_ranges() for ASCII + Korean + Their CJK block requirements.
- Assign those ranges to their respective fonts and configure other font options you may want to. (Those options are discussed in detail below)
/* assign Glyph ranges, disable oversampling, enable pixel snapping */
cfg_latin.range = ranges_latin;
cfg_icons.range = ranges_icons;
cfg_japan.range = ranges_japan;
cfg_latin.oversample_h = cfg_latin.oversample_v = 1;
cfg_icons.oversample_h = cfg_icons.oversample_v = 1;
cfg_japan.oversample_h = cfg_japan.oversample_v = 1;
cfg_latin.pixel_snap = true;
cfg_icons.pixel_snap = true;
cfg_japan.pixel_snap = true;- For each font:
- Call the
_font_stash_begin()of your back end implementation whilst specifying the target font_atlas - Assign the font-file to the backing process whilst specifying the desired font size (eg 27.5) and the font config struct. There are many ways to provide the font-file, discussed in the last chapter
- call
_font_stash_end()of your back end implementation to start the baking process
- Call the
nk_glfw3_font_stash_begin(glfw, &atlas);
latin = nk_font_atlas_add_from_memory(
atlas, (void *)NotoSansCJKjp_Regular_otf.pnt,
NotoSansCJKjp_Regular_otf.size, 27.5, &cfg_latin);
nk_glfw3_font_stash_end(glfw);
nk_glfw3_font_stash_begin(glfw, &atlas_icon);
icons = nk_font_atlas_add_from_memory(
atlas_icon, (void *)icons_ttf.pnt,
icons_ttf.size, 63.5, &cfg_icons);
nk_glfw3_font_stash_end(glfw);
nk_glfw3_font_stash_begin(glfw, &atlas_jap);
japan = nk_font_atlas_add_from_memory(
atlas_jap, (void *)NotoSansCJKjp_Regular_otf.pnt,
NotoSansCJKjp_Regular_otf.size, 40.25, &cfg_japan);
nk_glfw3_font_stash_end(glfw);- Optionally enable the Nuklear-drawn mouse cursor by providing any of the baked atlases as a parameter
- If you do this, please remember to disable the real hardware drawn cursor and if you have V-Sync enabled, the mouse cursor will lag one frame behind, creating a sloppy mouse feel
nk_style_load_all_cursors(ctx, atlas->cursors);- Finally set at least one font active
nk_style_set_font(ctx, &latin->handle);If you don't use one of the provided back ends, eg. when you have to implement a back end yourself, then you should follow the doc here and look how the demo back ends handle their _font_stash_begin() and _font_stash_end() implementations.
The workflow for icons is identical if you are happy with single-color icons. Get yourself an icon font like Font awesome and download their .otf or .ttf version. When creating the font config, define the icons you want to use. The icon's color is changed the same way any other text color is changed.
![]()
You can usually find the desired code points online on the font's preview pages or you can inspect the font with fontforge and find the code points that way. Set the Encoding view in fontforge to "Compact". This way only the included glyphs are shown and not a huge empty table.

Now you can hover over the icon that you want and read out the related Unicode code point.
What is really nice, is that if you install said font and your text editor properly accesses it, then you can just copy-paste the icon into your code and see the icon directly in your source code! No need for the cumbersome \u00C0 notation. Of course this assumes, that your text editor is editing a source-code file, that is Unicode encoded, which these days is the standard.
![]()
If your text editor does not properly access the installed font, then it will show up as a tofu block, but will continue to work just as well.

Want multi-color icons? Then you gotta bake them into their own nk_image. One such option, that fits Nuklear's design goals of statically compiled and lean C code is NanoSVG. This takes in a .svg file of and outputs a colorful RGBA array, which you can format as an nk_image. Then you insert them in any place, that Nuklear accepts nk_image. Eg. instead of using nk_button_label you'll be using nk_button_image. In fact most Nuklear elements have nk_image variants. You have to take care though at what size you bake and match it to the Nuklear element you are baking for, so you don't lose sharpness due to bilinear scaling.
