Kong throws 404 not found on route paths that exist at times. #4055
Comments
|
We were able to reproduce again with predictability. 6 Worker processes too do note.
What does this mean? I believe Kong needs to implement router rebuild mutex in place so as Kong figures out changes to routes it has a temp cache to leverage of all the "existing" routes during the window of rebuild(I think @p0pr0ck5 implemented a mutex like this around Service resource create/updates/deletes for Kong 1.0 ). Some interesting thoughts trailing off on this though as well. IF it was just the instance in time of rebuild that had issue why did we see existing routes like our /F5/status endpoint persist the 404 no route found error with certain worker processes? Maybe a timing thing or Kong invalidly caches that bad "miss" as a truth and continues to persist that miss even if its present in the db? I am not sure, but I believe the mutex lock would probably stop that from happening anyways. Let us know if we can provide you any further help but I think Kong will be able to reproduce at this point! UPDATE: Was told in gitter chat that 1.0RC3 has the router mutex in place. Will see if that resolves the described issues here. |
|
There's some interesting behavior in this that I don't know has been discussed before. The design goal of router rebuilds is to maintain a strongly consistent environment to avoid some worker processes sending different responses. Each worker maintains its own router, so rebuild events are done through the https://github.com/Kong/kong/blob/next/kong/runloop/handler.lua#L418-L421 These events are handled based on a polling mechanism, since there's no direct inter-worker IPC mechanism available at this time (well there is via a third part module, but nothing that's provided as a first-class OpenResty primative): https://github.com/Kong/kong/blob/next/kong/init.lua#L432 At a given time, some worker processes may 'see' the event broadcast and act by forcing a router rebuild, and other worker processes will not yet have polled the shared zone. It's an incorrect assumption that all workers will handle an event at the exact same time. There will be some drift between workers handling events, so the behavior that you're seeing here is expected; it a nature of relying on a polling mechanism inside a shim to broadcast events among all workers. It's been long known that the current solution is sub-optimal for cases like this, but again, a true IPC solution requires some major under-the-hood work. A node-wide router definition might solve some problems, but as discussed before raises other issues and concerns (memory limitations, deserialization, etc). BTW, the router rebuild mutex would not solve this at all. The goal of that work is to avoid stampeding the database in high-concurrency traffic situations when a router rebuild is required, but it still relies on the same polling mechanism, so the race-y behavior seen here would likely still manifest. |
|
Uh oh. Well that is unfortunate, guess the best way to solve this would be an inter-worker IPC mechanism then. Maybe in the mean time there could be a patch in place until Kong/OpenResty can get there with the IPC, that in the background compares whats in the router cache vs db and invalidates the router if mismatches are detected maybe based on a configurable timer, maybe reconciles once a minute or so (I hate this approach so don't go with this lol)? Does not sound like a bug that can be fixed by 1.0 release then, but do keep us posted if anything comes out of it or an elegant alternative approach takes shape in the meantime. Edit - Another idea could be worker processes reconciling service + routes against each other in a given interval setting on a per node basis over evaluating against the DB. Anything to help prevent the 404's from persisting would be my biggest concern until a better solution can be found. I think for now we will limit changes to our Kong environments in prod to once nightly and use a script we whipped up to ensure no 404's are present post change. |
|
Updates: Was talking on Kong public gitter, and I mentioned that I had been unable to reproduce in dev with very few Kong Service+Route+Consumer+Plugin pairs. This held true, when I have fewer than say 10 total services and consumers and such I could never reproduce the error. I decided to ramp things up a tad by adding 500 Service+Route pairs, where the Route had the ACL plugin enabled with whitelist entry being the route id and Oauth2 plugin enabled, Also created a consumer to each route with an acl group tied to route id, as well as giving the consumer a pair of oauth2 and jwt creds for kicks(mimics how I handle all created consumers internally). After getting those resources in place to put a little meat on Kong's bones, I then ran a 100 TPS loadtest against our health check endpoint. It became easily producible then while adding service+route pairs during the load test to see the 404's once more, so it certainly seems Kong in its current form must have a breaking limit on # of resources the current internals can handle before things go a bit haywire. Granted I was not able in this short time of testing in my dev environment to "persist" the 404's like I have also seen occasionally in Stage(which stay throwing 404's until a service+route rebuild gets manually enforced), so a special sort of timing/race condition must have to occur that causes the 404 to persist. Each green bar spike of 404's are when when service/route pairs were created in dev manually.
