To quote Michael Nygard from Craft Conference, 2023 talk: https://youtu.be/55qSt0PsU_0?si=VF5jJc3ycESM7xDA
Building an abstraction layer is like buying an option:
* Those options are not often exercised
* It’s likely that whatever your abstraction layer is it will be a poor representation of what’s underneath it and it won’t be general enough to support the next new thing you want to swap in.
-> Therefore think very carefully about building one at start
Should have watched this first, but it was fun building it out as PoC!
conda create -n python3-9-12 python=3.9.12 anaconda
conda activate python3-9-12
dev environment:
export JIRA_TOKEN=<token>
export JIRA_EMAIL=<email>
export CREDENTIALS_JSON=<email>
export BAMBOO_CACHE_PATH=<email>
echo "$JIRA_TOKEN"
echo "$JIRA_EMAIL"
echo "$CREDENTIALS_JSON"
echo "$BAMBOO_CACHE_PATH"
Generating Tokens:
- JIRA_TOKEN https://id.atlassian.com/manage-profile/security/api-tokens.
- Google CREDENTIALS_JSON: https://github.com/LeadTechie/BambooConnect/blob/v3/readme/README.md
pip install notebook
pip install jupytext
python -m unittest discover -s test/end2end/ -p 'test_e2e*.py'
python -m unittest discover -s test/integration/ -p 'test_integration*.py'
python -m unittest discover -s test/system/ -p 'test_system*.py'
python -m unittest discover -s test/unit/ -p 'test_unit*.py'
python -m unittest discover -p 'test_*.py' -t .
pip install -e ./BambooConnect
pip install jupytext
pip install jupyter
jupytext --to notebook extractors/google_drive_file_extractor.py
jupytext --set-formats ipynb,py extractors/google_drive_file_extractor.ipynb
jupytext --sync extractors/google_drive_file_extractor.ipynb
jupyter notebook
python jupyter_start.py
Select . for current subdirectory Then enter eg e2e to see just files with e2e jupyter notebook will then be started
How much time do you waste manually keeping track of data from multiple systems. Different systems, different formats. Is your list up to date? How to match users or ids across multiple systems?
Bamboo Connect is a lightweight ETL (Extract, Transform, Load) library with examples and templates. It enables developers to quickly extract, transform, reconcile and then load resulting data securely. This avoids time consuming manual error prone tasks.
If you’re low volume (<10k records), low frequency (max hourly), already have GitHub and Google Sheets available to you and have development skills then Bamboo Connect is for you.
Example use cases:
- How to link component documentation from the JIRA with an extended Google sheets list
- How can you tell who has a JIRA account but it not yet in GitHub
- How to keep multiple team lists with so many changes and new starters across different systems



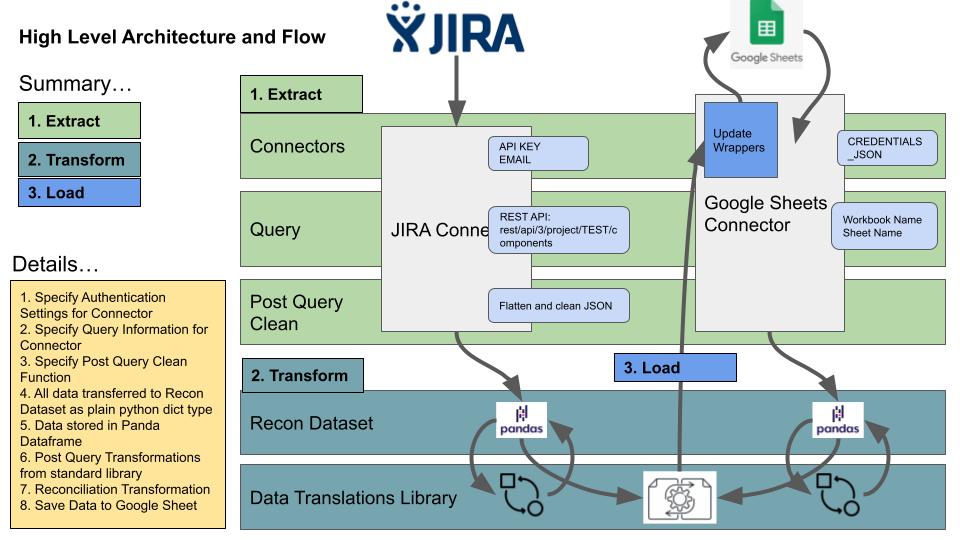


- See the sub pages for details on setting up the credentials and access tokens for Google and JIRA
- Install - https://docs.conda.io/en/latest/miniconda.html
https://docs.conda.io/projects/conda/en/latest/user-guide/getting-started.html - Update https://www.geeksforgeeks.org/set-up-virtual-environment-for-python-using-anaconda/
Set version 3.9.12
conda create -n python3-9-12 python=3.9.12 anaconda
conda activate python3-9-12
pip install -r ./requirements.txt
Place your Google credentials.json file in the directory below the project directory then run See here for how to create your credentials.json file
python authentication_support.py
This will create the base64 encoded string you need for the CREDENTIALS_JSON
Generate your JIRA Token https://support.atlassian.com/atlassian-account/docs/manage-api-tokens-for-your-atlassian-account/
export RECON_TOOLS_JIRA_EMAIL="<Your value here>"
export RECON_TOOLS_JIRA_TOKEN="<Your value here>""
export CREDENTIALS_JSON="<Your value here base64 encoded json file>"
echo "$RECON_TOOLS_JIRA_TOKEN"
echo "$RECON_TOOLS_JIRA_EMAIL"
echo "$CREDENTIALS_JSON"
Testing is setup at 4 levels:
- Unit Tests: All tests and test data is in test files
- System Tests: Uses test files in subdirectory /test_data/
- Integration Tests: Links to 3rd party systems but relies on minimumd data in these systems so you can run these tests
- end2end Tests: Integration tests relying on specfic sestup or external systems (JIRA & Sheets) so won't work for you unless you get access to my projects or use test files to recreate base data
python -m unittest discover -s test/unit -p 'test_*.py'
python -m unittest discover -s test/system -p 'test_*.py'
TODO: Currently this requires access to a test JIRA account
python poc_test.py
See this Google Presentations for latest version of these docs