...even if your font is for non-western languages only! As defined in the source, the fallback character is the question mark. If the Unicode character is not present in the atlas, it will be replaced with the question mark.

However, if the question mark is not present, you will get an assert or SegFault if asserts are disabled. Theoretically there is a safeguard for this case, the .notdef glyph, aka the famous tofu block. As you can see, the icons didn't have a question mark baked and still were replaced by the tofu block. This is because the font has the .notdef character defined and subsequently baked.

However, stb_truetype doesn't always pick up on this. In the full Google Noto font, .notdef is present, but stb_truetype does not end up baking it.

As such, you will get an assert or SegFault if asserts are disabled, if you have a missing character in a font without the question mark present. So make sure to bake ?, which is code point 0x003F, when you don't intend on baking the ASCII range. If you have a font without the question mark or an icon-only font, then redefine struct nk_font_config.fallback_glyph to another code point that is present in your font. This caution may be overkill, but it definitely beats frustrating segfaults down the line.
The jack-hammer solution to font sharpness issues. This is a feature of stb_truetype, that increases the resolution of the glyphs in the font atlas, whilst taking into account how bilinear filtering on the GPU works. Thus the font atlas itself appears blurred when oversampling is used. Nuklear's default font config defines 3x horizontal oversampling to account for an issue resulting due to an interaction of sub-pixel positioning of characters and the GPU's bilinear filtering, further discussed in the Font sharpness chapter. Also it only weakly counteracts the main cause of font sharpness loss, namely stb_truetype baking blurry with certain font sizes, also discussed in the Font sharpness chapter.

The price you pay for using this is GPU memory and bake times. Using oversampling exponentially increases memory usage and should thus only be used as a last resort. Oversampling is one of the easiest ways to blow past texture size limits when using non-western language like Chinese with large font sizes. Which brings us to...
Texture atlases get quite big if you work with non-western languages. Here is a very heavy use-case: The full CJK block for Japanese + European languages in a big font size without oversampling results in the following 8kx8k font atlas. This png is so big, that the browser refuses to display it and just downloads it instead. That is a lot of GPU memory. More over, you may blow past your GPU texture size limit when working with non-western languages due to some defaults:
{kind=link}
Nuklear limits the texture atlas resolution to 1024px wide by default. So including the full CJK block, with a bigger font size and the default 3x horizontal oversampling will blow past your GPU memory limit with a 1024px X 24000px texture strip. This PR seeks to remedy this by allowing you to pass on your GPU texture limit to Nuklear. In the mean time you may just change the line *width = (total_glyph_count > 1000) ? 1024 : 512; in your Nuklear.h to your GPU's max texture size. This stops Nuklear baking long 1024px texture strips and gives you lots of breathing room for big font configs.
All performance numbers and comparisons are best-case only: no oversampling, on a modern workstation with compiler optimizations turned to the max. Namely -Ofast and LTO, on an AMD Ryzen 7 2700X turboing to 4.3 GHz during the font baking process. Just the baking process of the single-threaded stb_truetype is measured, excluding upload to GPU memory as well. An embedded use-case will show vastly worse numbers of course.
Using the same font size 32 across all Unicode ranges for testing: Baking just the default range (ASCII + everything up to 00FF for German and other European languages) takes just ~3ms. Baking everything that might be needed for Japanese (Full CJK block, half and full width kana, misc symbols) takes ~600ms, which makes for a noticeable delay in program startup. You can select a smaller scope when baking your fonts. For instance with Japanese, you can define just the Jōyō kanji and cut the time needed to bake the Japanese font to ~60ms. No user-input required? Then scrape your translated strings file or just straight up your full source code for every Unicode code points used during build time. Save it into a .txt file and include it in the font config. This will give you just the needed glyphs to draw your GUI.
