Incremental View over Xtext Models
EMF-IncQuery includes a view generation component called Viewers, that is built up as an incremental, one-way synchronization transformation to a notation model, and various UI components (list, table or graph-based) that display this notation model automatically. The transformation itself is driven by a set of IncQuery patterns annotated with some specific annotations. This approach allows efficient updates in the user interface as the view generation transformation has very specific information about the changes in the model.
Generating views from Xtext-based models is different from other EMF-based models (e.g. UML models in Papyrus) for two reasons:
- When a file is edited, a large part of the corresponding AST is be rebuilt, even on very small changes. This means, having a simple traceability model that tracks the instances of the AST using direct object references (like in case of EMF-IncQuery Viewers) can be impractical, as the view model needs to be constantly updated for the newly created AST versions.
- Xtext best practices suggest to split large models into multiple, smaller files. This modularizes the language, giving a better understanding of the models itself. Furthermore, it also provides performance benefits, as a dedicated index can be used to decide whether a cross-file reference can be resolved without opening and parsing the referenced files. However, from a view generation standpoint this is problematic, as relevant updates can happen in several different editors, thus different resources; in other words, EMF-based notifications can be incomplete.
These differences mean that the strategy used by IncQuery Viewers is not always the best way to provide views. In the following, we identify use cases, and outline possible solutions for the view generation problem. The cases differ on how the view models are constructed, and what events trigger their refresh.
One approach would be use an open Xtext-based editor as the context for the created view: model elements available from the current editor via references are considered, others not. This approach is useful for visualizations that rely on mostly the currently edited file, especially as it is possible to display information about the currently edited/selected part of the file as well. Furthermore, as we have an instance of the AST open, it can be reused via any EMF-based tool.
- Strong points:
- IncQuery Viewers or other EMF-based view generation approaches can be reused.
- View can react to changes in the editor as soon as its typed.
- Known issues and limitations:
- Theoretical: how to handle changes in a file the currently file depends on? As the changes happen in a different editor (thus a different ResourceSet), EMF-based notifications from different files might be missing.
- Implementation level: Xtext sometimes turns off EMF notifications for performance reasons. We are working on a patch for this issue, and are planning to contribute it to Xtext.
- Implementation level: as the user enters text into the model, the model goes through a lot of inconsistent states, e.g. references cannot be resolved until their name is written down entirely. Furthermore, the update itself might require the change of multiple notifications, during which it makes no sense to update the graphical view. For this reason, the IXtextDocument interface available for each Xtext editor allows to add an IModelListener instance that is called when all changes related to the latest edit have been completed.
As an example for this kinds of view models, consider the Outline or Properties views available for Eclipse editors: they display information about the currently opened or selected elements, but do not traverse the model into other files, thus avoiding the pitfalls of this approach while still providing useful information during editing.
If a model is split up into separate files, it makes also sense to provide view models that display the global status of the model, such as the call hierarchy between the elements. Xtext uses a builder component that makes an index up-to-date with the models with qualified names, type and possibly other, language-specific information available without the need to for the files themselves being opened.
-
Strong points
- Possible to provide a consistent view from a model split into multiple files.
- If the information stored in the Xtext index is enough, no Resources are to be loaded to display/update the view model.
-
Known issues and limitations
- Theoretical: it is not possible to incorporate the currently opened editor contents without them being saved, as unsaved changes are not propagated between files in Xtext, thus they might be inconsistent with each other.
- Implementation: the Xtext Index does not contain all elements from the model, only ones that can be referenced from other files via a qualified name. This can only be changed by the language developer itself.
- Implementation: approaches that traverse the AST are not really applicable without loading the entire model.
The various Open functionalities, like the Open Type, in the JDT rely on a similar indexed approach to keep its content up-to-date and easily accessible. Similarly, this indexed model is used to display Call hierarchy.