|

|
This almost sounds like a race condition when a new DAO iterator runs in multiple concurrent request handlers, because each page iteration results in thread-yielding network I/O. The end result would be that the request handler that writes the final version of the router cache value incorrectly assumed itself to have been completed. I haven't been able to track down exactly where that might occur, but it doesn't sound out of the realm of possibility at this point. In a wonderful showcase of hat eating, I suspect that the router rebuilding mutex in place in the release candidates actually would solve this, because only one instance of the iterator would be executing at a given time inside a worker. @jeremyjpj0916 have you had a crack at testing this against 1.0 RC2/RC3 yet? |
|
😄 @p0pr0ck5 don't be giving me some false hope now hah. I was holding off testing RC3 after your first assessment stated you did not believe the mutex to be a fix for this behavior, but since it sounds like you think it may help I am pushing that testing forward to today as I consider understanding the issue critical to our Kong deployments stability(as our production will grow in resource/proxy count and see all the problems stage presents pretty regularly at the moment). Will post back here by late afternoon/tonight with my results of that testing! Edit - With rc3 throwing errors will await rc4's docker-kong git release and resume analysis then! |
|
@jeremyjpj0916 FWIW the router mutex logic made its way into RC2, so if you want to test on RC2 that would suffice for context here. |
|
@p0pr0ck5 good point, I will give that a go in an hour or so actually. Edit - nvrmind, I just remembered rc2 is where the migrations issue occurs where acl groups as a route uuid's(how we do thing internally) breaks the migrations commands(Thibaultcha patched that into the rc3 release). So guess ill wait on rc4 still 🎅 (if yall want to fix up RC2 or 3 with newer patches I can test that as well but might be better to focus on rc4 unless you consider me testing this a priority before 1.0). Edit Edit - well look at that 1.0rc4 is here :D, Christmas came early. If yall get that updated here I will test it asap: https://github.com/Kong/docker-kong Docker Kong info belowwww: ENV KONG_VERSION 1.0.0rc4 |
|
@thibaultcha @p0pr0ck5 100 TPS load test against our healthcheck endpoint yielded 100's of these this in the logs on the node taking the load(and even after load test finished the errors continually print every subsequent call too), Note every 4 seconds or so we added a route to an arbitrary service not currently under the load test on the same node being load tested. We then checked the other datacenter that was not taking any traffic and somehow it also ended up with these in its logs(albeit fewer of them, EDIT - but growing too now post loadtest) : Rather than 404's the errors manifest themselves in logs as 500 now: Gave a quick try in terminal too on the route path in the other data center on a separate node as well as we noticed it went down, meaning it started failing its health checks too with 500's(we were not even load testing this specific node nor do we have cluster wide rate limiting as a global or anything): I find the individual tx log interesting, why TotalLatency reported as 5 seconds on the dot? Any relation to KONG_CASSANDRA_TIMEOUT being set to 5000 in our environments? Note all my original config info from the admin API dump in my original post still holds true for the 1.0.0rc4 testing. Findings are as follows, we start seeing 500's under load and it didn't take long till those errors in the stdout started printing by the 100's and overwhelmed not only the node taking load test traffic in one datacenter, but somehow the other node in a totally different data center as well not taking any traffic besides 1 ping call every 3-5 seconds (the /F5/status endpoint just uses just the request termination plugin set to 200 success remember) was failing. Then still 10-20 minutes after the load test both of my nodes in either dc are unable to serve traffic on any routes, all of them throw the: And every call to any route like so above takes 5 seconds to respond it seems for that error. And the STDOUT logs reveal the same 20 minutes later I decided to see if there was anything in the db blowing up, locks was empty at the time and seemed like a new table. Nothing stood out to me major at a glance. If you need any further dumps or analysis let me know. I think this should be easily producible if you run a load test of 100 tps against an endpoint and make some changes to routes on your test node. What really stumps me is how does the independent node in the other dc not even taking traffic get similar rekt status lol, some sort of introduced internode-dependency?? Other things I just noticed, in the node taking the loadtest vs node in other dc just chilling, 2018/12/12 00:35:11 [error] 141#0 vs 2018/12/12 01:33:46 [error] 119#0: All 6 worker processes in the node under load are throwing the error still in stdout, in the other DC node that was not load tested only 2 of the 6 are throwing the error. |