Except for font color, nuklear provides no abstraction higher than individually changing fonts in between defining GUI elements. Need to change font size or font style? Then you need to call nk_style_set_font(ctx, &nk_font->handle) with your font before specifying the Nuklear element, that is supposed to have that font. All elements after calling that function will be defined with the new font. You may also wrap that call into a macro for convenience. #define FONT(name) nk_style_set_font(ctx, &name->handle)
The result when defining your GUI may then look something like this:
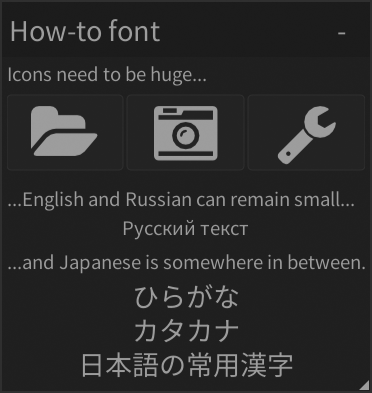
FONT(latin);
nk_layout_row_dynamic(ctx, 20, 1);
nk_label(ctx, "Icons need to be huge...", NK_TEXT_LEFT);
FONT(icons);
if (nk_button_label(ctx, "")){
[...]
}
FONT(japan);
nk_label(ctx, "ひらがな", NK_TEXT_CENTERED);This may become cumbersome if you need more complex UIs. In that case it's up to the user to create an abstraction level higher, than is provided by default. For instance you may wrap nk_label_colored() in a macro or function, which takes the font as a parameter.
Working with multiple languages? Use nk_begin_titled(), not nk_begin() when specifying window names. The reason is, that the window names are used as hash keys to address the window. Keep the window names ASCII only and use the title parameter to go wild with Unicode window titles.
stb_truetype causes blurriness to the text under certain circumstances. Thus Nuklear suffers from slightly blurry text in its default configuration if you are unlucky, especially when compared to the sharp and pixel perfect default ProggyClean.ttf. This is in small part because character hinting is not used, but the main cause is some (to me) unknown interaction of certain font sizes with stb_truetype's algorithm. Blurry text issues have been reported multiple times in both repos over the years. Luckily this can be fixed, without switching font handlers. Choosing the correct font size is the single biggest factor in how sharp your font is perceived, without resorting to heavy oversampling.
Insert the baking process into your main rendering GUI loop, add a float property and connect it to the float size. Obviously only for testing and not the finished GUI, as we absolutely kill performance doing this. Using the GLFW backend, this look like this in my case:
if (nk_begin_titled(ctx, "demo", "oversample h=1 v=1, pixel_snap on",
nk_rect(1, 1, 380, 380),
NK_WINDOW_BORDER|NK_WINDOW_MOVABLE|NK_WINDOW_SCALABLE|
NK_WINDOW_MINIMIZABLE|NK_WINDOW_TITLE)){
nk_layout_row_dynamic(ctx, 40, 1);
static float font_size = 27.5;
nk_property_float(ctx, "Font size:", 0, &font_size, 100, 0.01, 0.01);
nk_glfw3_font_stash_begin(glfw, &atlas);
latin = nk_font_atlas_add_from_memory(
atlas, (void *)NotoSansCJKjp_Regular_otf.pnt,
NotoSansCJKjp_Regular_otf.size, font_size, &cfg_latin);
nk_glfw3_font_stash_end(glfw);
nk_layout_row_dynamic(ctx, 20, 1);
nk_label(ctx, "ASCII only Test string... @ # ! $", NK_TEXT_LEFT);
}
nk_end(ctx);Now you may click and drag the Nuklear property to find the sizes, that appear sharp to you. Initialize your fonts with those sharp values that you found.

To what extent the wrong font size can make your text appear blurry is especially visible in the following comparison GIF, where the Japanese Kanji go from sharp to being a blurry mess. Keep your eyes peeled for detecting artefacts that come from stb_truetype's baking algorithm and avoid the font sizes, that cause them. In the GIF below you can see sides of letters being cut off, as compared to their neighbouring letters. Especially bad is letter B in "Bad", which has it's bottom side cut off by a pixel. These luckily only happen on sizes, that are also blurry.