The following figure describes the internal data model of the Xtext index:
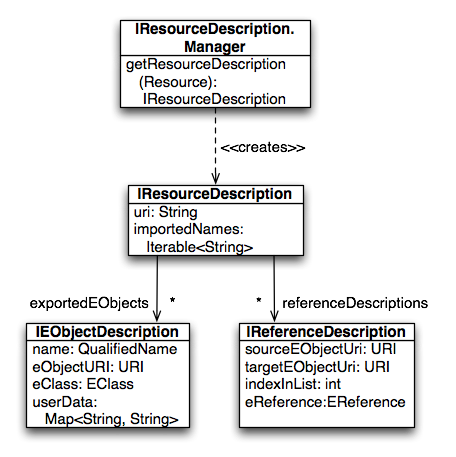
The Manager is the top level component of the index, that stores resource descriptions, representing files. A resource description exports a set of object descriptions that describe objects that can be referenced from another file using a Qualified name. Furthermore, it contains Reference Descriptions to describe all elements that are imported/referenced from another resource.
The EObjectDescription instances do not contain any direct references to the EObject instance it was created from; but it contains enough information to resolve from the resource if required. It is also possible to store language-specific information in the userData field, but there is no language-independent way to process this information. If some additional information not stored in the index is required, the backing resource needs to be resolved, and the results processed. This is in line with the indexing mechanism of JDT, where the Java Object Model contains the high level structure of the Java files; and an AST can be parsed by opening the backing model.
It is also possible to get notifications from index changes, where a change event can be described using the following interfaces:
/**
* A delta describing the differences between two versions of the same {@link IResourceDescription}. Instances have
* to follow the rule :
* <p>
* <code>getNew()==null || getOld()==null || getOld().getURI().equals(getNew().getURI())</code>
* </p>
* and
* <p>
* <code>getNew()!=getOld()</code>
* </p>
*
*/
interface Delta {
/**
*@return the uri for the resource description delta.
*/
URI getUri();
/**
* @return the old resource description, or null if the change is an addition
*/
IResourceDescription getOld();
/**
* @return the new resource description, or null if the change is a deletion
*/
IResourceDescription getNew();
/**
* @return whether there are differences between the old and the new resource description.
*/
boolean haveEObjectDescriptionsChanged();
}
interface Event {
/**
* @return the list of changes. It is never <code>null</code> but may be empty.
*/
ImmutableList<Delta> getDeltas();
}To summarize, a change Event contains a list of Delta instances, while a Delta describes all changes in a single resource. It has the old and new version of the Resource Description, so it is possible to calculate a change from it. However, it is important to note that it is not possible to resolve the references for the old version, as the old version of the backing resource is not available anymore. In other words, the event handler has to make sure the traceability information are keyed using the contents of the index instead of the AST of the language.
The Github repository incquery-evm-xtext contains a prototype integration of the event-driven virtual machine (EVM) used by EMF-IncQuery and VIATRA that uses the Xtext index as an event source.
Considering the various aspects, we have identified two event models using the Xtext index:
- The Xtext index contains all information required for the view definition (e.g. we want to list all classes inferred from Xbase languages), the Xtext index events contain enough information, and the view can be defined easily. For this to work, we have to react to object change events.
- The view uses additional information information only available in the abstract syntax tree, but we want to update the view if the model changes. By receiving notification for resource change events, it is possible to limit what part of our model needs to be updated.
An important aspect of EVM is that it separates event receiving and event handling, thus it is possible to only fire transformation rules when the input model is in a consistent state (e.g. in case of Xtext, the Xtext builder is not running, or manual updates).