|
I have seen this happening when running our testsuite. I have a feeling that it might be paging related. |
|
I will try something tomorrow and ping you back. |
|
When I was trying to reproduce this in the plane earlier, I hit a couple of other issues with the DAO that I am in the process of fixing. Unfortunately, traveling, and other thhings are getting in my way these days. Those issues that I found should be mitigated by the router mutex though. That said, I was not able to replicate your observations Jeremy. But as I am about to board another 12h flight, who knows, maybe I will have another chance at it, or @bungle will! Thanks for giving rc4 a spin. |
|
Looking forward to any improvements that can be made. Would love for Kong 1.0 to have the ability to be configured on the fly with no availability impact to active traffic(or persisted impact), and to do so with a few thousand proxies and consumers ideally. If I have any more findings will post them here, or if you have any lua file changes or config changes you want me to give a go let me know! I have a high degree of confidence yall will get it right with some tinkering 😸 . On a positive note I did notice the C* client connections when router changes were being made during load did not jump nearly as dramatically nor did the C* read latency results as compared to 0.14.1 vs newer 1.0.0rc4 so some improvements seem to showing at the high level. |
|
Leaving a very quick note here as it’s late and today I spent fire-fighting elsewhere. @jeremyjpj0916 thanks immensely for all your efforts in testing this. I see a bug in the router rebuild mutex handling that was introduced after the original change was committed. I will be digging into this tomorrow. |
|
No thanks necessary, I am overjoyed with the level of engagement you all have with the community, and its really awesome seeing the team iterate and improve on the product! Cheers to 1.0 nearing release as well as Kong's growth into 2019! Let me know when ready to test again and I will give it a go. |
|
I am not sure if this is an another issue, but I will leave a comment here too: Imagine you are rebuilding routes and rebuilder is on page 3. Someone adds a route or deletes a route on page 1. Now rebuilder should stop immediately and start again (I guess it does not do it?). Otherwise rebuilder itself produces a stale router, at least for requests that it has queued or at very least for the one request that is rebuilding the router currently (possibly per worker) |
|
@jeremyjpj0916 there is now pr #4084, we would greatly appreciate if you can check what effect it has on this issue. |
|
#4084 looks good. We should also fallback to rebuilding the router upon semaphore timeout (which the PR will definitely help preventing, but still a good safety measure to have). That said, the original issue was in the latest stable (0.14.1), so unless the router rebuild semaphore circumvents the issue, it is likely still there... I disabled the router semaphore on 1.0rc3 and ran a number of tests, but was unable to reproduce the issue you are seeing @jeremyjpj0916 (producing a 404 - router miss - upon router rebuild when a correct Route should be matched). Can you share a script or something creating the Routes to test this against? I get that the number of Routes should be in the hundreds, but that did not seem to trigger any issue on my end, so some specific steps must be missing like order in which they are created, paths to match, etc... |
|
@bungle Just woke up, on PTO today and tomorrow but I intend to spend some time this afternoon/evening and hack in those changes to the rc4 release and give it a go as I am super interested in it. Thanks for putting this together! EDIT: So I am about to test here in a bit finishing my lunch, but essentially after I pull down the rc4 I am doing this in my build path(that handler.lua is the one from your PR): Will give it a go!
