| Chat | Windows build status | Linux build status |
|---|---|---|
 |
The Microsoft Cognitive Toolkit (https://cntk.ai) is a unified deep learning toolkit that describes neural networks as a series of computational steps via a directed graph. In this directed graph, leaf nodes represent input values or network parameters, while other nodes represent matrix operations upon their inputs. CNTK allows users to easily realize and combine popular model types such as feed-forward DNNs, convolutional nets (CNNs), and recurrent networks (RNNs/LSTMs). It implements stochastic gradient descent (SGD, error backpropagation) learning with automatic differentiation and parallelization across multiple GPUs and servers. CNTK has been available under an open-source license since April 2015. It is our hope that the community will take advantage of CNTK to share ideas more quickly through the exchange of open source working code.
- Setup CNTK
- Windows (Python-only / Script-driven / Manual)
- Linux (Python-only / Script-driven / Manual / Docker)
- CNTK backend for Keras
- Setup CNTK development environment
- Windows (Script-driven / Manual)
- Linux (Manual)
If you prefer to use latest CNTK bits from master, use one of the CNTK nightly packages:
You can learn more about using and contributing to CNTK with the following resources:
- General documentation
- Python API documentation
- Evaluation documentation (C++, C#/.NET, Python, Java)
- Manual
- Tutorials
- Examples
- Pretrained models
- Blog
- Presentations
- License
Dear community,
With our ongoing contributions to ONNX and the ONNX Runtime, we have made it easier to interoperate within the AI framework ecosystem and to access high performance, cross-platform inferencing capabilities for both traditional ML models and deep neural networks. Over the last few years we have been privileged to develop such key open-source machine learning projects, including the Microsoft Cognitive Toolkit, which has enabled its users to leverage industry-wide advancements in deep learning at scale.
Today’s 2.7 release will be the last main release of CNTK. We may have some subsequent minor releases for bug fixes, but these will be evaluated on a case-by-case basis. There are no plans for new feature development post this release.
The CNTK 2.7 release has full support for ONNX 1.4.1, and we encourage those seeking to operationalize their CNTK models to take advantage of ONNX and the ONNX Runtime. Moving forward, users can continue to leverage evolving ONNX innovations via the number of frameworks that support it. For example, users can natively export ONNX models from PyTorch or convert TensorFlow models to ONNX with the TensorFlow-ONNX converter.
We are incredibly grateful for all the support we have received from contributors and users over the years since the initial open-source release of CNTK. CNTK has enabled both Microsoft teams and external users to execute complex and large-scale workloads in all manner of deep learning applications, such as historical breakthroughs in speech recognition achieved by Microsoft Speech researchers, the originators of the framework.
As ONNX is increasingly employed in serving models used across Microsoft products such as Bing and Office, we are dedicated to synthesizing innovations from research with the rigorous demands of production to progress the ecosystem forward.
Above all, our goal is to make innovations in deep learning across the software and hardware stacks as open and accessible as possible. We will be working hard to bring both the existing strengths of CNTK and new state-of-the-art research into other open-source projects to truly broaden the reach of such technologies.
With gratitude,
-- The CNTK Team
This project has adopted the Microsoft Open Source Code of Conduct. For more information see the Code of Conduct FAQ or contact opencode@microsoft.com with any additional questions or comments.
You can find more news on the official project feed
2019-03-29. CNTK 2.7.0
- Moved to CUDA 10 for both Windows and Linux.
- Support advance RNN loop in ONNX export.
- Export larger than 2GB models in ONNX format.
- Support FP16 in Brain Script train action.
CNTK now supports CUDA 10. This requires an update to build environment to Visual Studio 2017 v15.9 for Windows.
To setup build and runtime environment on Windows:
- Install Visual Studio 2017. Note: going forward for CUDA 10 and beyond, it is no longer required to install and run with the specific VC Tools version 14.11.
- Install Nvidia CUDA 10
- From PowerShell, run: DevInstall.ps1
- Start Visual Studio 2017 and open CNTK.sln.
To setup build and runtime environment on Linux using docker, please build Unbuntu 16.04 docker image using Dockerfiles here. For other Linux systems, please refer to the Dockerfiles to setup dependent libraries for CNTK.
CNTK models with recursive loops can be exported to ONNX models with scan ops.