The following figure depicts how the Xtext-EVM integration works:
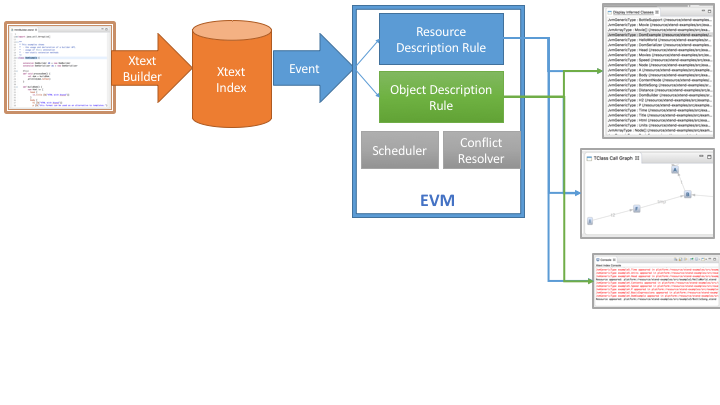
After a file is changed in a project with the Xtext nature, the Xtext builder is triggered. This builder has multiple responsibilities: in addition to creating the generated code, it also makes sure that the Xtext index used for resolutions is up-to-date.
The EVM instance can register listeners on the Xtext Index, thus receiving Xtext Event instances. These Events are converted into EVM-specific internal events of two categories: resource description changes and object description changes. When creating an application over EVM, these events are handled by corresponding rules.
Furthermore, EVM provides two additional components to specify the execution of the rules: schedulers and conflict resolvers. The scheduler is responsible for triggering rule executions - it is expected that rules are triggered only when the environment is in a consistent state. We have a scheduler instance available that schedules rule execution every time a build is completed. A conflict resolver is used to specify rules of how to select the next rule to activate - e.g. based on priorities.
To illustrate how to set up rules, lets consider a simple logging example that prints out every model change automatically.
An example for defining a rule that reacts to resource change events can be done as follows by printing the change to the standard output:
resourceRule.action(XtextIndexActivationState.APPEARED) [
println("Resource appeared: " + it.URI)
].action(XtextIndexActivationState.UPDATED) [
println("Resource updated: " + it.URI)
].action(XtextIndexActivationState.DISAPPEARED) [
println("Resource disappeared: " + it.URI)
].buildA similar example for a rule that reacts to object change events (note that each lambda has now two parameters):
objectRule.action(XtextIndexActivationState.APPEARED) [resource, object |
println('''«object.EClass.name» «object.name» appeared in «resource.URI»''')
].action(XtextIndexActivationState.UPDATED) [resource, object |
println('''«object.EClass.name» «object.name» appeared in «resource.URI»''')
].action(XtextIndexActivationState.DISAPPEARED) [resource, object |
println('''«object.EClass.name» «object.name» appeared in «resource.URI»''')
].buildIn order to demostrate how this approach works, we have set up three further examples that reuse the same event-driven virtual machine, but can be set up one by one separately. The first example is a Console logger: a rule that logs all events to the Console view. The second example presents all inferred JVM types as a list in a separate view: this example uses only information directly available in the Xtext Index, thus it does not require to load the models. Finally, a graphical view is created for a specific programming language, that draws a call graph between different elements. To find these connections, the EMF-based IncQuery Viewers framework is reused; and the Xtext-EVM integration is used to make sure that all required elements are loaded and updated correctly for the viewer.
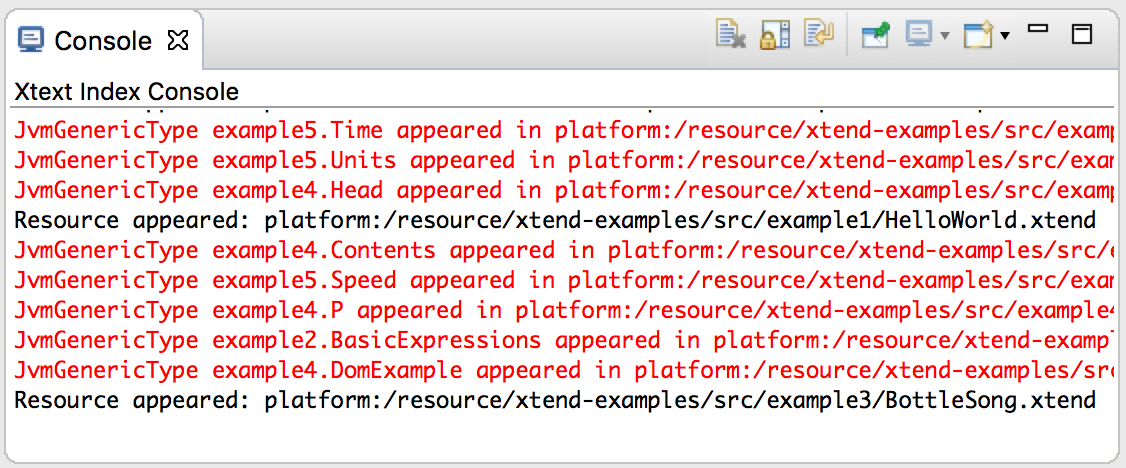
The console example is basically the same as the logger presented before, but with some wrapper code to work in the Eclipse console view instead of the standard output.
