time complexity big o notation
모든 개발자들은 한번 쯤 알고리즘의 시간 복잡도에 대한 질문을 받을 때가 있다. 절대로하지 말아야 할 화이트 보드 인터뷰 중이거나 특정 작업 방식에 대해 다른 개발자와 대화하는 동안일 수도 있다. 빅 오 표기법을 알고 이해하면 개발자로써 애플리케이션을 생각하고 형성하는데 도움을 준다.
내가 말하고자 하는 바를 이해하려면 먼저 알고리즘의 시간 복잡도를 계산하는 방법에 대한 규칙을 정하고 알고리즘을 정의해야한다.
우리가 '알고리즘'이라고 말할 때 의미하는 것은 결과를 산출하기 위해 작업자가 따라야 할 정의 된 단계의 집합이다. 예를 들어, 멘토의 집에서 커피를 만드는 알고리즘은 다음과 같다.
- 찬장에서 컵을 가져오기
- 내가 원하는 커피가루를 가져오기
- 커피메이커의 물이 최소 수준 이상인지 확인
- 컵을 커피가 내려올 곳에 놓기
- 커피가루를 커피메이커 안에 넣기
- '시작' 버튼 누르기
- 컵이 가득 찰 때까지 기다리기
- 마시기
찬장에서 컵을 가져오는 방법이나, 기계 내부에 커피가루를 넣는 방법과 같은 여러 단계가 있지만, 위의 커피 한 잔을 만드는 알고리즘은 과정의 각 단계를 간략하게 설명하며, 이러한 단계를 따르는 사람은 커피 한 잔을 만들 수 있다.
커피 여러잔을 만들고 싶은 사람들의 목록이 있다면 어떨까? 이것이 바로 시간 복잡도를 나타낸다.
커피 한 잔을 원하는 사람 이 n 명이라고 가정 해 보자. 커피 한 잔을 만드는 데 걸리는 단계와 시간은 매번 동일하기 때문에 n 잔의 커피 를 만드는 데 n 시간 단위가 걸립니다. 따라서 5 컵의 커피는 5 단위의 시간이 걸리거나 Big O 표기법에서는 O (5) 가 걸린다. 우리가 100 컵의 커피를 만들고 싶다면 O (100) 이 걸릴 것 이다. 그러나 Big O 표기법을 접근적 표기법 또는 '입력이 무한대로 증가함에 따라' 표기하는 것이 일반적이다. 이런 식으로, 커피 메이킹 알고리즘은 O(n) 이다.
시간 복잡도 측면에서 알고리즘을 평가하는 또 다른 규칙은 최악의 경우를 사용한다는 것이다. 즉, 무언가 O (n) 라고 말할 때 이 알고리즘에 걸리는 시간은n 개의 요소 에 대해 작업을 수행하는 데 걸리는 시간과 같다 .
이제 규칙과 어휘를 정의 했으므로 코드에서 이 모든 것이 어떻게 보이는지 살펴보자.
먼저 *O (1)*을 살펴보자. 입력 양이나 크기에 관계없이 알고리즘을 수행하는 데 항상 1 단위 시간이 소요됩니다. O (1) 인 알고리즘의 예제는 배열 또는 해시/객체에서 각 항목에 접근하는 것이다.
// n개의 크기 리스트/개체가 있을 경우, 해당 인덱스에서 값을 반환하는 데 1 단위가 소요됨
const valueAt = (key, obj) => obj[key];배열은 인덱스 객체 일 뿐이므로 이 알고리즘을 통해 객체와 배열에 모두 액세스 할 수 있으며 둘 다 메모리의 특정 위치에서 값을 검색하고 있음을 보여준다.
그렇다면, 필요한 항목을 찾을 때까지 전체 목록을 검토할 필요가 있다고 가정해보자. 다시 말하면 우리가 필요한 항목이 목록 맨 끝에 있거나 아예 목록에 없는 것으로 하는 것이다. 즉, 최악의 경우를 살펴보는 것이다. 그렇다면 그 알고리즘의 시간 복잡도는 얼마일까?