To export models larger than 2GB in ONNX format, use cntk.Function API: save(self, filename, format=ModelFormat.CNTKv2, use_external_files_to_store_parameters=False) with 'format' set to ModelFormat.ONNX and use_external_files_to_store_parameters set to True. In this case, model parameters are saved in external files. Exported models shall be used with external parameter files when doing model evaluation with onnxruntime.
2018-11-26.
Netron now supports visualizing CNTK v1 and CNTK v2 .model files.
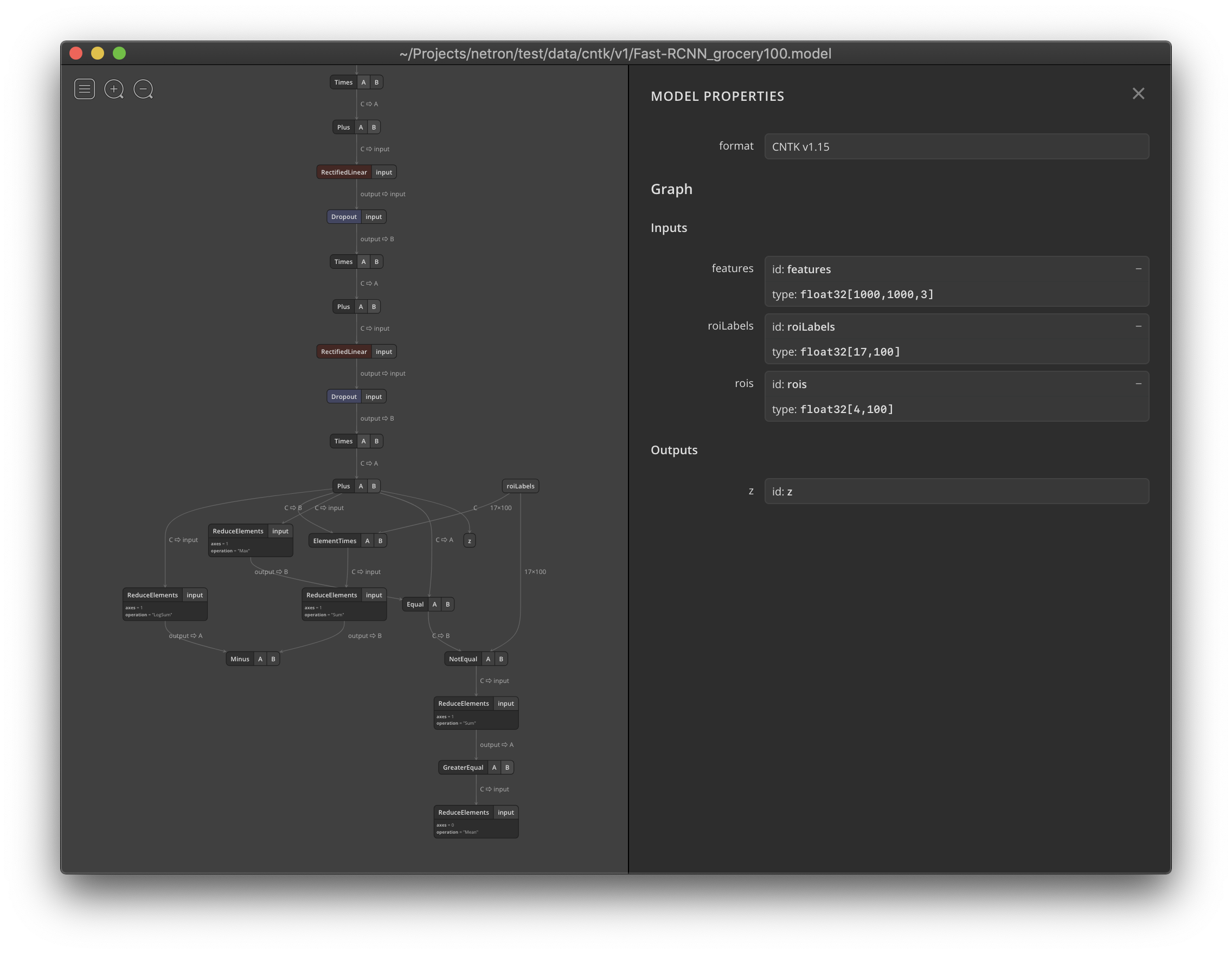
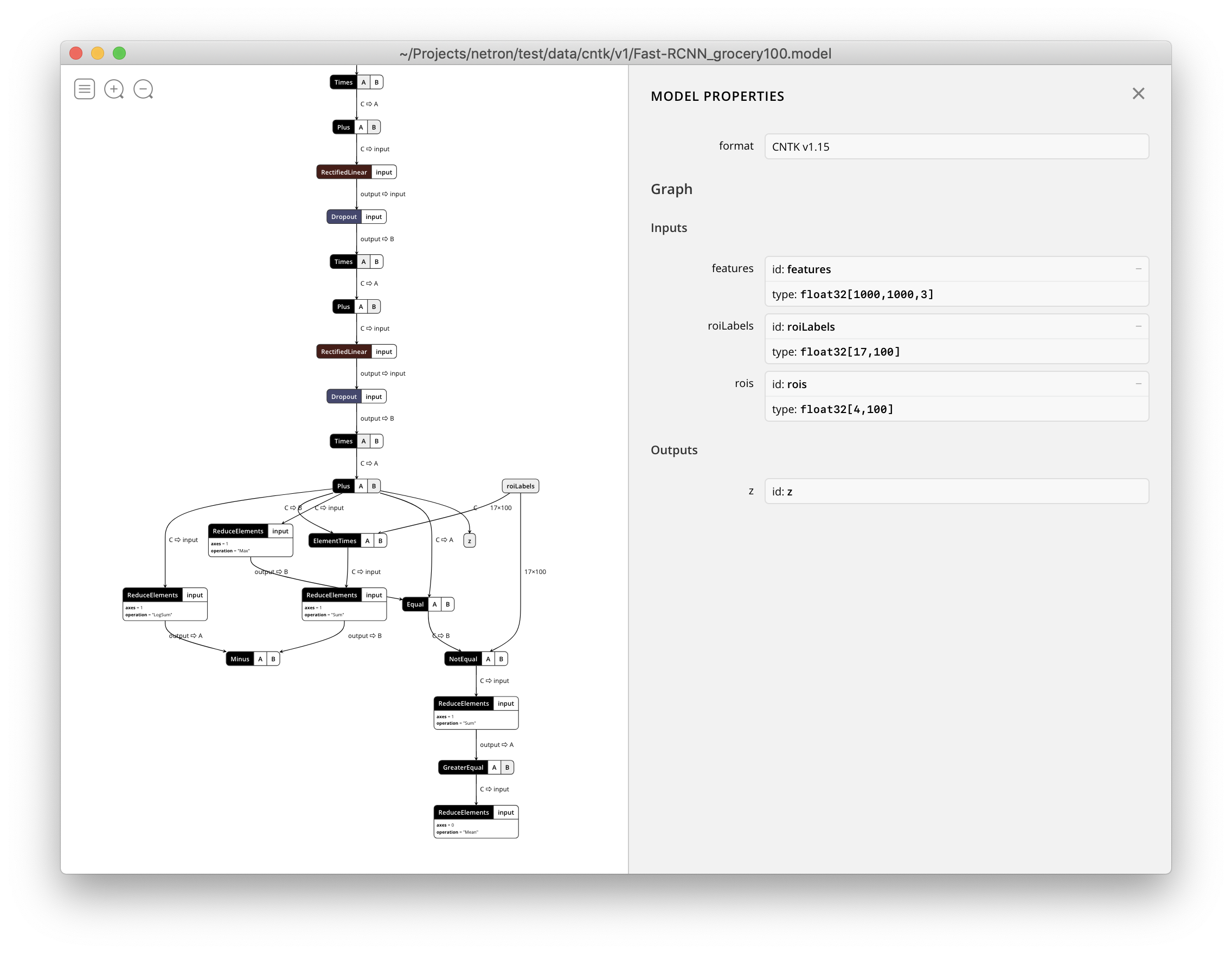
2018-09-17. CNTK 2.6.0
The implementation of group convolution in CNTK has been updated. The updated implementation moves away from creating a sub-graph for group convolution (using slicing and splicing), and instead uses cuDNN7 and MKL2017 APIs directly. This improves the experience both in terms of performance and model size.
As an example, for a single group convolution op with the following attributes:
- Input tensor (C, H, W) = (32, 128, 128)
- Number of output channels = 32 (channel multiplier is 1)
- Groups = 32 (depth wise convolution)
- Kernel size = (5, 5)
The comparison numbers for this single node are as follows:
| First Header | GPU exec. time (in millisec., 1000 run avg.) | CPU exec. time (in millisec., 1000 run avg.) | Model Size (in KB, CNTK format) |
|---|---|---|---|
| Old implementation | 9.349 | 41.921 | 38 |
| New implementation | 6.581 | 9.963 | 5 |
| Speedup/savings Approx. | 30% Approx. | 65-75% Approx. | 87% |
The implementation of sequential convolution in CNTK has been updated. The updated implementation creates a separate sequential convolution layer. Different from regular convolution layer, this operation convolves also on the dynamic axis(sequence), and filter_shape[0] is applied to that axis. The updated implementation supports broader cases, such as where stride > 1 for the sequence axis.
For example, a sequential convolution over a batch of one-channel black-and-white images. The images have the same fixed height of 640, but each with width of variable lengths. The width is then represented by sequential axis. Padding is enabled, and strides for both width and height are 2.
>>> f = SequentialConvolution((3,3), reduction_rank=0, pad=True, strides=(2,2), activation=C.relu)
>>> x = C.input_variable(**Sequence[Tensor[640]])
>>> x.shape
(640,)
>>> h = f(x)
>>> h.shape
(320,)
>>> f.W.shape
(1, 1, 3, 3)
There is a breaking change in the depth_to_space and space_to_depth operators. These have been updated to match ONNX specification, specifically the permutation for how the depth dimension is placed as blocks in the spatial dimensions, and vice-versa, has been changed. Please refer to the updated doc examples for these two ops to see the change.
Added support for trigonometric ops Tan and Atan.
Added support for alpha attribute in ELU op.
Updated auto padding algorithms of Convolution to produce symmetric padding at best effort on CPU, without affecting the final convolution output values. This update increases the range of cases that could be covered by MKL API and improves the performance, E.g. ResNet50.
There is a breaking change in the arguments property in CNTK python API. The default behavior has been updated to return arguments in python order instead of in C++ order. This way it will return arguments in the same order as they are fed into ops. If you wish to still get arguments in C++ order, you can simply override the global option. This change should only affect the following ops: Times, TransposeTimes, and Gemm(internal).
- Updated doc for Convolution layer to include group and dilation arguments.
- Added improved input validation for group convolution.
- Updated
LogSoftMaxto use more numerically stable implementation. - Fixed Gather op's incorrect gradient value.
- Added validation for 'None' node in python clone substitution.
- Added validation for padding channel axis in convolution.
- Added CNTK native default lotusIR logger to fix the "Attempt to use DefaultLogger" error when loading some ONNX models.
- Added proper initialization for ONNX TypeStrToProtoMap.
- Updated python doctest to handle different print format for newer version numpy(version >= 1.14).
- Fixed Pooling(CPU) to produce correct output values when kernel center is on padded input cells.
- Updated CNTK's ONNX import/export to use ONNX 1.2 spec.
- Major update to how batch and sequence axes are handled in export and import. As a result, the complex scenarios and edge cases are handled accurately.
- Updated CNTK's ONNX
BatchNormalizationop export/import to latest spec. - Added model domain to ONNX model export.
- Improved error reporting during import and export of ONNX models.
- Updated
DepthToSpaceandSpaceToDepthops to match ONNX spec on the permutation for how the depth dimension is placed as block dimension. - Added support for exporting
alphaattribute inELUONNX op. - Major overhaul to
ConvolutionandPoolingexport. Unlike before, these ops do not export an explicitPadop in any situation. - Major overhaul to
ConvolutionTransposeexport and import. Attributes such asoutput_shape,output_padding, andpadsare fully supported. - Added support for CNTK's
StopGradientas a no-op. - Added ONNX support for TopK op.
- Added ONNX support for sequence ops: sequence.slice, sequence.first, sequence.last, sequence.reduce_sum, sequence.reduce_max, sequence.softmax. For these ops, there is no need to expand ONNX spec. CNTK ONNX exporter just builds computation equivalent graphs for these sequence ops.
- Added full support for Softmax op.
- Made CNTK broadcast ops compatible with ONNX specification.
- Handle to_batch, to_sequence, unpack_batch, sequence.unpack ops in CNTK ONNX exporter.
- ONNX tests to export ONNX test cases for other toolkits to run and to validate.
- Fixed
Hardmax/Softmax/LogSoftmaximport/export. - Added support for
Selectop export. - Added import/export support for several trigonometric ops.
- Updated CNTK support for ONNX
MatMulop. - Updated CNTK support for ONNX
Gemmop. - Updated CNTK's ONNX
MeanVarianceNormalizationop export/import to latest spec. - Updated CNTK's ONNX
LayerNormalizationop export/import to latest spec. - Updated CNTK's ONNX
PReluop export/import to latest spec. - Updated CNTK's ONNX
Gatherop export/import to latest spec. - Updated CNTK's ONNX
ImageScalerop export/import to latest spec. - Updated CNTK's ONNX
Reduceops export/import to latest spec. - Updated CNTK's ONNX
Flattenop export/import to latest spec. - Added CNTK support for ONNX
Unsqueezeop.
- Updated LRN op to match ONNX 1.2 spec where the
sizeattribute has the semantics of diameter, not radius. Added validation if LRN kernel size is larger than channel size. - Updated
Min/Maximport implementation to handle variadic inputs. - Fixed possible file corruption when resaving on top of existing ONNX model file.
The Cntk.Core.Managed library has officially been converted to .Net Standard and supports .Net Core and .Net Framework applications on both Windows and Linux. Starting from this release, .Net developers should be able to restore CNTK Nuget packages using new .Net SDK style project file with package management format set to PackageReference.
The following C# code now works on both Windows and Linux:
>>> var weightParameterName = "weight";
>>> var biasParameterName = "bias";
>>> var inputName = "input";
>>> var outputDim = 2;
>>> var inputDim = 3;
>>> Variable inputVariable = Variable.InputVariable(new int[] { inputDim }, DataType.Float, inputName);
>>> var weightParameter = new Parameter(new int[] { outputDim, inputDim }, DataType.Float, 1, device, weightParameterName);
>>> var biasParameter = new Parameter(new int[] { outputDim }, DataType.Float, 0, device, biasParameterName);
>>>
>>> Function modelFunc = CNTKLib.Times(weightParameter, inputVariable) + biasParameter;
For example, simply adding an ItemGroup clause in the .csproj file of a .Net Core application is sufficient: >>> >>> >>> >>> netcoreapp2.1 >>> x64 >>> >>> >>> >>> >>> >>> >>>
- Fixed C# string and char to native wstring and wchar UTF conversion issues on Linux.
- Fixed multibyte and wide character conversions across the codebase.
- Fixed Nuget package mechanism to pack for .Net Standard.
- Fixed a memory leak issue in Value class in C# API where Dispose was not called upon object destruction.
2018-04-16. CNTK 2.5.1
Repack CNTK 2.5 with third party libraries included in the bundles (Python wheel packages)
2018-03-15. CNTK 2.5
Change profiler details output format to be chrome://tracing
Enable per-node timing. Working example here
- per-node timing creates items in profiler details when profiler is enabled.
- usage in Python:
import cntk as C
C.debugging.debug.set_node_timing(True)
C.debugging.start_profiler() # optional
C.debugging.enable_profiler() # optional
#<trainer|evaluator|function> executions
<trainer|evaluator|function>.print_node_timing()
C.debugging.stop_profiler()Example profiler details view in chrome://tracing

CPU inference performance improvements using MKL
- Accelerates some common tensor ops in Intel CPU inference for float32, especially for fully connected networks
- Can be turned on/off by
cntk.cntk_py.enable_cpueval_optimization()/cntk.cntk_py.disable_cpueval_optimization()
1BitSGD incorporated into CNTK
1BitSGDsource code is now available with CNTK license (MIT license) underSource/1BitSGD/1bitsgdbuild target was merged into existing gpu target
New loss function: hierarchical softmax
- Thanks @yaochengji for the contribution!
Distributed Training with Multiple Learners
- Trainer now accepts multiple parameter learners for distributed training. With this change, different parameters of a network can be learned by different learners in a single training session. This also facilitates distributed training for GANs. For more information, please refer to the Basic_GAN_Distributed.py and the cntk.learners.distributed_multi_learner_test.py
Operators
- Added
MeanVarianceNormalizationoperator.
Bug fixes
- Fixed convergence issue in Tutorial 201B
- Fixed pooling/unpooling to support free dimension for sequences
- Fixed crash in
CNTKBinaryFormatdeserializer when crossing sweep boundary - Fixed shape inference bug in RNN step function for scalar broadcasting
- Fixed a build bug when
mpi=no - Improved distributed training aggregation speed by increasing packing threshold, and expose the knob in V2
- Fixed a memory leak in MKL layout
- Fixed a bug in
cntk.convertAPI inmisc.converter.py, which prevents converting complex networks.
ONNX
- Updates
- CNTK exported ONNX models are now
ONNX.checkercompliant. - Added ONNX support for CNTK’s
OptimizedRNNStackoperator (LSTM only). - Added support for LSTM and GRU operators
- Added support for experimental ONNX op
MeanVarianceNormalization. - Added support for experimental ONNX op
Identity. - Added support for exporting CNTK’s
LayerNormalizationlayer using ONNXMeanVarianceNormalizationop.
- CNTK exported ONNX models are now
- Bug or minor fixes:
- Axis attribute is optional in CNTK’s ONNX
Concatoperator. - Bug fix in ONNX broadcasting for scalars.
- Bug fix in ONNX ConvTranspose operator.
- Backward compatibility bug fix in
LeakyReLu(argument ‘alpha’ reverted to type double).
- Axis attribute is optional in CNTK’s ONNX
Misc
- Added a new API
find_by_uid()undercntk.logging.graph.
2018-02-28. CNTK supports nightly build
If you prefer to use latest CNTK bits from master, use one of the CNTK nightly package.
Alternatively, you can also click corresponding build badge to land to nightly build page.
2018-01-31. CNTK 2.4
Highlights:
- Moved to CUDA9, cuDNN 7 and Visual Studio 2017.
- Removed Python 3.4 support.
- Added Volta GPU and FP16 support.
- Better ONNX support.
- CPU perf improvement.
- More OPs.
OPs
top_koperation: in the forward pass it computes the top (largest) k values and corresponding indices along the specified axis. In the backward pass the gradient is scattered to the top k elements (an element not in the top k gets a zero gradient).gatheroperation now supports an axis argumentsqueezeandexpand_dimsoperations for easily removing and adding singleton axeszeros_likeandones_likeoperations. In many situations you can just rely on CNTK correctly broadcasting a simple 0 or 1 but sometimes you need the actual tensor.depth_to_space: Rearranges elements in the input tensor from the depth dimension into spatial blocks. Typical use of this operation is for implementing sub-pixel convolution for some image super-resolution models.space_to_depth: Rearranges elements in the input tensor from the spatial dimensions to the depth dimension. It is largely the inverse of DepthToSpace.sumoperation: Create a new Function instance that computes element-wise sum of input tensors.softsignoperation: Create a new Function instance that computes the element-wise softsign of a input tensor.asinhoperation: Create a new Function instance that computes the element-wise asinh of a input tensor.log_softmaxoperation: Create a new Function instance that computes the logsoftmax normalized values of a input tensor.hard_sigmoidoperation: Create a new Function instance that computes the hard_sigmoid normalized values of a input tensor.element_and,element_not,element_or,element_xorelement-wise logic operationsreduce_l1operation: Computes the L1 norm of the input tensor's element along the provided axes.reduce_l2operation: Computes the L2 norm of the input tensor's element along the provided axes.reduce_sum_squareoperation: Computes the sum square of the input tensor's element along the provided axes.image_scaleroperation: Alteration of image by scaling its individual values.
ONNX
- There have been several improvements to ONNX support in CNTK.
- Updates
- Updated ONNX
Reshapeop to handleInferredDimension. - Adding
producer_nameandproducer_versionfields to ONNX models. - Handling the case when neither
auto_padnorpadsatrribute is specified in ONNXConvop.
- Updated ONNX
- Bug fixes
- Fixed bug in ONNX
Poolingop serialization - Bug fix to create ONNX
InputVariablewith only one batch axis. - Bug fixes and updates to implementation of ONNX
Transposeop to match updated spec. - Bug fixes and updates to implementation of ONNX
Conv,ConvTranspose, andPoolingops to match updated spec.
- Fixed bug in ONNX
Operators
- Group convolution
- Fixed bug in group convolution. Output of CNTK
Convolutionop will change for groups > 1. More optimized implementation of group convolution is expected in the next release. - Better error reporting for group convolution in
Convolutionlayer.
- Fixed bug in group convolution. Output of CNTK
Halide Binary Convolution
- The CNTK build can now use optional Halide libraries to build
Cntk.BinaryConvolution.so/dlllibrary that can be used with thenetoptmodule. The library contains optimized binary convolution operators that perform better than the python based binarized convolution operators. To enable Halide in the build, please download Halide release and setHALIDE_PATHenvironment varibale before starting a build. In Linux, you can use./configure --with-halide[=directory]to enable it. For more information on how to use this feature, please refer to How_to_use_network_optimization.
See more in the Release Notes. Get the Release from the CNTK Releases page.