To start this example, execute the following steps:
- Open the Console view (available in the General category)
- Click on the Open console button in the view, and select 'Xtext-EVM Index Console'
- After the build has finished, the console will display the logged resource and event changes
A more complex example is used to update a JFace Viewer in case of the Xtext Index changed. This example uses two more aspects of EVM:
- An event filter is defined that filters notifications where the modified Object Description is not of a selected EClass (see line 40-41).
- To make sure the user interface is updated correctly in the user interface thread, the rules use
Display#syncExecto switch threads (see line 58 and line 62).
To start this example, execute the following steps:
- Open the Display Inferred Classes view (available in the Xtext-EVM integration category).
- Have a project with xtend files in the workspace. The most simple way to achieve this is to generate the xtend-examples project using File/New/Example... and select the Xtend Introductory Examples option.
- After the build finishes, the Display Inferred Classes view should be filled with references to all known inferred java types.
The following screenshot describes how this view looks like:
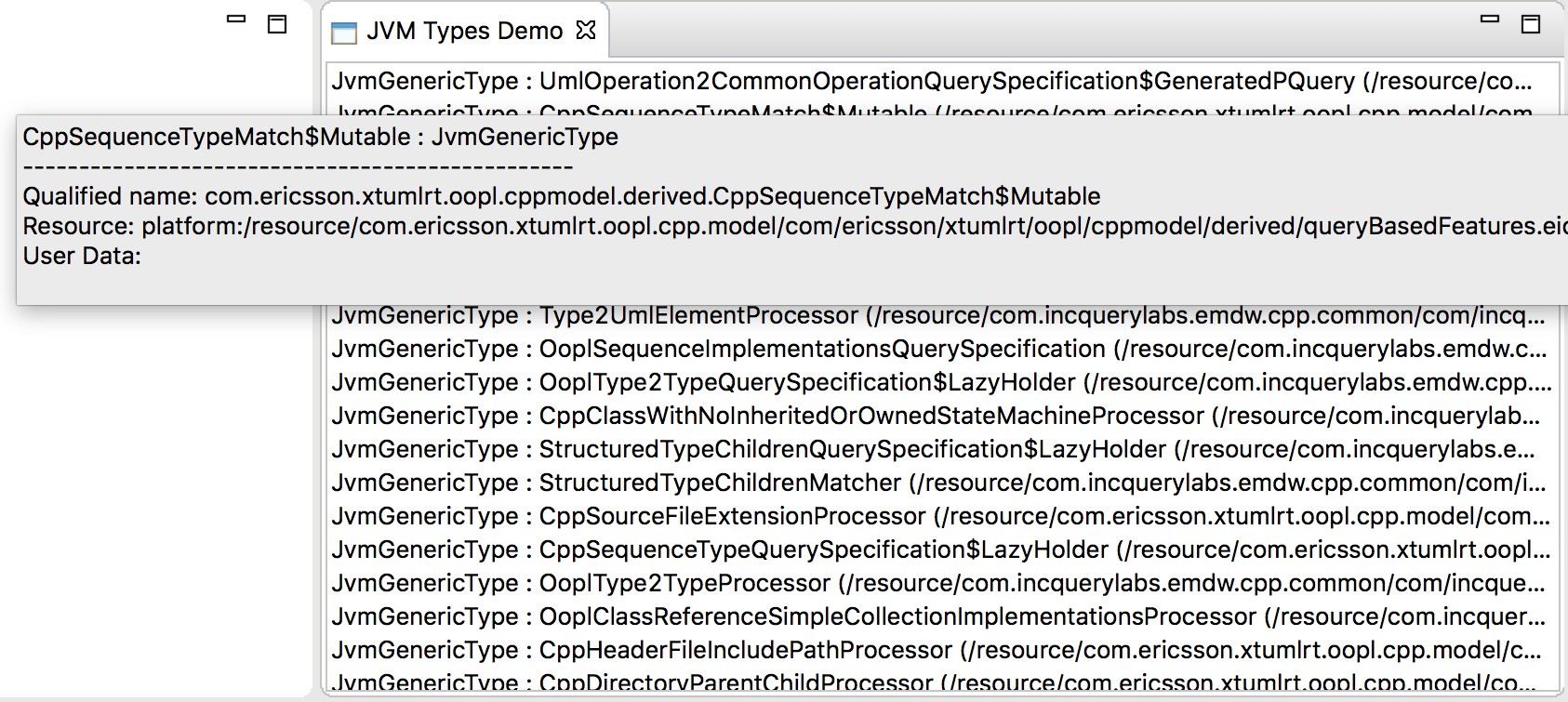
It is important to note that the view contains very limited domain specific information: it only features information that is directly available in the Xtext index (qualified name, type and location); but it does not require opening the files themselves, thus provide quick updates.