In the newer release candidates it presented itself with 500 level errors like my splunk log showed above. I think I can whip up something in python that will create them all for yah as well as something to run live during the load test. My current logic is java but its a mess and not easy to break out. Could the reason you are having trouble reproducing be because your Kong node and db are all just localhost with no replication? We have to do replication factor of 3 so all nodes in a dc hold all data because without it OAuth token generation has issue under load(we went through those discussions awhile back). I am curious if there was a way to add simulated latency in to 20-30ms range for read/writes from C*(probably close to realistic for what I see under load, read sometimes actually spikes to in the 100-800ms ranges on 0.14.1) and if the issues in my real environments would become apparent in your test env. |
That is the other issue related to the router semaphore fixed by #4084. My goal was to reproduce the behaviour you were originally describing here, but on the latest 1.0 branch, on which I needed to disable the router semaphore to mimic 0.14. I am running a 3 nodes local cluster, but will increase RF to 3 and give it a another shot. With a QUORUM consistency I suppose. |
|
@thibaultcha ah I see what you mean now. @bungle just tried your patch on this version I am seeing this error in runtime: Is the handler you patched still including deprecated api resources? I have to test against the rc4 for my dev environment EDIT- |
|
The patch was created on top of the next branch, which still has APIs and such, while rc4 is cut from the release branch, which has additional commits deleting APIs. So the patch must be appropriately tweaks for it to work in rc4, one would not be able to copy-paste the file as-is. |
|
I ran through most the code quick and gutted what I believe to be right as long as underlying method calls drop that ,api) passed var are still taking parameters in the same way: Jeremy hacked handler: |
|
Aight, yep seems the above ^ dropped in Kong can start up, we are in business folks. Time to test. |
|
@thibaultcha @bungle @p0pr0ck5 Initial results are looking quality here folks, no mutex thrown errors in STDOUT and my load test @ 100 TPS shows no availability impact to the endpoint under load during the router adds on the fly!!!! Will continue testing edge cases as well as what its like calling other existing routes during this time of load-test but this is likely the best possible outcome at the moment I could have hoped for. You guys rock. Screenshot results @ the 100 TPS during router changes: Edit - not sure on the cpu statement, revoking it. |

|
Okay we actually ran a test with 100ish TPS to 2 route endpoints(200ish TPS total at this point), and I started modifying routes again on the fly adding say 20-30 to an arbitrary service(at a rate of about 1 every 2 seconds) not related to the ones under load and I still was able to reproduce some 500 errors that showed up in about 3/6th of the worker processes. But they only persisted during the window I was making router changes while loadtesting whereas the first rc4 before the @bungle patch the errors continually persisted long after the load test was done: 2018/12/13 22:45:01 [error] 153#0: 78094 [lua] responses.lua:128: before(): no router to route request (reason: error attempting to acquire build_router lock: timeout), client: 10..., server: kong, request: "GET /F5/status HTTP/1.1", host: "gateway-dev--.*****.com" 2018/12/13 22:45:01 [error] 153#0: 77722 [lua] responses.lua:128: before(): no router to route request (reason: error attempting to acquire build_router lock: timeout), client: 10..., server: kong, request: "GET /api/demo/test HTTP/1.1", host: "gateway-dev--.*****.com" We will try to whip up python scripts for building out the Kong env as well as simulating active changes under load and attach here. Edit visual: If you notice see when the tps of 200's is dipping and throughput seems impacted(didn't seem to in my prior 100 TPS test)? That signifies when the router changes started taking place and when the throughput stabilizes is when I stopped yet continued the load testing. Then you can see the blip of 500's which are all related to the build_router lock error. So seems errors can still occur and throughput is impacted when routes are being modified. The throughput drop is not the most worrisome for now but the 500 level errors is still a concern from a SLA impact. Edit - All the 500 level errors much like prior discussed from rc testing took a TotalLatency of 5 seconds exactly. |

|
