Rapid Crew is built using various recommandation algorithms such as popularity based ,content based and collaborative filtering.
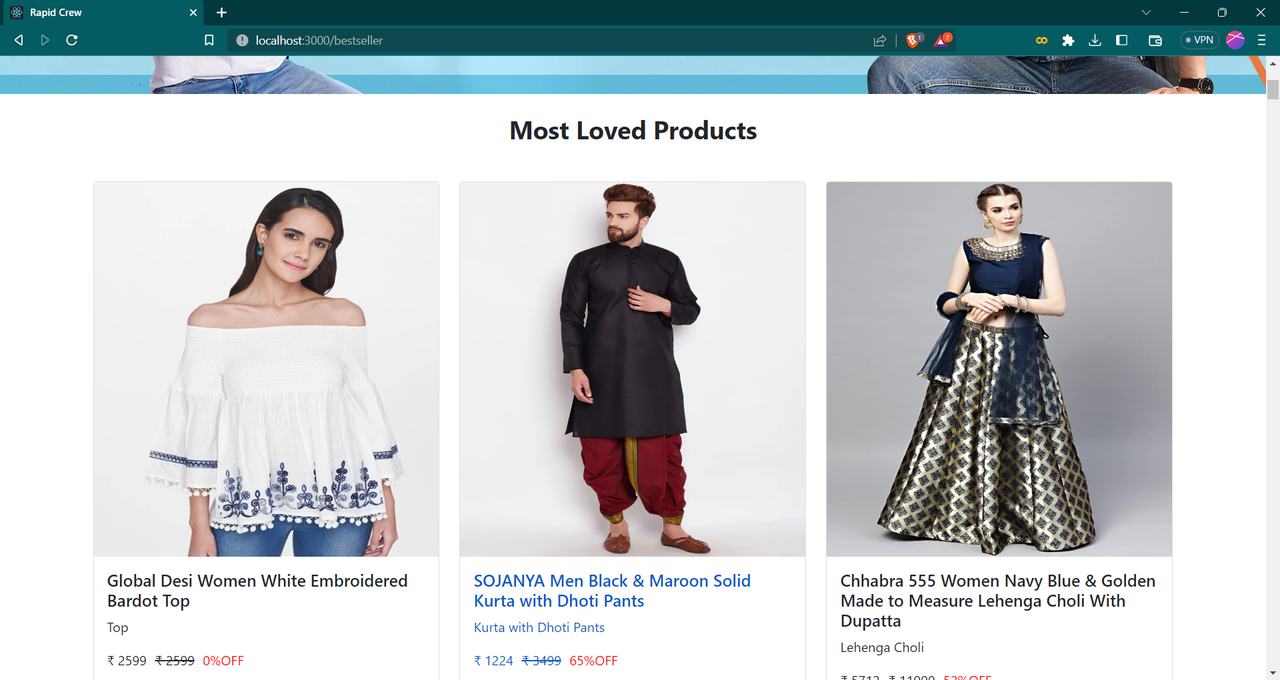
Popularity Based Recommender System works on the principle of popularity and or anything which is in trend. It recommends products based on Total Number of Ratings on products and average product rating given by users and fetch popular amongst them.
Content Based Recommender System works on the principle of similar content. It recommends products based on similar content of the product.The model recommands similar products to the user based on cosine similarity.
The whole Dataset Has been taken from kaggle. This dataset holds 15K records. It is a product listing from Myntra.com for the period of June 2019 to August 2019.
Dataset Link: https://www.kaggle.com/datasets/promptcloud/all-products-from-myntracom-2019
Link to youtube demo:
The main goal of this project is to provide a personalized fashion recommendation system that can help users find fashion products that match their preferences. The system also aims to provide an interactive user interface that is easy to use and navigate.
The first step in developing this project was to collect and prepare the dataset of 17000 Myntra products. Next, different machine learning algorithms such as popularity-based, collaborative filtering, hybrid, and ResNet-based feature extraction were trained using this dataset. Then, these algorithms and features were integrated into the Flask backend.
For the front-end, Reactjs and Bootstrap were used to create an interactive user interface. Firebase authentication was also integrated into the system to ensure secure user authentication.
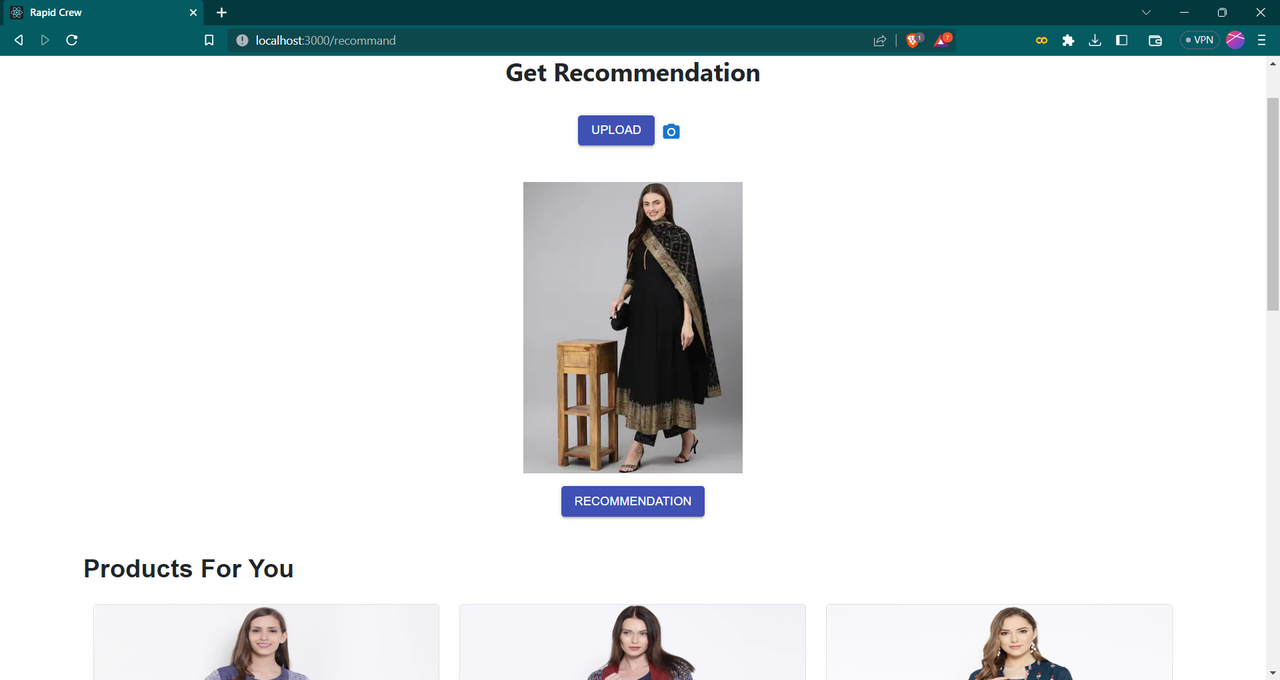
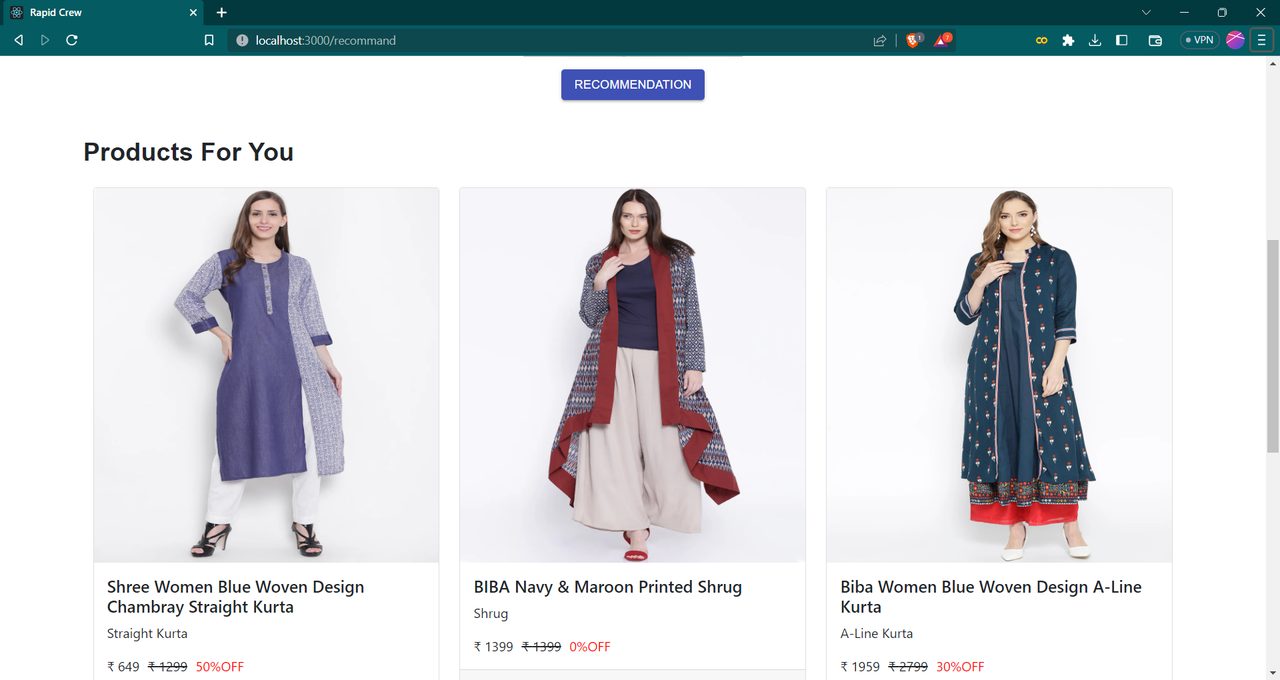
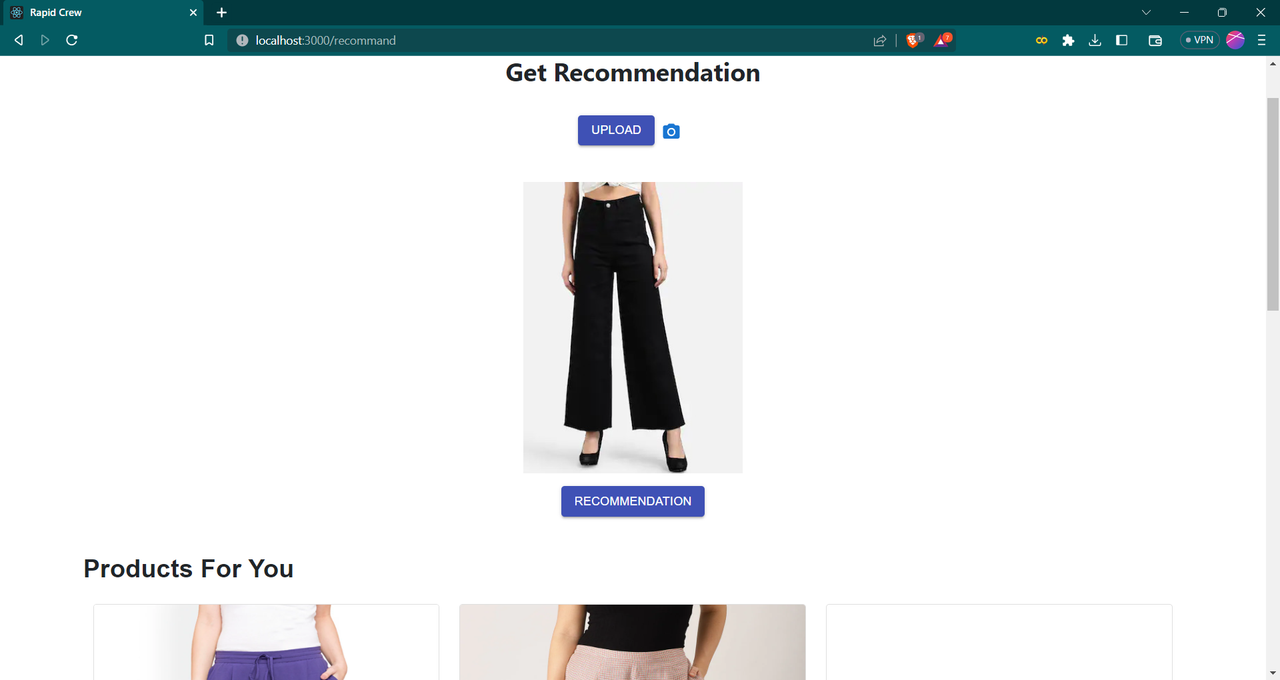
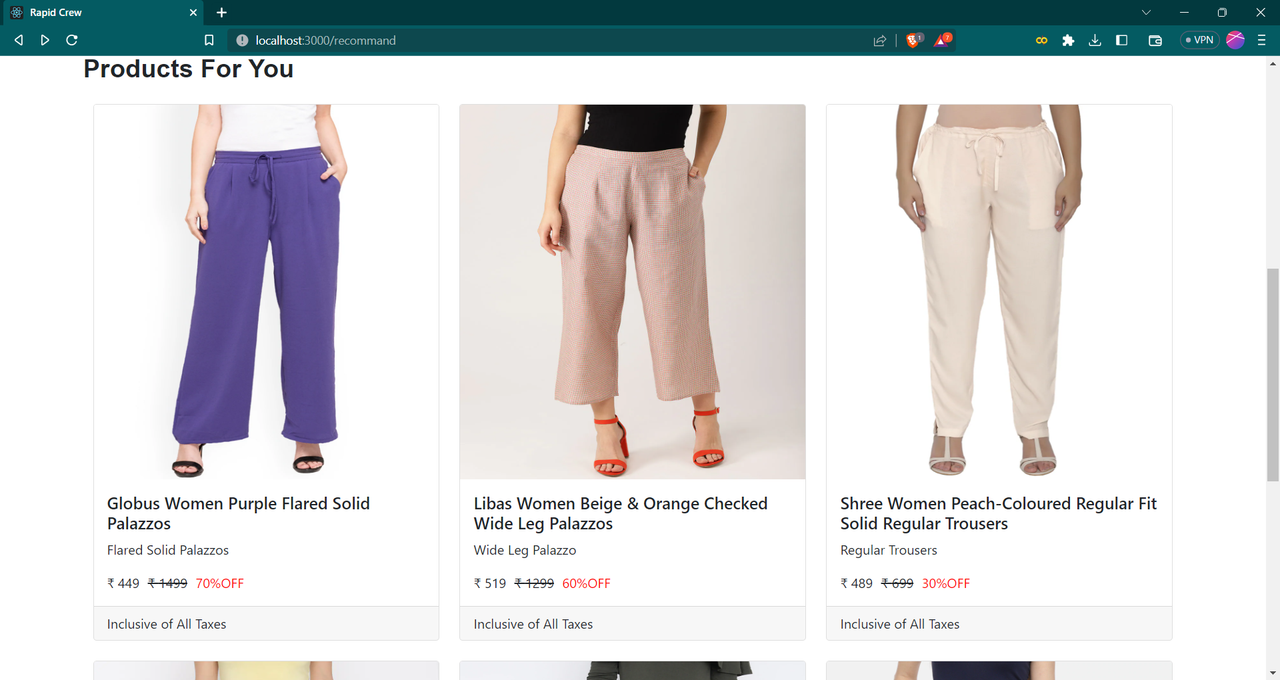
1. Image-based fashion recommendation:
Users can upload images of fashion products they like, and the system will recommend similar products based on the ResNet-based feature extraction.
2. Different recommendation algorithms:
The system uses different recommendation algorithms such as popularity-based, collaborative filtering, and hybrid to provide a variety of recommendations to users.
3. Personalized recommendations:
The system provides personalized recommendations to users based on their preferences and past interactions with the website.
4. Secure authentication:
Firebase authentication is used to ensure that only authorized users can access the website.
5. Interactive user interface:
The system has an interactive user interface created using Reactjs and Bootstrap, making it easy for users to navigate and use the website.
The Dataset used in this project is taken from kaggle. It is a product listing from Myntra.com for the period of June 2019 to August 2019. This dataset holds 15K records.
Dataset Link: https://www.kaggle.com/datasets/promptcloud/all-products-from-myntracom-2019
Download All Resources from here: https://drive.google.com/drive/folders/1GZb2v7vEoJopgDJubD3MwFCSkLFI15uq?usp=sharing
Client: React, Materil-UI, react-bootstrap
Server: Python, Flask
Database: Firebase
Clone the project
git clone https://github.com/Priyanshu9898/Rapid-crewGo to the project directory
cd Rapid-crewGo to requirements.txt file in the same folder and install all required dependencies.
npm installTo run this project, you will need to add the following environment variables to your firebase.js file
API_KEY: "AIzaSyDapzyVgu5Nv4i3s7TIw5fKFIeLS4YDB9g",
authDomain : "rapid-crew-1947c.firebaseapp.com",
projectId: "rapid-crew-1947c",
storageBucket: "rapid-crew-1947c.appspot.com",
messagingSenderId: "674640692953",
appId: "1:674640692953:web:c8e98832e1fa86a3ffa0c8",
measurementId: "G-QX9814DMG9",
Start the server
npm run startRuns the app in the development mode.
Open http://localhost:3000 to view it in your browser.
Open new terminal and run
cd Rapid-crew/backendCreate Virtual Environment in Python
pip install virtualenv virtualenv envFor Windows
.\env\Scripts\activateFor Mac
source env/bin/activateInstall all python modules which are in backend/requirements.txt file
pip install -r requirements.txtCreate .flaskenv file and add these 2 code in it
FLASK_ENV=development
FLASK_APP=app.py
Download backend_files from here: https://drive.google.com/drive/u/0/folders/1GZb2v7vEoJopgDJubD3MwFCSkLFI15uq
Add these files inside backend folder.
Folder structure may look like this:

Run this command to start the server
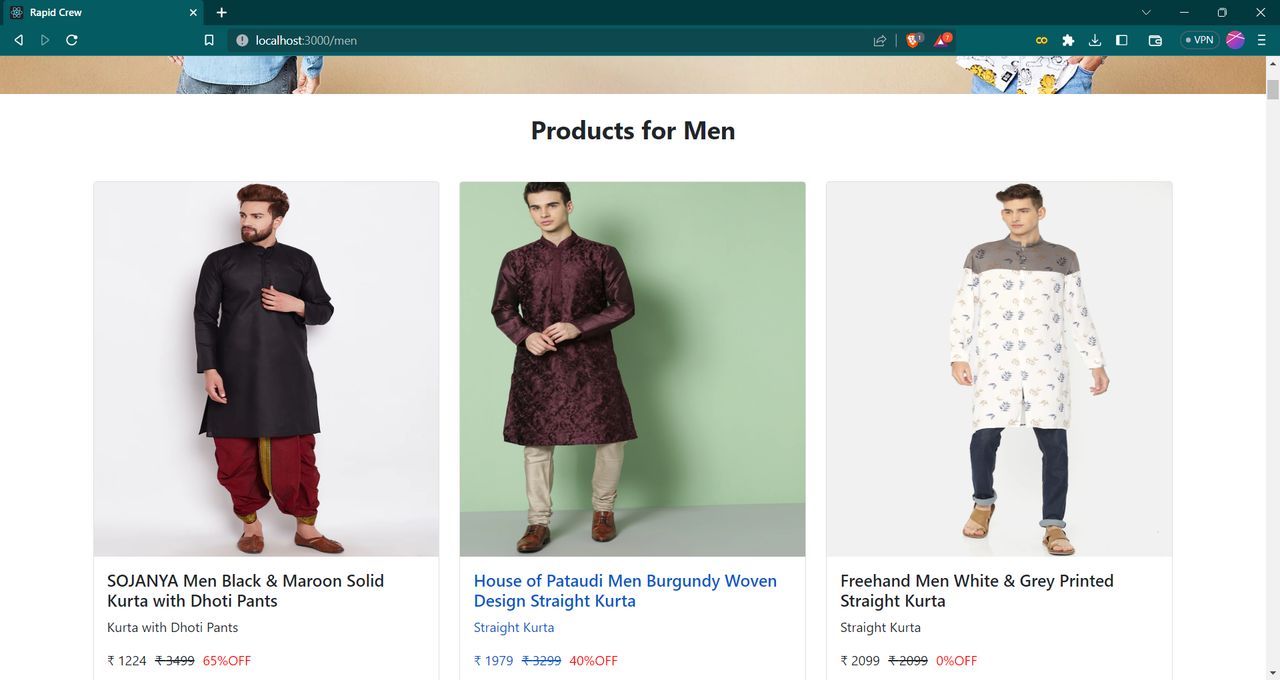
flask run GET /api/bestsellers
GET /menProducts
GET /womenProducts
GET /allProducts
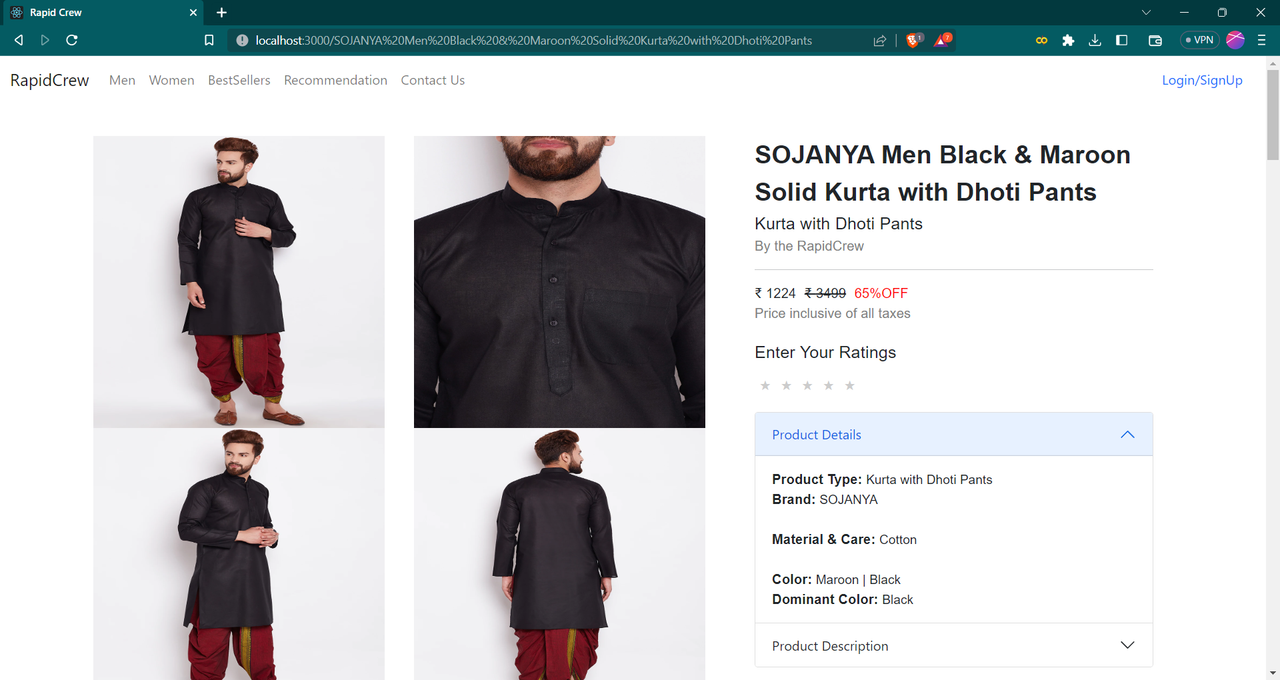
GET /prod/${title}
| Parameter | Type | Description |
|---|---|---|
title |
string |
Title of the product from which fetch all similar products |
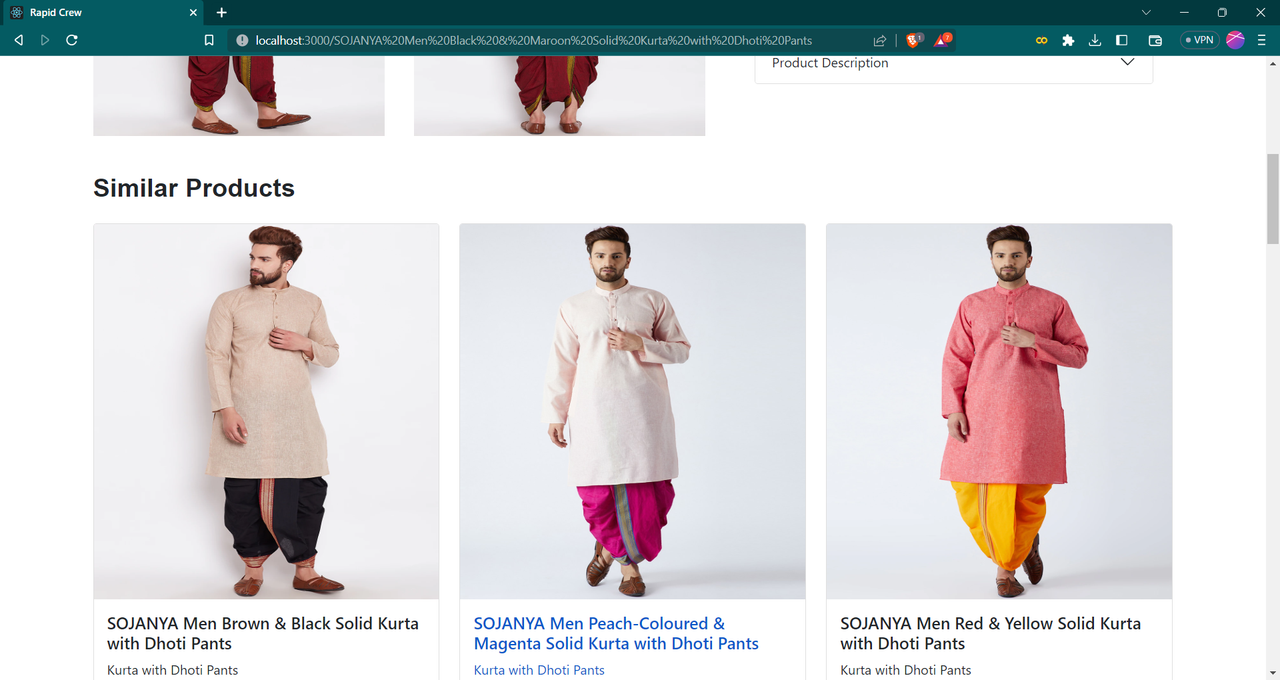
GET /recommand/${title}
| Parameter | Type | Description |
|---|---|---|
title |
string |
Title of the product from which fetch related products which user should buy based on ratings |
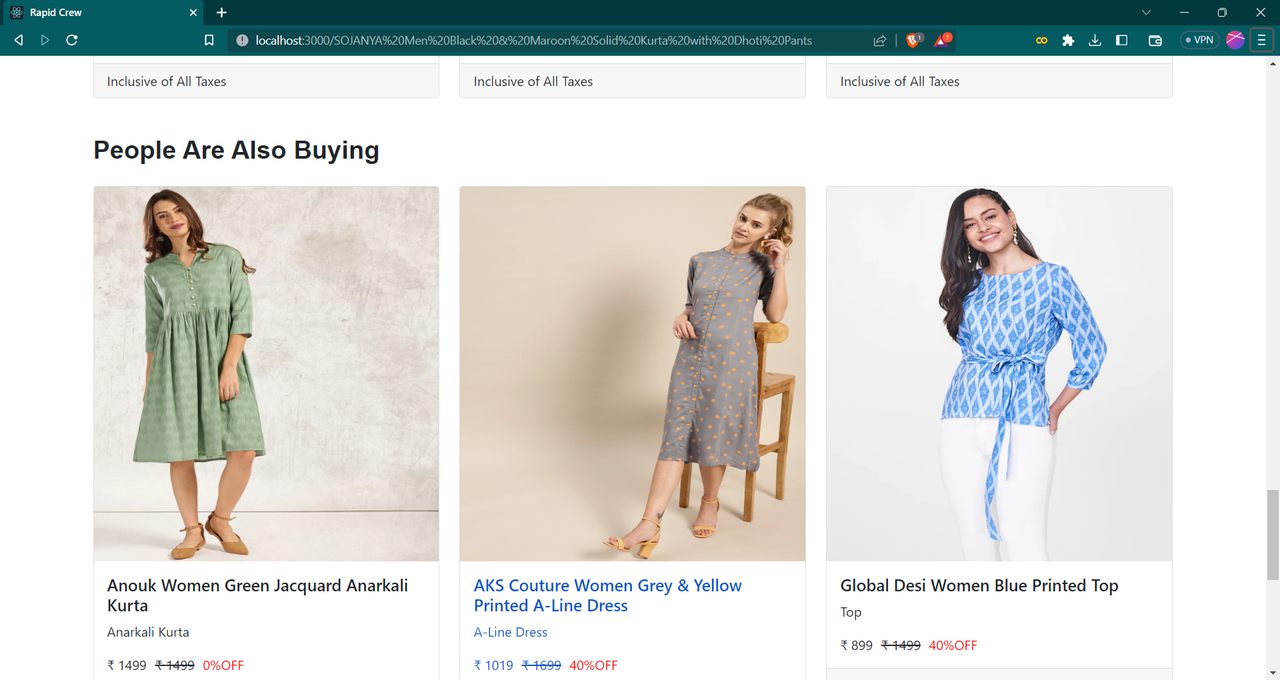
get the similar products available on website based on image- Fashion recommandation using Resnet model
GET /imageData
POST /imageData
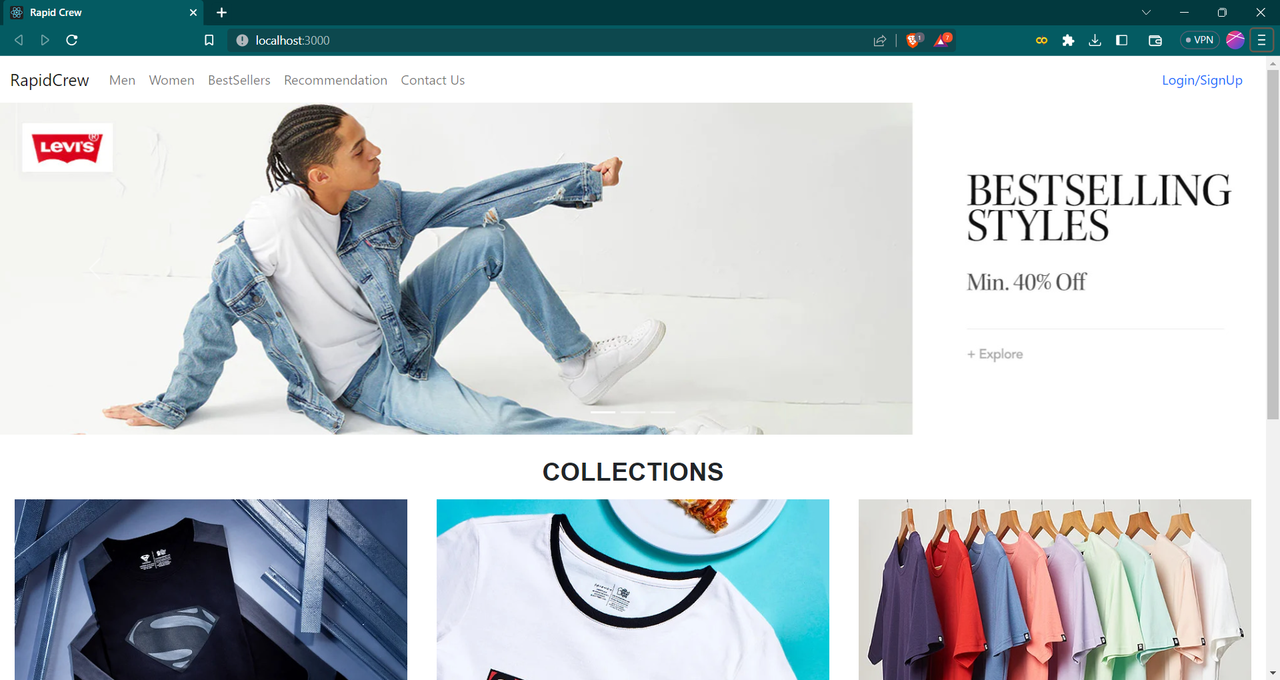
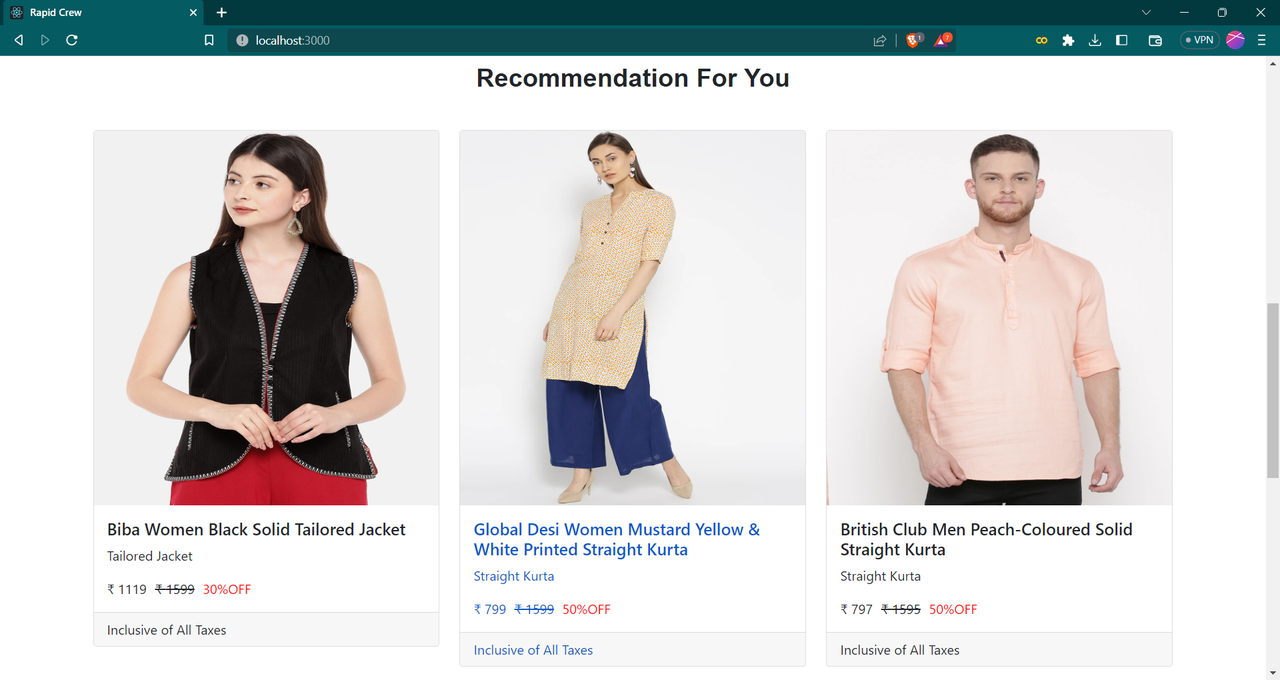
In my myntra dataset, it has many null values available and data of columns were not suitable for training the model so for the efficient model training, feature engineering of the dataset was needed. I have created various functions for perticular column to preprocess the data.
As the name suggests Popularity based recommendation system works with the trend. By using ratings dataset, I found total no. of ratings on each products and average ratings of products. Then I separete products based on threshold value which I applied on totalRatings and sort products in decending order of average rating. This is how I got popular 100 products.
In this recommender system the content of the product (actual_color, dominant_color, product_type, product_details, complete_the_look, inventory, specifications etc) is used to find its similarity with other products. I combined content of the product into one corpus by doing preprocessing on text and then apply lemmatization and remove stopwords from corpus of data using nltk (natural language processing toolkit) library.
Then by TfidfVectorizer in sklearn library, I convert my corpus of Data into vectors.
Now, I applied sigmoid_kernel through sklearn, I find the cosine similarity between products.
How does it decide which item is most similar to the item user likes? Here come the similarity scores.
It is a numerical value ranges between zero to one which helps to determine how much two items are similar to each other on a scale of zero to one. This similarity score is obtained measuring the similarity between the text details of both of the items. So, similarity score is the measure of similarity between given text details of two items. This can be done by cosine-similarity.
Then the products that are most likely to be similar are recommended.

The cosine similarity metric is used to determine how similar documents are regardless of their size. It estimates the cosine of the angle formed by two vectors projected in a multi-dimensional space mathematically. Because of the cosine similarity, even if two comparable documents are separated by the Euclidean distance (due to the size of the documents), they are likely to be orientated closer together. The higher the cosine similarity, the smaller the angle.

Collaborative Filtering doesn’t need anything else except users’ historical preference on a set of items. Because it’s based on historical data, the core assumption here is that the users who have agreed in the past tend to also agree in the future.
Basically, the idea is to find the most similar users to your target user (nearest neighbors) and weight their ratings of an item as the prediction of the rating of this item for target user.
What matrix factorization eventually gives us is how much a user is aligned with a set of latent features, and how much a movie fits into this set of latent features.

Resnet is a pre trained image processing model. I used resnet which is a backbone of computer vision tasks to extract features from the images available in my dataset. I also extract features of uploaded image using resnet model. Then using Nearest Neighbour classifier I get the nearest similar products and show it to user.