info
本章实现scrapy爬虫框架爬取51jobs网pyhton岗位求职信息并将数据保存到csv文件和MySQL数据库中, 博客地址https://blog.csdn.net/weixin_43347550/article/details/106029283
我们先来看一下:51jobs网站
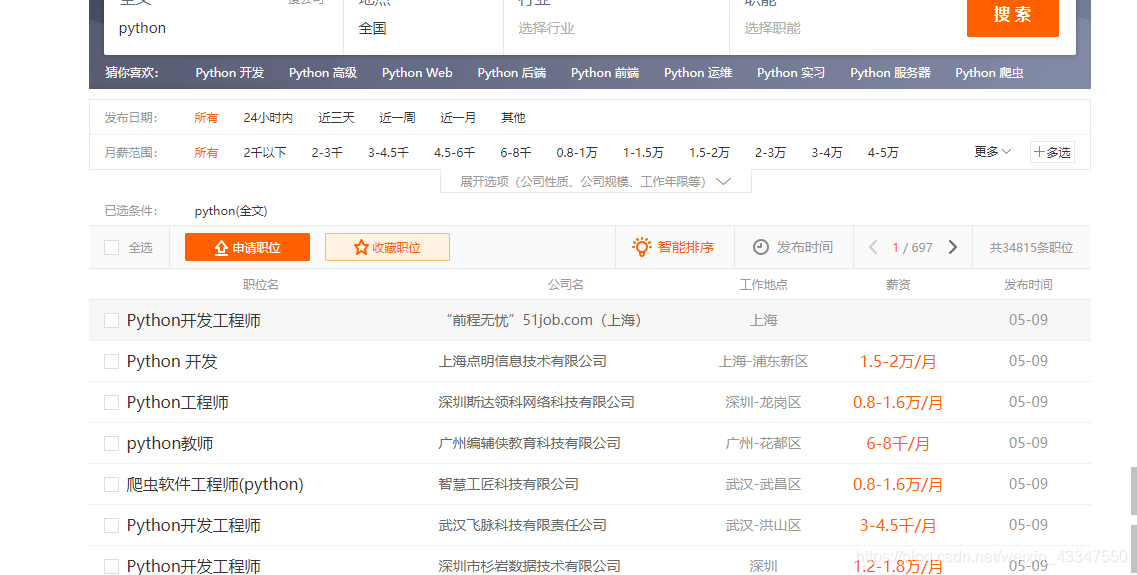

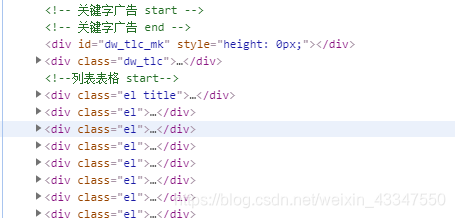
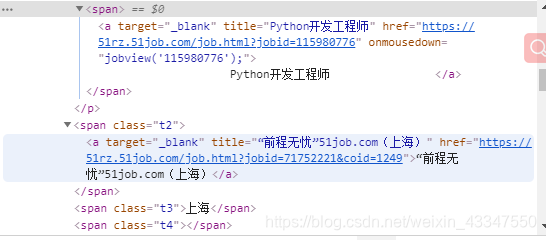
使用命令scrapy startproject tongscrapy 来创建一个scrapy框架。
然后使用scrapy crawl py51jobs https://search.51job.com/list/000000,000000,0000,00,9,99,python,2,1.html 来创建一个spider项目。
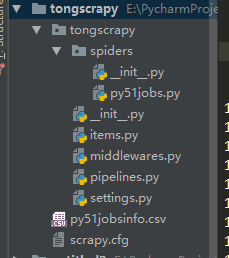
完成这些后打开 pycharm,将创建的项目,添加到pycharm中。
如下图所示:
class Py51jobsSpider(scrapy.Spider):
name = 'py51jobs'
#allowed_domains = ['51jobs.com']
start_urls = ['https://search.51job.com/list/000000,000000,0000,00,9,99,python,2,1.html']
def parse(self, response):
item = TongscrapyItem()
for i in range(4, 45):#每页共有40条数据
item['position'] = response.xpath('//*[@id="resultList"]/div[{num}]/p/span/a/text()'.format(num=i), first=True).extract_first().strip()
item['company'] = response.xpath('//*[@id="resultList"]/div[{num}]/span[1]/a/text()'.format(num=i), first=True).extract_first()
item['place'] = response.xpath('//*[@id="resultList"]/div[{num}]/span[2]/text()'.format(num=i), first=True).extract_first()
item['salary'] = response.xpath('//*[@id="resultList"]/div[{num}]/span[3]/text()'.format(num=i), first=True).extract_first()
print('抓取完毕一条')
yield item
for i in range(2, 10): #抓取页数,可自行更改
url = 'https://search.51job.com/list/000000,000000,0000,00,9,99,python,2,'+str(i)+'.html'
yield scrapy.Request(url, callback=self.parse)
print('抓取完毕一页')class TongscrapyItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
position = scrapy.Field()
company = scrapy.Field()
place = scrapy.Field()
salary = scrapy.Field()# 数据存储在csv文件里
class savefileTongscrapyPipeline(object):
def __init__(self):
self.file = open('py51jobsinfo.csv', 'w', newline='')
self.csvwriter = csv.writer(self.file)
self.csvwriter.writerow(['职位名称', '公司名', '地点', '薪资'])
def process_item(self, item, spider):
self.csvwriter.writerow([item["position"], item["company"], item["place"], item["salary"]])
return item
def close_spider(self, spider):
self.file.close()
# 数据存储在MySQL数据库里
class mysqlTongscrapyPipeline(object):
# 采用异步机制写入MySQL
def __init__(self, dppool):
self.dppool = dppool
# 用固定方法 【写法固定】 获取配置文件内信息
@classmethod
def from_settings(cls, settings): # cls实际就是本类 MysqlTwistedPipeline
dpparms = dict(
host=settings["MYSQL_HOST"],
db=settings["MYSQL_DBNAME"],
user=settings["MYSQL_USER"],
passwd=settings["MYSQL_PASSWD"],
charset="utf8",
cursorclass=MySQLdb.cursors.DictCursor, # 指定 curosr 类型 需要导入MySQLdb.cursors
use_unicode=True
)
# 由于要传递参数 所以参数名成要与connnect保持一致
# 用的仍是MySQLdb的库 twisted并不提供
# 异步操作
# adbapi # 可以将MySQLdb的一些操作变成异步化操作
dppool = adbapi.ConnectionPool("MySQLdb", **dpparms) # 告诉它使用的是哪个数据库模块 连接参数