There appears to be no rime or reason as to which which sizes are sharp and which are blurry. But there is some logic to it: Sharp sizes should be specified down to 0.05 font size steps. That is the smallest amount of size change, that I perceive a sharpness difference in. Sharp steps usually come in integer steps as well. For instance, 27.25, 32.25, 37.25 etc. for a font may all appear sharp. This integer step changes from font to font and is nothing to be relied upon however, so just test the font and write down the sharp sizes.
Nuklear allows you to set struct nk_font_config.pixel_snap = true;.
This rounds the float glyph->xadvance to the nearest integer. xadvance is the amount that character's texture is horizontally incremented, when placed by Nuklear. This is a feature of Nuklear and doesn't change stb_truetype's baking process. As such, the font atlas remains identical.
xadvance values go from this:
10.646959, 13.322636, 12.393581, 17.949324, 18.135136, 14.939189, 16.555744, 12.040541, 11.854730, 18.841217, 12.059122, 10.479730, 11.297297, 10.535473, 8.528716, 11.037162, 10.293919, 14.121622, 9.476352, 11.724662, 11.724662, 10.331081, 11.000000, 13.136825, 11.668919, 11.260136, 11.483109, 11.520270, 9.457770, 9.532095, 9.680743, 15.236486, 9.253379, 11.501689, 10.628379, 15.552365, 15.701014, 12.356419, 13.991554, 10.182432, 9.457770, 15.310811, 10.665541
to this:
11.000000, 13.000000, 12.000000, 18.000000, 18.000000, 15.000000, 17.000000, 12.000000, 12.000000, 19.000000, 12.000000, 10.000000, 11.000000, 11.000000, 9.000000, 11.000000, 10.000000, 14.000000, 9.000000, 12.000000, 12.000000, 10.000000, 11.000000, 13.000000, 12.000000, 11.000000, 11.000000, 12.000000, 9.000000, 10.00000, 10.00000, 15.000000, 9.000000, 12.000000, 11.000000, 16.000000, 16.000000, 12.000000, 14.000000, 10.000000, 9.000000, 15.000000, 11.000000
![]()
The pro of doing this, is improved sharpness by forcing all glyphs to be pixel aligned. Otherwise, when placing glyphs as defined by the sub-pixel positions of the font, the GPU's bilinear filtering interpolates the pixel values and the sharpness decreases if a glyph has a particularly unlucky sub-pixel placement in a string. The sharpness improvement is especially visible in the "lis" of the word "English" and 語. Moreover this prevents small sampling artefacts in the case of no oversampling and non-pixel aligned glyphs. Eg. the "h" in "English" and "a" in "...and J" appear to be cut off at the right side. The con of doing this, is that it changes the character spacing as defined by the font, visualized by the horizontal "jumping" you see in the gif. The icons remain unaffected, since the first character of a string is always placed on an integer coordinate and the icons are a single character.
As mentioned by the documentation, oversampling should be disabled if Pixel snap is enabled. (Contrary to the doc, only horizontal oversampling needs be this disabled. Though mixing vertical oversampling and pixel snap is a use case I don't see the upside of) If horizontal oversampling is enabled, then the GPU has actually something to sample against when doing bilinear interpolation, cutting down on the perceived sharpness loss and eliminating the cut-off artefact if no pixel snap is used. But you pay with 3x GPU memory cost. As already mentioned, Nuklear's default font config enables 3x horizontal oversampling, which seems to be a good sweet spot. Enabling Pixel snap together with horizontal oversampling barely changes sharpness, but still messes with Glyph positioning. It is thus discouraged as per the doc.
![]()
Carrying this to the logical conclusion: What is better, default 3x horizontal oversampling + no pixel snap or no oversampling + pixel snap?
![]()
Not much of a difference in terms of sharpness. So I'd say go with PixelSnap + no oversampling for more memory headroom.
Font files, especially the ones covering the Chinese, Japanese and Korean Characters (commonly referred to as CJK), like Google's Noto in its CJK variants, quickly become large in size. 20mB font files are rather common if you don't limit yourself to western languages. This clashes with Nuklear's goal of a lean, statically compiled nature and the ability to target embedded platforms. Here we have a couple of options to greatly reduce the filesize of the font.