@thibaultcha you had asked for a couple of scripts to generate routes/services and to update them to reproduce the failures There's two scripts in there. They are both pretty similar. For example, to create 500 test proxies, I'd use this command: To add 50 routes to a service once every 2 seconds to cause failures during an active loadtest, I'd use this (assuming in both cases that localhost:8001 is the root path to my admin API): |
|
Yes It means that requests were stuck 5 seconds waiting for semaphore to be released while other lighthread (another request) was trying to build a new router. The router building did not finish in 5 seconds, and no router was given back. The above scenario happens on all workers on a node. |
|
Right so sounds like the first patchwork will be the only going in for 1.0 because it still maintains worker consistency which is a Kong primary objective (noting our environment we were able to reproduce 500 level errors in that state under duress higher than 100 TPS, which was clarified to likely be because the time it takes to iterate over our 500+ services/route pairs exceeds 5 second C* timeout limits). It sounds like there may be a shot at getting the best of both worlds(consistency with worker processes AND no potential for failures under any circumstance) with @thibaultcha suggestion of a shm to keep track and leverage new vs stale router during rebuild. And this would come in later post 1.0 releases maybe as a minor update it sounds like. If I were to play devils advocate on the "eventually consistent workers seems to utterly confuse our users", could the same not be said for what seems to be deemed the proper implementation which is "I have 10,000 service and route resources Kong team, I added a route and tried to call it programmatically in 2 second why did it throw 404?" Then the appropriate Kong response would be, "well the router rebuild is a global and takes some time to query all those services and routes and the worker processes had not yet agreed on the next stable router(by use of consensus through shm I suppose)." There is always going to be something to clarify to people huh 😄 . I do think whatever the case going forward an implementation that does not impact pending requests and existing prior service/route resources has to be achieved regardless of how poor the db (postgres/cassandra) behaves. I like the idea of optimizing how services are fetched and to do local processing on the Kong node over bombarding C* with tons of individual queries per each service tied to the route(which feels slightly weird anyways because 1 service can have many routes, not 1 route has many services BUT routes are what actually expose the service resource so at the same time I get it). I may personally hold onto Bungle's full patchwork to run with the 1.0 release because I will take consistency differences in a few seconds in time between worker processes any day over possible failures of any kind. This originating 404 issue was probably the second scare I have had with Kong, hoping to keep my sanity among how fast paced the project is tied around leveraging Kong internally. Essentially 2019 is the year for us Kong goes ga internally and shows those around us it can actually work, been in a beta of sorts now with a few production services. I expect 5,000 non-prod proxies total by eoy 2019 (the environment we currently have about 700+ proxies now in where I see the 404's on 0.14.1). And close to say 1000 production proxies, with traffic in the 2,500 TPS - 3,000 TPS range. Hopefully smooth sailing eh (never is the case in tech). Hope yall are having a nice weekend, |
That is not what I claimed. |
|
I actually said the exact same thing in my above comment that the underlying issue was not resolved, and laid out clearly what each contribution solves and what other steps we could take. |
|
@jeremyjpj0916 I've tossed up #4101 as a POC/review PR. Would you be willing to give this patch a try in your stress testing environment? It's built against the |
|
@p0pr0ck5 I will give it a go on Sunday if It drops into rc4 with minimal changes needed. By the looks of it this perf should make the runloop more efficient in db interactions, maybe even keeps the 500 errors away at various tps with change rates to the routers 😄. Fingers crossed! |
|
@jeremyjpj0916 I consider my work now more or less done with #4102 (though waiting for feedback). I know @thibaultcha argued against adding a configuration parameter that is hard to describe, but I think it is really hard to have one size fits all strategy for this without going very much back to the drawing board and implementing more granular router updates. So all in all I think the PR #4102 covers a lot what we have discussed:
This provides 3 modes: 1. events timer only, 2. request timer and sync fallback, 3. request wait and synchronous fallback mode 1 (the most performant): mode 2 (tries harder to update router by creating timer on request or fallbacking to synchronous rebuild on request, still very fast, no waiting unless fallback): mode 3a (waits just a 1ms and then builds synchronously if new router is not yet available): mode 3b (old behavior, waits at max 5 secs and then builds synchronously if new router is not yet available): All the modes have events timer enabled, but modes 2 and 3 also do request time rebuilding, it is bit of a luck what gets to run it then (request or event). I would run either Thanks. |
|
@bungle Its all great to me due to the flexibility and as someone who somewhat understands the issue and your approach to solve it, but it does sound like you may have a hard time internally convincing others because:
Whatever becomes of your patch work its been awesome for us and solving the issues we see, I still struggle to understand how no one else has come across the issue and that its not easy to reproduce under realistic conditions while leveraging services and routes on 0.14.1. Maybe most of the community isn't on it yet(I still see posts from people on Kong versions like 3-4 major iterations behind 0.14.1. Or maybe its because not many run a C* setup multi DC with strict consistency which adds a little DB latency to the mix under load. Also with how slow many Enterprises move I would think most enterprise customers are still on deprecated API resources that run large Kong nodes with many proxies 🐌. I will give your new stuff a go though, do note I will be on PTO next work week without laptop access. Thanks! |
|
Yes, we will see. While Roberts prefetch does speed things up, I would guess my proposal's caching is one step forward from that as cache is shared with all the workers and invalidated automatically and warmed on node start. Prefetch can also make small bugs as the service prefeched may already be stale when looping routes. And the approach I took is to update every worker on cluster regardless if those workers get requests when we get new router version event and when they do they already have router up to date. But well... |
|
@p0pr0ck5 This is what I came up with for the cleaned up handler based on your next branch that should work with rc4 Will try dropping in just this changed handler and giving a quick stress test and will edit with results. |
|
One thing about CPU is that my approach can make spike as all workers are updated around the same time and other nodes as soon as they get cluster event (already configurable), or before if it is request that starts a timer (timeout 0) or builds it synchronously (timeout > 0). But it will make it much shorter too (e.g. after update on route or service your whole cluster is fully cached and full speed across all workers in matter of seconds), while with old approach you couldn't tell when the whole cluster and all the workers have Been updated. |
|
@p0pr0ck5 I gave your logic a go, was only able to do a quick test tonight before my trip, based on just the handler change above with your new service change I could not produce 500 level errors either nor did it seem to cause any throughput degradation besides maybe 1 slight dip on the tail end of the calls. I ran this at 240 TPS and created 30 routes on the fly every 2 seconds with the python script offered above. So no extensive testing but initial results seem positive. I like the idea of less bombardment of queries to the db around services so I wonder if this could get somehow mixed into the fray with all of the @bungle changes(granted they reach approval). Anyways I gotta head out, all testing I can do for now! Hope all at Kong enjoy the holidays! |
|
Jeremy, my PR already does "the same", and because of caching, it does not even do prefetch. It might occasionally make one or two single row queries to db with primary key. Even that could be prewarmed, but I don't think it is neccessary. |
|
@bungle Oh even better! Querying services 1000 at a time as opposed to 1 was what I was thinking could be beneficial, which based on what you said it sounds like that is indeed the case except under special circumstances that may require singular lookups, but few in number. Thanks for all the good work! Other ideas floating in my head would be are there any fail scenarios or problems where the new router build could not reach completion where Kong would need to err log to users to inform stale router has remained in use an excessive amount of time? I suppose if its db connectivity related issues that already would be visible based on existing safe guards, guess thinking if there is anything ontop of that it may need? You probably already considered all that though 😄. |