# 另外 以上dpparms的参数也可单独写,这样会造成参数列表过大
return cls(dppool) # 即实例化一个pipeline
def process_item(self, item, spider):
# 使用twisted将mysql插入编程异步操作
# 指定操作方法和操作的数据 [下面会将方法异步处理]
query = self.dppool.runInteraction(self.do_insert, item)
# AttributeError: 'Deferred' object has no attribute 'addErrorback'
# query.addErrorback(self.handle_error) # 处理异常
query.addErrback(self.handle_error) # 处理异常
def handle_error(self, failure):
# 定义错误 处理异步插入的异常
print(failure)
def do_insert(self, cursor, item):
"""
此类内其他都可以看作是通用 针对不同的sql操作只需要改写这里即可了
:param cursor:
:param item:
:return:
"""
insert_sql = """insert into py51jobsinfo(position, company, place, salary)
values (%s, %s, %s, %s)"""
cursor.execute(insert_sql, (item["position"], item["company"], item["place"], item["salary"]))
return itemBOT_NAME = 'tongscrapy'
SPIDER_MODULES = ['tongscrapy.spiders']
NEWSPIDER_MODULE = 'tongscrapy.spiders'
ROBOTSTXT_OBEY = True
ITEM_PIPELINES = {
#注意后头的参数是通道运行顺序,两个要不相同,不然会出错。
'tongscrapy.pipelines.savefileTongscrapyPipeline': 300,
'tongscrapy.pipelines.mysqlTongscrapyPipeline': 500,
}
#Mysql数据库的配置信息
MYSQL_HOST = '192.168.1.106' #数据库地址
MYSQL_DBNAME = 'quanluo' #数据库名字
MYSQL_USER = 'root' #数据库账号
MYSQL_PASSWD = '123' #数据库密码
MYSQL_PORT = 3306 #数据库端口使用代码:scrapy crawl py51jobs
运行结果为(展示最后部分):
2020-05-09 23:24:08 [scrapy.core.scraper] DEBUG: Scraped from <200 https://search.51job.com/list/000000,000000,0000,00,9,99,python,2,4.html>
None
抓取完毕一页
抓取完毕一页
抓取完毕一页
抓取完毕一页
抓取完毕一页
抓取完毕一页
抓取完毕一页
抓取完毕一页
抓取完毕一页
抓取完毕一页
抓取完毕一页
抓取完毕一页
抓取完毕一页
抓取完毕一页
抓取完毕一页
抓取完毕一页
抓取完毕一页
抓取完毕一页
抓取完毕一页
抓取完毕一页
抓取完毕一页
抓取完毕一页
抓取完毕一页
抓取完毕一页
抓取完毕一页
抓取完毕一页
抓取完毕一页
抓取完毕一页
抓取完毕一页
抓取完毕一页
抓取完毕一页
抓取完毕一页
2020-05-09 23:24:08 [scrapy.core.engine] INFO: Closing spider (finished)
2020-05-09 23:24:08 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 7745,
'downloader/request_count': 10,
'downloader/request_method_count/GET': 10,
'downloader/response_bytes': 208750,
'downloader/response_count': 10,
'downloader/response_status_count/200': 9,
'downloader/response_status_count/404': 1,
'dupefilter/filtered': 64,
'elapsed_time_seconds': 8.845924,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2020, 5, 9, 15, 24, 8, 227376),
'item_scraped_count': 369,
'log_count/DEBUG': 380,
'log_count/INFO': 10,
'request_depth_max': 2,
'response_received_count': 10,
'robotstxt/request_count': 1,
'robotstxt/response_count': 1,
'robotstxt/response_status_count/404': 1,
'scheduler/dequeued': 9,
'scheduler/dequeued/memory': 9,
'scheduler/enqueued': 9,
'scheduler/enqueued/memory': 9,
'start_time': datetime.datetime(2020, 5, 9, 15, 23, 59, 381452)}
2020-05-09 23:24:08 [scrapy.core.engine] INFO: Spider closed (finished)