Subsetting fonts using PyFT's subset command
Download and install Python FontTools using pip. pip install fonttools. This gives you access to the pyftsubset command. If you need to subset WOFF 2.0 fonts (to later convert into ttf or otf for inclusion in Nuklear) install with pip install fonttools[woff]. Link to the documentation.
Now we can subset our font files and greatly drop the size of our final program. Let's say we only need English (ASCII U+0020-007E), German+Common Symbols (U+00A0-00FF) and Russian (U+0400-04FF).
pyftsubset NotoSansCJKjp-Regular.otf --unicodes="U+0020-007E, U+00A0-00FF, U+0400-04FF" --no-hinting
In case of Google's full Noto CJK the size goes from 16MB to 32KB. Now that's a drop!
stb_truetype.h does not use hinting. As such we can fully strip out all hinting information with --no-hinting, dropping the final filesize by an additional 15%.
We can also specify unicode codepoints with files. For instance, using this file, we can add just the Jōyō kanji for Japanese.
pyftsubset NotoSansCJKjp-Regular.otf --unicodes-file=joyo-kanji-unicode-pyftsubset.txt --no-hinting
The same goes for icon fonts as well, as mentioned in the Icons chapter above.
We can of course keep the font file on the disk and access it as per usual, but keeping everything in a single program makes for easier deployment. This opens a vast array of "embedded resources" options. Here are a couple ways of doing this:
- You may encode your file in base85 and paste it directly into your source, as Nuklear provides the ability to directly add base85 encoded font files via nk_font_atlas_add_compressed_base85() and is the way how Nuklear provides the default font. However, the binary -> ASCII conversion carries a 25% size increase penalty.
- A more elegant version is to command your linker to append the font file to your final binary. First convert your font file into an object file. With the GNU Toolchain this can be done via
ld -r -b binary -o font.o font.ttfand with the LLVM/clang toolchain we have to specify the target architectureld -r -b binary -m elf_amd64 -o font.o font.ttf. Now you may link this resulting object file during compilation. In the source, you may usenk_font_atlas_add_from_memory()to load the font file now. The pointer to the font file comes in the form ofextern const char _binary_font_ttf_start[];and the size is found via_binary_font_ttf_end - _binary_font_ttf_start. (You may not use the size symbol after linking because of PIE) The exact names of the symbols can be verified with the program nmnm font.o. My Makefile for instance puts all files that are in my resource folder into a res.o and outputs a res.h with the symbols and sizes pulled from nm to access them. Setting up something similar can make this a convenient drag&drop workflow. - If you come from the future and proposal N2592 made it into the C23 standard, you can use C23 to #embed your file directly without messing around with the linker.
- With Windows' Visual C/C++ toolchain this is done via the Windows Resource format, where you specify the symbol name you access it with in the rc textfile. Visual Studio allows you to do that within it's IDE and the same format is provided in MSYS via windres.exe. You may actually mix Windows' resource format and the ld format in the same program with the MSYS+MinGW64 toolchain. So if you compile your program using MINGW64 on windows, you may use the Windows style resource file to give your program an Icon and continue using the GNU Toolchain to link your font, making it easy to support *NIX and Windows ports of your program.
Font files compress quite well. You may use the classic zlib to compress the file before including it as a binary and decompress it before giving it to nk_font_atlas_add_from_memory(). The Noto Font mentioned above, subset with German, Russian and Japanese and no hinting information, results in a 1.5MB .ttf file and 1.1MB .otf file. Zlib compresses the ttf file to 882KB and the otf file to 916KB. A more modern solution, but also with a bigger code-base is Facebook's ZSTD, though the sizes only decrease by a further 50KB.
Finally, you may skip manual compression and just use UPX to compress your whole program, which includes the appended font binary. This allows you to use LZMA compression and completely ignore the need for decompression. An unfortunate side effect is that AntiVirus programs may or may not flag your program. When trying it out with a hello world program, please note that UPX will not compress a program, with a too small .text (your source code) section. Even if you include 100MB of resources, UPX will not compress your program, if there is only hello world for source code.