// n 크기의 정렬되지 않은 목록을 사용할 경우 값을 찾는 데 n 단위가 소요됨
const indexOf = (val, list) => {
for (let i = 0; i < list.length; i++) {
if (list[i] === val) {
return i;
}
}
}단일 연산을 수행하는 것이 아닌 무언가를 반복하기 때문에 이 알고리즘은 더 오래 걸릴 것이다. 가장 좋은 경우는 값이 0 번째에 있어서 일찍 반환 하는 것이다. 반대로 최악의 경우는 항목이 배열에 없거나 배열의 맨 마지막에 있는 경우이다. 최악의 경우 결과를 얻는 데 n 시간 이 걸린다 . 이 때문에 위의 알고리즘은 O (n) 또는 선형 알고리즘이라고 한다. 걸리는 시간은 목록에있는 요소의 양에 비례하여 증가한다.
다음으로, O (n²) 인 선택 정렬 알고리즘의 예를 살펴 보자 . 이것은 최상의 경우에도 시간 복잡성 측면 에서 최악의 방법 중 하나이다. 이유를 알아보자.
const selectionSort = (list) => {
for (let i = 0; i < list.length; i += 1) {
let minJ = i;
for (let j = i + 1; j < list.length; j += 1) {
if (list[j] < list[minJ]) {
minJ = j;
}
}
const oldVal = list[i];
const newVal = list[minJ];
if (oldVal !== newVal) {
list[i] = newVal;
list[minJ] = oldVal;
}
}
return list;
};제자리에서 값 변경하기 이 외에도 ,이 알고리즘을 나쁘게 만드는 것은 목록의 모든 반복에서 그 시점부터 나머지 목록을 반복해야한다는 것이다. 목록이 늘어남에 따라 반복 횟수도 기하 급수적으로 증가한다.
운 좋게도 JavaScript는 시간 복잡성에 대해 너무 걱정할 필요없이 목록을 정렬하는 데 사용할 수있는 배열에 자체 고유 메소드인 sort를 구현했다. 하지만 어떻게 정렬할까? 정렬 된 목록에 항목을 어떻게 추가할까?
우리는 newList = [...list,1].sort()라는 해결책을 찾을 수 있었지만 모든 삽입에 대해 전체 배열을 반복해야한다는 것을 의미한다. 우리는 일단 아이템이 가는 곳을 찾으면 나머지 배열도 정확하다는 것을 알 수 있다.
삽입할 때마다 반복하는 것이 최선의 경우인 O(n)이지만 최악의 경우 O(n)와 일치하지만 더 나은 경우인 알고리즘을 만들 수 있는지 궁금하다.
const insert = (compare = (a, b) => a < b, item, list) => {
let result = [];
let inserted = false;
for (let i = 0; i < list.length; i += 1) {
const val = list[i];
if (compare(val, item)) {
result.push(val);
} else {
result = result.concat(item, list.slice(i));
inserted = true;
break;
}
}
return inserted ? result : result.concat(item);
};위의 예제는 각 항목을 반복하고 주어진 항목보다 작은 지 확인한다. 만약 그렇다면, 우리는 그 값을 새로운 배열에 추가하고 다음 루프로 계속 진행한다. 그렇지 않은 경우, 주어진 항목이 다음에 속한다는 것을 알고 있으므로 결과를 이전 결과인, 나머지 목록으로 설정한다. 그러나 때로는 전달 된 항목이 목록의 끝으로 해야한다. 이를 알기 위해 우리는 휴식을 취하기 전에 깃발을 설정하고 돌아올 때 확인한다.
위의 알고리즘의 시간 복잡도는 최악의 경우 *O (n)*이다. 항목이 목록의 다른 항목보다 크면 모든 항목을 반복하여 계산해야하기 때문이다. 그러나 가장 좋은 경우는 기본적으로 *O (1)*이다. 전달 된 항목이 목록의 맨 앞에 있어야하므로 첫 번째 반복에서 루프에서 벗어날 수 있기 때문이다.
더 빠른 방법은 없을까?