The final, most complex example describes the globally visible state of a model, but relies on information not available in the Xtext Index. In general, the example works by loading all models that export an EObject with the type TClass (as defined in the Example Language included) into a ResourceSet; and then making sure these resources are updated when the underlying model changes.
It is important to note, that the ResourceSet of the example is not connected directly to any editor at all, but opens a second instance to display; however, after a model file is saved, the result is updated correctly.
There are two specific EVM rules implemented: an object rule that is responsible to ensure a model file exporting a TClass is loaded; and a resource rule to load/unload/reload the resources that were changed.
There are two new ideas presented in this example:
- The rules are ordered by priority: all object rules are evaluated before the resource rules are considered. This allows the object rules to to prepare all resources into the ResourceSet.
- IncQuery Viewers is used on the managed ResourceSet, that uses an EMF-based EVM instance to display the contents effectively.
The following screenshot shows this example in action:
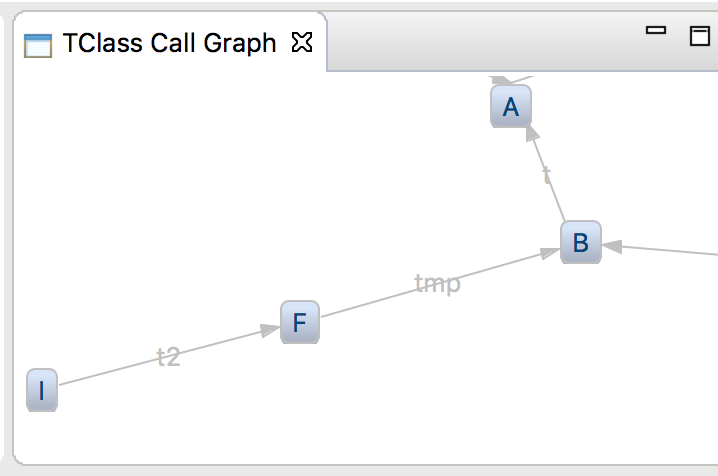
To start this example, execute the following steps:
- Open the TClass Call Graph view (available in the Xtext-EVM integration category)
- Have a project with models of the example language (included in the repository)
- Notice that the call graph view updates after the builder has finished execution