
You have an environment, a PyTorch model, and a reinforcement learning framework that are designed to work together but don’t. PufferLib is a wrapper layer that makes RL on complex game environments as simple as RL on Atari. You write a native PyTorch network and a short binding for your environment; PufferLib takes care of the rest.
All of our Documentation is hosted by github.io. @jsuarez5341 on Discord for support -- post here before opening issues. I am also looking for contributors interested in adding bindings for other environments and RL frameworks.
The current demo.py is a souped-up version of CleanRL PPO with optimized LSTM support, detailed performance metrics, a local dashboard, async envpool sampling, checkpointing, wandb sweeps, and more. It has a powerful --help that generates options based on the specified environment and policy. Hyperparams are in config.yaml. A few examples:
# Train minigrid with multiprocessing. Save it as a baseline.
python demo.py --env minigrid --mode train --vec multiprocessing
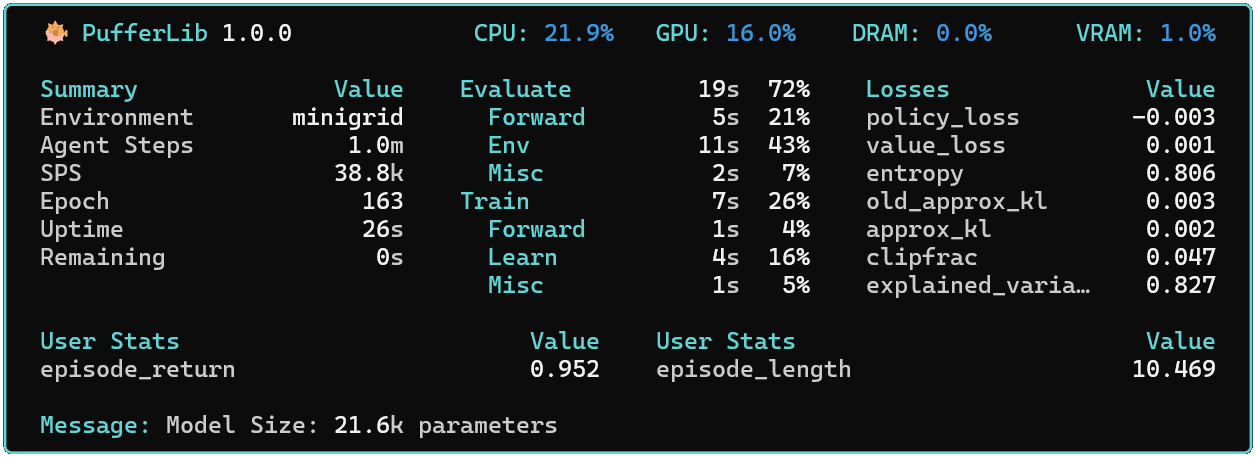
# Load the current minigrid baseline and render it locally
python demo.py --env minigrid --mode eval --baseline
# Train squared with serial vectorization and save it as a wandb baseline
# The, load the current squared baseline and render it locally
python demo.py --env squared --mode train --baseline
python demo.py --env squared --mode eval --baseline
# Render NMMO locally with a random policy
python demo.py --env nmmo --mode eval
# Autotune vectorization settings for your machine
python demo.py --env breakout --mode autotune