모든 목록 항목을 검색하지 않고 반복 할 때마다 다음에 찾아야 할 위치에 대한 정보를 얻을 수 있다면 어떻게 될까? 배열 전체를 정렬하는 대신 정렬되기 때문에 작업자에게 다음과 같이 말할 수 있다. "이번 반복에 대한 결과를 바탕으로 다음에 살펴볼 하위 목록이 있다."
우리가 설명하는 것은 이진 검색이며 시간 복잡도를 크게 줄인다. 기본적으로 작업자에게 목록 중간을 살펴보고 전달한 항목과 중간 색인의 항목을 비교하도록 지시합니다. 그런 다음 그 결과에 따라 루프의 다음 반복 중에 목록의 상반부 또는 하반부를 검색한다. 우리는 각 단계를 수행하여 최대 인덱스와 최소 인덱스 전환까지 목록을 반으로 자르고 중간을 항목과 비교한다. 일단 그렇게하면 우리는 주어진 항목이 최소 인덱스 바로 다음에 가야한다는 것을 안다.
const insert = (fn = (a, b) => a < b, item, list = []) => {
if (!list.length) {
return [item];
}
if (list.length === 1) {
return fn(item, list[0]) ? [item, list[0]] : [list[0], item];
}
let min = 0;
let max = list.length - 1;
while (true) {
if (max < min) {
return list.slice(0, min).concat([item], list.slice(min));
}
const currIndex = Math.floor((min + max) / 2);
const currItem = list[currIndex];
const sort = fn(item, currItem);
if (sort) {
max = currIndex - 1;
}
if (!sort) {
min = currIndex + 1;
}
}
};인수의 수를 확장하고 더 많은 로직들을 추가해야했지만 알고리즘의 검색 부분을 O (n)(선형) 에서 O (log n)(로그)로 변경했다. 입력으로 제공되는 정렬 된 목록이므로 검색 중에 작업자가 수행해야하는 반복 횟수를 줄여 시간 복잡성을 줄인다.
아래에서 다양한 유형의 시간 복잡도와 n 이 커질 때 서로 비교하는 방법을 볼 수 있다.
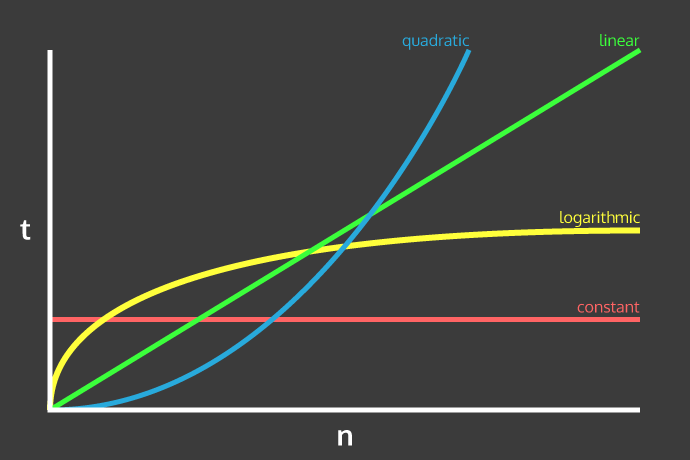
선형 시간 복잡도, 즉 *O(n)*가 처음에는 로그 시간 복잡도(O(log n)), 보다 더 성능이 뛰어나지만, 입력의 크기가 커지면 *O(log n)*가 실제로 좋다는 것을 알 수 있다.
시간 복잡도에 대한 문제는 다음과 같습니다. 미세 최적화가 쉽고 DOM으로 작업 할 때의 경험으로는 해결할 문제가 거의 없을 것이다. ramda 또는 lodash와 같은 라이브러리 패키지가있는 경우 해당 insert / sorts / etc를 사용해라. [...list,item].sort()를 100 번 정도 반복해도 문제가 되지 않을 것이다.
그렇다면 왜 알아야 할까? 코드 성능에 문제가되지 않는다면 이 이상한 수학을 이해하는 데 어려움을 겪는 이유는 무엇을까?
이러한 흥미로운 문제 를 해결하려면 시간 복잡도가 유일한 출발점이다.