|
Edit - no need anymore. |
|
Edit - No need anymore. |
|
@bungle QQ I have been testing the pending PR #4102 on 1.0 tonight with high throughput on the -1 setting and its been great so far where service/route additions/deletions are not causing any impact to the gateway. In what situation does "(if timer creation fails, new router will not be build, but you can trigger a new try with modifying routes or services)" occur? And are there steps that could be taken in Nginx/OpenResty/Kong to keep the likelihood of timer creation success a very high probability? Also curious if when timer creation fails will Kong/Nginx log something to stderr that there is a problem creating them so its not hidden? |
|
Closing as a dup of #4194 at this point . |
|
@here was this fix implemented into older version 0.12.X or 0.15.X |
|
@UnixBoy1 I think a more minimal form of it made it into 1.2 as the first iteration for eventual consistency. Was not added to earlier versions. |
|
We just saw something quite similar on our Kong 1.2, i.e. intermittent 404's whilst it was under heavy load. We run in DB-less mode. The discussion threads are a bit hard to follow - is this potentially similar to what was going on here (I see various references to C*, which we no longer use) , and is it meant to be fixed in a more recent Kong version? |
|
@jmgpeeters have you tried the eventual consistency option? Although I think the 404’s would be less impactful in dbless mode(rebuilds should be faster). What scenario do you experience the 404’s? |
|
I haven't tried the eventual consistency option. Is there any documentation on it? I'm a bit confused as to how DB-less (i.e. no communication between Kong nodes required) could lead to consistency issues. Isn't everything just immediately consistent? The scenario was that we were experiencing very heavy load on Kong for a brief period, which led to a small amount of intermittent 404's (not able to match a route) being thrown back to users. After the load was reduced, these 404's went away - so it does sound quite similar to what is being described here. We're actually quite OK for Kong to shed load through some error code, if it fails to keep up, but perhaps 404 isn't optimal. I suppose that is just a side-effect of how Kong is implemented, but if the condition can be detected, then maybe 503 or so is more appropriate. |
|
@jmgpeeters my issue was around 404's when modifications to routers were occurring causing rebuilds(which deals with the complexities of runtime in-memory change woes). Your issue is slightly different to be seeing 404's just under heavy load and not when new proxies are being added/deleted from Kong. I would consider it a totally separate issue since its just apparent at high traffic volume. |
|
Yes, that makes sense. |
Summary
We have noticed in our Kong Gateway nodes times when common endpoints the gateway exposes throwing 404 route not found on a % of API calls. The specific proxy we focused on with this post( "/F5/status") does not route, has no auth, and serves as a ping up time endpoint that returns static 200 success. We do notice this as well on other endpoints that have auth and plugins as well, but the frequency in which our ping endpoint gets consumed is consistent and provides the best insight.
Steps To Reproduce
Reproducing consistently seems impossible from our perspective at this time, but we will elaborate with as much detail and screenshots as we can.
Create combination of services and resources 1 to 1. We see 130 service route pairs. 300 plugins. Some global, some applied directly to routes(acl/auth).
Add additional services + routes pairs with standard plugins over extended time.
Suspicion is eventually the 404's will reveal themselves, and we have a high degree of confidence it does not happen globally across all worker processes.
New arbitrary Service+Route was made on the Gateway, specific important to note is created timestamp:

Converted to UTC:

Above time matches identically with when the existing "/F5/status" began throwing 404 route not found errors:

You can see a direct correlation to when that new service+route pair was created to when the gateway began to throw 404 not found errors on a route that exists and previously had no problems. Note the "/F5/status" endpoint takes consistent traffic at all time from health check monitors.
Interesting bit its the % of errors to this individual Kong Node, we run 6 worker processes and the error rate % is almost perfect for 1 worker process showing impact:
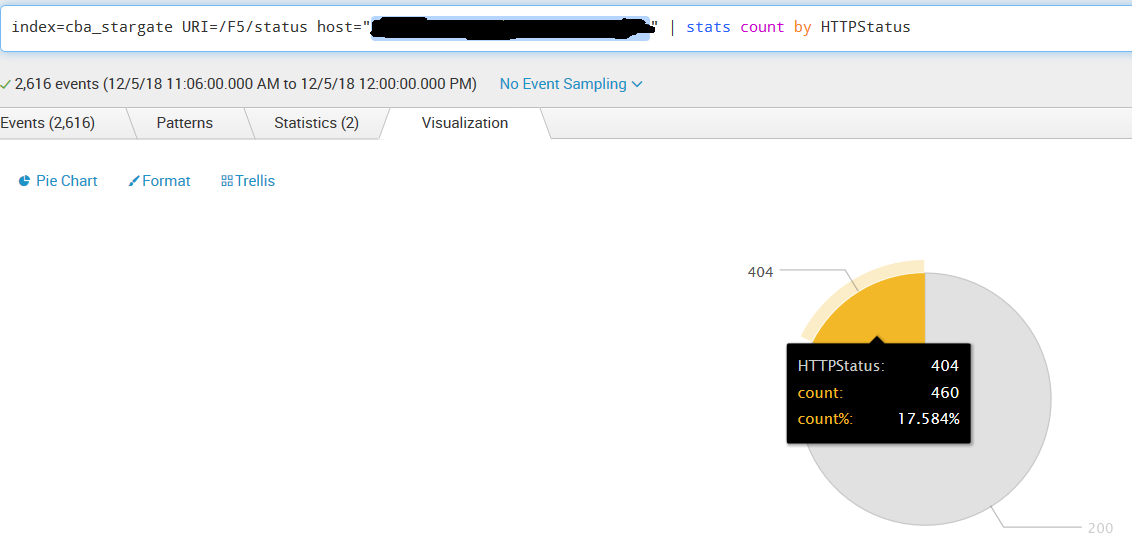
To discuss our architecture we run Kong with Cassandra 3.X in 2 datacenters, 1 Kong node per data center. We run a 6 node Cassandra cluster, 3 C* nodes per datacenter. The errors only occurred in a single datacenter on the Kong node in our examples above, but both datacenters share identical settings. We redeploy Kong on a weekly basis every Monday early AM, but this error presented above Started on a Wednesday so we can't correlate the problem to any sort of Kong startup issue.
To us the behavior points to cache rebuilding during new resource creation based on what we can correlate. Sadly nothing in Kong logging catches anything of interest when we notice issue presenting itself. Also note it does not happen every time obviously so its a very hard issue to nail down.
We also notice the issue correcting itself too at times, we have not traced the correction to anything specific just yet, but I assume very likely its when further services and routes are created after the errors are occurring and what seems to be a problematic worker process has its router cleaned up again.
Other points I can make are that production has not seen this issue with identical Kong configurations and architecture. But production has fewer proxies and has new services or routes added at a much lower frequency(1-2 per week vs 20+ in non-prod).
I wonder at this time if it may be also safer for us to switch cache TTL back from the 0 infinity value to some arbitrary number of hours to force cycle on the resources. I suppose if it is indeed the cache as we suspect that that would actually make the frequency of this issue more prevalent possibly though.
I may write a Kong health script that just arbitrarily grabs all routes on the gateway and calls each 1 one by 1 to ensure they don't return a 404 as a sanity check to run daily too right now. My biggest fear is as production grows in size and/or higher frequency in services/routes created daily we may begin to see the issue present itself there as well and that would cause dramatic impact to existing priority services if they start to 404 respond due to Kong not recognizing the proxy route exists in the db and caching appropriately.
Sorry I could not provide a 100% reproducible scenario for this situation, can only go off the analytics we have. Although if it yields some underlying bug in how Kong currently manages services and routes, that would bring huge stability to the core product.
Additional Details & Logs
Kong version 0.14.1
Kong error logs -
Kong Error logs reveal nothing about the 404 not found's from Kong's perspetive. Nothing gets logged during these events in terms of normal or debug execution.
Kong configuration (the output of a GET request to Kong's Admin port - see
https://docs.konghq.com/latest/admin-api/#retrieve-node-information)
The text was updated successfully, but these errors were encountered: