{kind=link}
フィールドはカンマで区切り、行は改行で分けるノーマルなcsvを扱うモジュール
csvデータからTwoDimArrayを作成し二次元配列として処理する
※セパレータはデフォルトでカンマとなっているが、任意に指定可能で正規表現も指定できる
※フィールドの左右の空白は無視する(' hoge fuga ' -> 'hoge fuga')
- 特徴
- 種類が豊富でカスタマイズ可能なテキストテーブル
- 視認性が高いテキスト表示機能
- 充実したデータ編集機能
- 簡単なデータ集計機能
- 魔方陣も作成できるよ
csvファイルから作成
#----------------------------------------------------------------------------------------------------
# TwoDimArrayの作成方法: csvファイルから作成
#----------------------------------------------------------------------------------------------------
>>> import csv_normal as csv
# sample.csvファイルからcsvデータを読み込み、TwoDimArray(二次元配列)を作成
>>> c = csv.load('sample.csv', encoding='utf8')
# 行列のサイズを確認
>>> c.shape()
(7, 8)
2次元配列から作成
#----------------------------------------------------------------------------------------------------
# TwoDimArrayの作成方法: 2次元配列から作成
#----------------------------------------------------------------------------------------------------
>>> import csv_normal as csv
>>> m = csv.TwoDimArray([[1],[1,2],[1,2,3],[1,2,3,4],[1,2,3],[1,2],[1]])
>>> m.print()
1
1, 2
1, 2, 3
1, 2, 3, 4
1, 2, 3
1, 2
1
文字列(csv)から作成
#----------------------------------------------------------------------------------------------------
# TwoDimArrayの作成方法: 文字列(csv)から作成
#----------------------------------------------------------------------------------------------------
>>> import csv_normal as csv
>>> t = csv.csv2tda("""
hoge, fuga, HOGE, FUGA
a,b,c,d
123,12345,1234567,123456789
""")
>>>
>>> t.trim() # 空の行、空の列を削除
>>> t.print()
hoge, fuga , HOGE , FUGA
a , b , c , d
123, 12_345, 1_234_567, 123_456_789
辞書から作成
#----------------------------------------------------------------------------------------------------
# TwoDimArrayの作成方法: 辞書から作成
#----------------------------------------------------------------------------------------------------
>>> import csv_normal as csv
>>> import numpy as np
>>> d= {'NAME': list('ABCDEFG'), 'VALUE_1': np.random.randn(7), 'VALUE_2': np.random.randn(7)}
>>> h = csv.dict2tda(d)
>>> h.print()
NAME, VALUE_1, VALUE_2
A , 0.40, 1.63
B , -1.37, 0.64
C , -0.06, 0.87
D , 0.44, 0.73
E , -1.30, -1.11
F , -1.73, 0.17
G , -0.82, -0.94
# floatの精度(小数点以下の桁数)を調整可能
>>> h.precision = 10
>>> h.print()
NAME, VALUE_1 , VALUE_2
A , 0.4003742639, 1.6272049722
B , -1.3694450047, 0.6399934786
C , -0.0633841457, 0.8659692839
D , 0.4384958907, 0.7319732920
E , -1.2958969709, -1.1108404649
F , -1.7329270126, 0.1683664238
G , -0.8177787733, -0.9438108092
>>> h.print2()
+----+--------------+--------------+
|NAME|VALUE_1 |VALUE_2 |
+----+--------------+--------------+
|A | 0.4003742639| 1.6272049722|
+----+--------------+--------------+
|B | -1.3694450047| 0.6399934786|
+----+--------------+--------------+
|C | -0.0633841457| 0.8659692839|
+----+--------------+--------------+
|D | 0.4384958907| 0.7319732920|
+----+--------------+--------------+
|E | -1.2958969709| -1.1108404649|
+----+--------------+--------------+
|F | -1.7329270126| 0.1683664238|
+----+--------------+--------------+
|G | -0.8177787733| -0.9438108092|
+----+--------------+--------------+
numpyのndarrayから作成
#----------------------------------------------------------------------------------------------------
# TwoDimArrayの作成方法: numpyのndarrayから作成
#----------------------------------------------------------------------------------------------------
>>> import csv_normal as csv
>>>import numpy as np
>>>nd1 = np.array([1,2,3,4,5,6,7,8])
>>>csv.nd2tda(nd1).print2()
+--+--+--+--+--+--+--+--+
| 1| 2| 3| 4| 5| 6| 7| 8|
+--+--+--+--+--+--+--+--+
>>>nd2 = np.array([[1,2,3,4],[5,6,7,8]])
>>>csv.nd2tda(nd2).print2()
+--+--+--+--+
| 1| 2| 3| 4|
+--+--+--+--+
| 5| 6| 7| 8|
+--+--+--+--+
>>>nd3 = np.array([[[1,2],[3,4]],[[5,6],[7,8]]])
>>>csv.nd2tda(nd3).print2()
+------+------+
|[1, 2]|[3, 4]|
+------+------+
|[5, 6]|[7, 8]|
+------+------+
pandasのDataFrameから作成
#----------------------------------------------------------------------------------------------------
# TwoDimArrayの作成方法: pandasのDataFrameから作成
#----------------------------------------------------------------------------------------------------
>>> import csv_normal as csv
>>>import pandas as pd
>>>df = pd.DataFrame({
'名前': ['佐藤', '斎藤', '鈴木', '田中'],
'年齢': [21, 30, 45, 16],
'住所': ['東京都', '岐阜県', '埼玉県', '大阪'],
'血液型': ['A', 'AB', 'O', 'O'],
'レベル': [6, 7, 5, 9],
'ポイント': [2900, 3400, 2500, 5100],
})
>>>df
名前 年齢 住所 血液型 レベル ポイント
0 佐藤 21 東京都 A 6 2900
1 斎藤 30 岐阜県 AB 7 3400
2 鈴木 45 埼玉県 O 5 2500
3 田中 16 大阪 O 9 5100
>>>csv.df2tda(df).print2()
+----+----+------+------+------+--------+
|名前|年齢|住所 |血液型|レベル|ポイント|
+----+----+------+------+------+--------+
|佐藤| 21|東京都|A | 6| 2_900|
+----+----+------+------+------+--------+
|斎藤| 30|岐阜県|AB | 7| 3_400|
+----+----+------+------+------+--------+
|鈴木| 45|埼玉県|O | 5| 2_500|
+----+----+------+ +------+--------+
|田中| 16|大阪 |O | 9| 5_100|
+----+----+------+------+------+--------+
>>>csv.df2tda(df, index=True).print2()
+--+----+----+------+------+------+--------+
| |名前|年齢|住所 |血液型|レベル|ポイント|
+--+----+----+------+------+------+--------+
| 0|佐藤| 21|東京都|A | 6| 2_900|
+--+----+----+------+------+------+--------+
| 1|斎藤| 30|岐阜県|AB | 7| 3_400|
+--+----+----+------+------+------+--------+
| 2|鈴木| 45|埼玉県|O | 5| 2_500|
+--+----+----+------+ +------+--------+
| 3|田中| 16|大阪 |O | 9| 5_100|
+--+----+----+------+------+------+--------+
表示の基本操作, 枠のグループ化, 枠の設定&カスタマイズ, 区切り文字
#----------------------------------------------------------------------------------------------------
# TwoDimArrayの表示方法: 表示の基本操作, 枠のグループ化, 枠の設定&カスタマイズ, 区切り文字
#----------------------------------------------------------------------------------------------------
>>> import csv_normal as csv
# sample.csvファイルからcsvデータを読み込み、TwoDimArray(二次元配列)を作成
>>> c = csv.load('sample.csv', encoding='utf8')
# 行列のサイズを確認
>>> c.shape()
(7, 8)
# print関数でTwoDimArrayを行列表示(先頭5行まで表示し、残りは省略表示する)
>>> print(c)
Name , Strength , Buttle Power, Birthdate , Sex , Race , Height(cm), Weight(kg)
Goku , very strong, 3_000_000, Age-737-year, Male , Saiyan , 175, 62
Vegeta , very strong, 2_000_000, Age-732-year, Male , Saiyan , 164, 56
Piccolo, strong , 1_000_000, Age-753-year, Male , Namekian , 226, 116
Bulma , very weak , 3, Age-733-year, Female, Earthling, 165, 49
↓(There are 2 rows)
# printメソッドでTwoDimArrayを行列表示(全データを表示する)
>>> c.print()
Name , Strength , Buttle Power, Birthdate , Sex , Race , Height(cm), Weight(kg)
Goku , very strong, 3_000_000, Age-737-year, Male , Saiyan , 175, 62
Vegeta , very strong, 2_000_000, Age-732-year, Male , Saiyan , 164, 56
Piccolo, strong , 1_000_000, Age-753-year, Male , Namekian , 226, 116
Bulma , very weak , 3, Age-733-year, Female, Earthling, 165, 49
Krillin, good , 75_000, Age-736-year, Male , Earthling, 153, 45
Yamcha , weak , 1_480, Age-733-year, Male , Earthling, 183, 68
# printメソッドはTwoDimArrayの表示範囲を選択できる
>>> c.print(3)
Name , Strength , Buttle Power, Birthdate , Sex , Race , Height(cm), Weight(kg)
Goku , very strong, 3_000_000, Age-737-year, Male, Saiyan, 175, 62
Vegeta, very strong, 2_000_000, Age-732-year, Male, Saiyan, 164, 56
↓(There are 4 rows)
# print2メソッドはTwoDimArrayを枠で囲んで表示する(表示範囲の選択も可能)
>>> c.print2()
+--------+------------+------------+------------+------+----------+----------+----------+
|Name |Strength |Buttle Power|Birthdate |Sex |Race |Height(cm)|Weight(kg)|
+--------+------------+------------+------------+------+----------+----------+----------+
|Goku |very strong | 3_000_000|Age-737-year|Male |Saiyan | 175| 62|
+--------+ +------------+------------+ + +----------+----------+
|Vegeta |very strong | 2_000_000|Age-732-year|Male |Saiyan | 164| 56|
+--------+------------+------------+------------+ +----------+----------+----------+
|Piccolo |strong | 1_000_000|Age-753-year|Male |Namekian | 226| 116|
+--------+------------+------------+------------+------+----------+----------+----------+
|Bulma |very weak | 3|Age-733-year|Female|Earthling | 165| 49|
+--------+------------+------------+------------+------+ +----------+----------+
|Krillin |good | 75_000|Age-736-year|Male |Earthling | 153| 45|
+--------+------------+------------+------------+ + +----------+----------+
|Yamcha |weak | 1_480|Age-733-year|Male |Earthling | 183| 68|
+--------+------------+------------+------------+------+----------+----------+----------+
# デフォルト設定では枠のグループ化機能が有効になっているため、
# 隣接するフィールド値が同じ場合は境界の枠が消えてグループ化される
#
# border_grouping: Falseで枠のグループ化機能を無効にできる
#
>>> c.border_grouping = False
>>> c.print2()
+--------+------------+------------+------------+------+----------+----------+----------+
|Name |Strength |Buttle Power|Birthdate |Sex |Race |Height(cm)|Weight(kg)|
+--------+------------+------------+------------+------+----------+----------+----------+
|Goku |very strong | 3_000_000|Age-737-year|Male |Saiyan | 175| 62|
+--------+------------+------------+------------+------+----------+----------+----------+
|Vegeta |very strong | 2_000_000|Age-732-year|Male |Saiyan | 164| 56|
+--------+------------+------------+------------+------+----------+----------+----------+
|Piccolo |strong | 1_000_000|Age-753-year|Male |Namekian | 226| 116|
+--------+------------+------------+------------+------+----------+----------+----------+
|Bulma |very weak | 3|Age-733-year|Female|Earthling | 165| 49|
+--------+------------+------------+------------+------+----------+----------+----------+
|Krillin |good | 75_000|Age-736-year|Male |Earthling | 153| 45|
+--------+------------+------------+------------+------+----------+----------+----------+
|Yamcha |weak | 1_480|Age-733-year|Male |Earthling | 183| 68|
+--------+------------+------------+------------+------+----------+----------+----------+
# デフォルト設定では数字の区切り文字表示機能(千倍ごとにアンダースコアで数字を区切る)が有効になっている
# ※数値リテラル内のアンダースコアはPython3.6から追加された新機能
#
# grouping_opt: Falseで数字の区切り文字表示機能を無効にできる
#
>>> c.grouping_opt = False
>>> c.print2()
+--------+------------+------------+------------+------+----------+----------+----------+
|Name |Strength |Buttle Power|Birthdate |Sex |Race |Height(cm)|Weight(kg)|
+--------+------------+------------+------------+------+----------+----------+----------+
|Goku |very strong | 3000000|Age-737-year|Male |Saiyan | 175| 62|
+--------+------------+------------+------------+------+----------+----------+----------+
|Vegeta |very strong | 2000000|Age-732-year|Male |Saiyan | 164| 56|
+--------+------------+------------+------------+------+----------+----------+----------+
|Piccolo |strong | 1000000|Age-753-year|Male |Namekian | 226| 116|
+--------+------------+------------+------------+------+----------+----------+----------+
|Bulma |very weak | 3|Age-733-year|Female|Earthling | 165| 49|
+--------+------------+------------+------------+------+----------+----------+----------+
|Krillin |good | 75000|Age-736-year|Male |Earthling | 153| 45|
+--------+------------+------------+------------+------+----------+----------+----------+
|Yamcha |weak | 1480|Age-733-year|Male |Earthling | 183| 68|
+--------+------------+------------+------------+------+----------+----------+----------+
# print2_borderプロパティで枠の種類を変えられる
>>> c.print2_border = 'Simple'
>>> c.print2()
Name Strength Buttle Power Birthdate Sex Race Height(cm) Weight(kg)
-------- ------------ ------------ ------------ ------ ---------- ---------- ----------
Goku very strong 3000000 Age-737-year Male Saiyan 175 62
Vegeta very strong 2000000 Age-732-year Male Saiyan 164 56
Piccolo strong 1000000 Age-753-year Male Namekian 226 116
Bulma very weak 3 Age-733-year Female Earthling 165 49
Krillin good 75000 Age-736-year Male Earthling 153 45
Yamcha weak 1480 Age-733-year Male Earthling 183 68
>>> c.print2_border = 'Psql'
>>> c.print2()
+--------+------------+------------+------------+------+----------+----------+----------+
|Name |Strength |Buttle Power|Birthdate |Sex |Race |Height(cm)|Weight(kg)|
+--------+------------+------------+------------+------+----------+----------+----------+
|Goku |very strong | 3000000|Age-737-year|Male |Saiyan | 175| 62|
|Vegeta |very strong | 2000000|Age-732-year|Male |Saiyan | 164| 56|
|Piccolo |strong | 1000000|Age-753-year|Male |Namekian | 226| 116|
|Bulma |very weak | 3|Age-733-year|Female|Earthling | 165| 49|
|Krillin |good | 75000|Age-736-year|Male |Earthling | 153| 45|
|Yamcha |weak | 1480|Age-733-year|Male |Earthling | 183| 68|
+--------+------------+------------+------------+------+----------+----------+----------+
# 枠は簡単にカスタマイズ可能
>>> csv.border_patterns['Custom1']="""
o-o-o
| | |
o-o-o
| | |
o-o-o
"""
>>> c.print2_border = 'Custom1'
>>> c.print2()
o--------o------------o------------o------------o------o----------o----------o----------o
|Name |Strength |Buttle Power|Birthdate |Sex |Race |Height(cm)|Weight(kg)|
o--------o------------o------------o------------o------o----------o----------o----------o
|Goku |very strong | 3000000|Age-737-year|Male |Saiyan | 175| 62|
o--------o------------o------------o------------o------o----------o----------o----------o
|Vegeta |very strong | 2000000|Age-732-year|Male |Saiyan | 164| 56|
o--------o------------o------------o------------o------o----------o----------o----------o
|Piccolo |strong | 1000000|Age-753-year|Male |Namekian | 226| 116|
o--------o------------o------------o------------o------o----------o----------o----------o
|Bulma |very weak | 3|Age-733-year|Female|Earthling | 165| 49|
o--------o------------o------------o------------o------o----------o----------o----------o
|Krillin |good | 75000|Age-736-year|Male |Earthling | 153| 45|
o--------o------------o------------o------------o------o----------o----------o----------o
|Yamcha |weak | 1480|Age-733-year|Male |Earthling | 183| 68|
o--------o------------o------------o------------o------o----------o----------o----------o
# reset_propertyメソッドで各プロパティの設定をリセットできる
>>> c.reset_property()
>>> c.print2()
+--------+------------+------------+------------+------+----------+----------+----------+
|Name |Strength |Buttle Power|Birthdate |Sex |Race |Height(cm)|Weight(kg)|
+--------+------------+------------+------------+------+----------+----------+----------+
|Goku |very strong | 3_000_000|Age-737-year|Male |Saiyan | 175| 62|
+--------+ +------------+------------+ + +----------+----------+
|Vegeta |very strong | 2_000_000|Age-732-year|Male |Saiyan | 164| 56|
+--------+------------+------------+------------+ +----------+----------+----------+
|Piccolo |strong | 1_000_000|Age-753-year|Male |Namekian | 226| 116|
+--------+------------+------------+------------+------+----------+----------+----------+
|Bulma |very weak | 3|Age-733-year|Female|Earthling | 165| 49|
+--------+------------+------------+------------+------+ +----------+----------+
|Krillin |good | 75_000|Age-736-year|Male |Earthling | 153| 45|
+--------+------------+------------+------------+ + +----------+----------+
|Yamcha |weak | 1_480|Age-733-year|Male |Earthling | 183| 68|
+--------+------------+------------+------------+------+----------+----------+----------+
インデックスの表示
#----------------------------------------------------------------------------------------------------
# TwoDimArrayの表示方法: インデックスの表示
#----------------------------------------------------------------------------------------------------
>>> import csv_normal as csv
# sample.csvファイルからcsvデータを読み込み、TwoDimArray(二次元配列)を作成
>>> c = csv.load('sample.csv', encoding='utf8')
# 行列のサイズを確認
>>> c.shape()
(7, 8)
# 行と列のインデックスの表示が可能(表示範囲の選択も可能)
>>> c.print_idx()
index, 0 , 1 , 2 , 3 , 4 , 5 , 6 , 7 , index
0, Name , Strength , Buttle Power, Birthdate , Sex , Race , Height(cm), Weight(kg), 0
1, Goku , very strong, 3_000_000, Age-737-year, Male , Saiyan , 175, 62, 1
2, Vegeta , very strong, 2_000_000, Age-732-year, Male , Saiyan , 164, 56, 2
3, Piccolo, strong , 1_000_000, Age-753-year, Male , Namekian , 226, 116, 3
4, Bulma , very weak , 3, Age-733-year, Female, Earthling, 165, 49, 4
5, Krillin, good , 75_000, Age-736-year, Male , Earthling, 153, 45, 5
6, Yamcha , weak , 1_480, Age-733-year, Male , Earthling, 183, 68, 6
index, 0 , 1 , 2 , 3 , 4 , 5 , 6 , 7 , index
# さらに枠で囲んで見やすく表示可能(表示範囲の選択も可能)
>>> c.print_idx2()
index:0 :1 :2 :3 :4 :5 :6 :7 :index
......+--------+------------+------------+------------+------+----------+----------+----------+......
0|Name |Strength |Buttle Power|Birthdate |Sex |Race |Height(cm)|Weight(kg)|0
......+--------+------------+------------+------------+------+----------+----------+----------+......
1|Goku |very strong | 3_000_000|Age-737-year|Male |Saiyan | 175| 62|1
......+--------+ +------------+------------+ + +----------+----------+......
2|Vegeta |very strong | 2_000_000|Age-732-year|Male |Saiyan | 164| 56|2
......+--------+------------+------------+------------+ +----------+----------+----------+......
3|Piccolo |strong | 1_000_000|Age-753-year|Male |Namekian | 226| 116|3
......+--------+------------+------------+------------+------+----------+----------+----------+......
4|Bulma |very weak | 3|Age-733-year|Female|Earthling | 165| 49|4
......+--------+------------+------------+------------+------+ +----------+----------+......
5|Krillin |good | 75_000|Age-736-year|Male |Earthling | 153| 45|5
......+--------+------------+------------+------------+ + +----------+----------+......
6|Yamcha |weak | 1_480|Age-733-year|Male |Earthling | 183| 68|6
......+--------+------------+------------+------------+------+----------+----------+----------+......
index:0 :1 :2 :3 :4 :5 :6 :7 :index
# print_idx2_borderプロパティで枠の種類を変えられる
>>> c.print_idx2_border = 'Index_simple'
>>> c.print_idx2()
index 0 1 2 3 4 5 6 7 index
-------- ------------ ------------ ------------ ------ ---------- ---------- ----------
0|Name Strength Buttle Power Birthdate Sex Race Height(cm) Weight(kg)|0
1|Goku very strong 3_000_000 Age-737-year Male Saiyan 175 62|1
2|Vegeta very strong 2_000_000 Age-732-year Male Saiyan 164 56|2
3|Piccolo strong 1_000_000 Age-753-year Male Namekian 226 116|3
4|Bulma very weak 3 Age-733-year Female Earthling 165 49|4
5|Krillin good 75_000 Age-736-year Male Earthling 153 45|5
6|Yamcha weak 1_480 Age-733-year Male Earthling 183 68|6
-------- ------------ ------------ ------------ ------ ---------- ---------- ----------
index 0 1 2 3 4 5 6 7 index
書式フォーマットの設定 & データの保存方法
#----------------------------------------------------------------------------------------------------
# TwoDimArrayの表示方法: 書式フォーマットの設定 & データの保存方法
#----------------------------------------------------------------------------------------------------
>>> import csv_normal as csv
# sample.csvファイルからcsvデータを読み込み、TwoDimArray(二次元配列)を作成
>>> c = csv.load('sample.csv', encoding='utf8')
# 行列のサイズを確認
>>> c.shape()
(7, 8)
# printメソッドでデータを確認しヘッダーとデータ範囲を設定する
# ヘッダーとデータ範囲を設定することでヘッダーとデータ範囲の書式フォーマットを個別に指定できる
#
# header_idxプロパティにヘッダーのインデックスを設定する
# data_row_rangeプロパティにヘッダー&フッターを含まないデータ範囲をsliceで設定する
#
>>> c.header_idx = 0 # ヘッダーのインデックスを設定
>>> c.data_row_range = slice(1, None) # データ範囲を設定
# 各列の表示書式フォーマットをカスタマイズできる
# ※枠で囲んだ後は調整できないのでprint_chg_formatメソッドで調整&確認後wrap_borderメソッドで囲む
#
# ヘッダー: インデックス0の列は右詰め、それ以外は中央寄せ
# データ: インデックス4の列は左詰め、それ以外は右詰め
# 文字幅: インデックス5の文字幅は5、それ以外は10
#
>>> c.print_chg_format(header_aligns={0:'>', None:'^'}, aligns={4:'<', None:'>'}, widths={5:5, None:10})
Name, Strength , Buttle Power, Birthdate , Sex , Race , Height(cm), Weight(kg)
Goku, very strong, 3_000_000, Age-737-year, Male , Saiyan, 175, 62
Vegeta, very strong, 2_000_000, Age-732-year, Male , Saiyan, 164, 56
Piccolo, strong, 1_000_000, Age-753-year, Male , Namekian, 226, 116
Bulma, very weak, 3, Age-733-year, Female , Earthling, 165, 49
Krillin, good, 75_000, Age-736-year, Male , Earthling, 153, 45
Yamcha, weak, 1_480, Age-733-year, Male , Earthling, 183, 68
# TwoDimArrayを枠で囲む
# 枠の種類(border_pattern)はchk_border関数で確認できる(例ではborder_pattern='Grid'を選択している)
#
>>> c2 = c.wrap_border('Grid', header_aligns={0:'>', None:'^'}, aligns={4:'<', None:'>'}, widths={5:5, None:10})
>>> c2.print()
+----------+------------+------------+------------+----------+----------+----------+----------+
| Name| Strength |Buttle Power| Birthdate | Sex | Race |Height(cm)|Weight(kg)|
+==========+============+============+============+==========+==========+==========+==========+
| Goku| very strong| 3_000_000|Age-737-year|Male | Saiyan| 175| 62|
+----------+ +------------+------------+ + +----------+----------+
| Vegeta| very strong| 2_000_000|Age-732-year|Male | Saiyan| 164| 56|
+----------+------------+------------+------------+ +----------+----------+----------+
| Piccolo| strong| 1_000_000|Age-753-year|Male | Namekian| 226| 116|
+----------+------------+------------+------------+----------+----------+----------+----------+
| Bulma| very weak| 3|Age-733-year|Female | Earthling| 165| 49|
+----------+------------+------------+------------+----------+ +----------+----------+
| Krillin| good| 75_000|Age-736-year|Male | Earthling| 153| 45|
+----------+------------+------------+------------+ + +----------+----------+
| Yamcha| weak| 1_480|Age-733-year|Male | Earthling| 183| 68|
+----------+------------+------------+------------+----------+----------+----------+----------+
# TwoDimArrayをsample2.csvファイルに保存
>>> c.save('sample2.csv', encoding='utf8')
# TwoDimArrayをsample2.csvファイルに追加保存
>>> c2.save('sample2.csv', mode='a', encoding='utf8')
ブラウザで表示する方法
#----------------------------------------------------------------------------------------------------
# TwoDimArrayの表示方法: ブラウザで表示する方法
#----------------------------------------------------------------------------------------------------
# IDLEやターミナルなどは横スクロール機能が無いため、csvの列データが多すぎると表示が折り返されて正常に表示できない
# この問題を解決するために、print関連のメソッドの出力をファイルに保存する機能が用意されている
# このファイルを横スクロールやズームなどの機能を備えたアプリケーションで開いておけば
# ファイルの更新のたびにアプリケーションの表示を更新するだけでTwoDimArrayを確認できる
#
# set_print_fileメソッドでprint関連のメソッドの出力を保存するファイルを指定する
# set_print_fileメソッドを呼び出すと設定したファイルが関連付けされたアプリケーションで開く(Windowsのみ)
# htmlファイルならブラウザが、txtファイルならエディタでファイルが開く(Windows以外は手動で開く必要がある)
# (txtファイルの場合は外部からの更新を検出できるエディタを使用するのが望ましい
# メモ帳だと外部からの更新を検出できないため閉じてから開きなおす必要がある)
#
>>> import csv_normal as csv
# sample.csvファイルからcsvデータを読み込み、TwoDimArray(二次元配列)を作成
>>> c = csv.load('sample.csv', encoding='utf8')
>>> c.header_idx = 0
>>> c.data_row_range = slice(1, None)
>>> c.set_print_file('_tmp.html', encoding='utf8') # 拡張子がhtmlなので、Windowsの場合は既定ブラウザが起動してファイルが開く
>>> c.print2() # 出力は設定したファイル(_tmp.html)に上書き保存されるのでブラウザを更新すれば新しいデータがすぐに見れる
>>>
>>> c.sort(lambda row:row[c['Sex']]) # 加工して
>>> c.print2() # ファイルに出力して、ブラウザを更新して確認
>>>
>>> c.set_print_file() # 引数無しでset_print_fileメソッドを呼べば設定が解除される
>>> c.print2()
+--------+------------+------------+------------+------+----------+----------+----------+
|Name |Strength |Buttle Power|Birthdate |Sex |Race |Height(cm)|Weight(kg)|
+--------+------------+------------+------------+------+----------+----------+----------+
|Bulma |very weak | 3|Age-733-year|Female|Earthling | 165| 49|
+--------+------------+------------+------------+------+----------+----------+----------+
|Goku |very strong | 3_000_000|Age-737-year|Male |Saiyan | 175| 62|
+--------+ +------------+------------+ + +----------+----------+
|Vegeta |very strong | 2_000_000|Age-732-year|Male |Saiyan | 164| 56|
+--------+------------+------------+------------+ +----------+----------+----------+
|Piccolo |strong | 1_000_000|Age-753-year|Male |Namekian | 226| 116|
+--------+------------+------------+------------+ +----------+----------+----------+
|Krillin |good | 75_000|Age-736-year|Male |Earthling | 153| 45|
+--------+------------+------------+------------+ + +----------+----------+
|Yamcha |weak | 1_480|Age-733-year|Male |Earthling | 183| 68|
+--------+------------+------------+------------+------+----------+----------+----------+
TwoDimArrayの基本操作
#----------------------------------------------------------------------------------------------------
# TwoDimArrayの操作方法: TwoDimArrayの基本操作
#----------------------------------------------------------------------------------------------------
>>> import csv_normal as csv
# sample.csvファイルからcsvデータを読み込み、TwoDimArray(二次元配列)を作成
>>> c = csv.load('sample.csv', encoding='utf8')
>>> c.print()
Name , Strength , Buttle Power, Birthdate , Sex , Race , Height(cm), Weight(kg)
Goku , very strong, 3_000_000, Age-737-year, Male , Saiyan , 175, 62
Vegeta , very strong, 2_000_000, Age-732-year, Male , Saiyan , 164, 56
Piccolo, strong , 1_000_000, Age-753-year, Male , Namekian , 226, 116
Bulma , very weak , 3, Age-733-year, Female, Earthling, 165, 49
Krillin, good , 75_000, Age-736-year, Male , Earthling, 153, 45
Yamcha , weak , 1_480, Age-733-year, Male , Earthling, 183, 68
# printメソッドでデータを確認しヘッダーとデータ範囲を設定する
# ヘッダーとデータ範囲を設定すると編集や集計操作が簡単にできるようになる
#
# header_idxプロパティにヘッダーのインデックスを設定する
# data_row_rangeプロパティにヘッダー&フッターを含まないデータ範囲をsliceで設定する
#
>>> c.header_idx = 0 # ヘッダーのインデックスを設定
>>> c.data_row_range = slice(1, None) # データ範囲を設定
>>>
>>> c.get_header()
['Name', 'Strength', 'Buttle Power', 'Birthdate', 'Sex', 'Race', 'Height(cm)', 'Weight(kg)']
>>> c.get_header_idx('Race')
5
>>> c.get_header_value(5)
'Race'
>>>
>>> c['Race'] # TwoDimArrayインスタンスのインデクシングからもget_header_idxメソッドを呼び出せる
5
>>>
# TwoDimArrayへの問い合わせが可能
>>> c.inquire_field_value('Goku', 'Sex') # 孫悟空の性別は?
'Male'
>>> c.inquire_field_value('Male', 'Height(cm)') # 男の身長は?
[175, 164, 226, 153, 183]
>>>
# TwoDimArrayのフィールド情報の取得、インデックスの確認が可能
>>> c.get_field_value(3, 0)
'Piccolo'
>>>
>>> c.get_field_idx('Earthling') # 行列全体から検索
(4, 5)
>>> c.get_field_idx('Earthling', slice(5, None), slice(5, 6)) # 行列範囲を絞って検索
(5, 5)
>>> c.get_field_idx_all('Earthling') # 地球人を全て検索
[(4, 5), (5, 5), (6, 5)]
>>>
>>> c('Earthling') # TwoDimArrayインスタンスのインスタンス呼び出しからもget_field_idxメソッドを呼び出せる
(4, 5)
>>>
# インデックス5の列を削除
>>> c.del_column(5)
>>> print(c)
Name , Strength , Buttle Power, Birthdate , Sex , Height(cm), Weight(kg)
Goku , very strong, 3_000_000, Age-737-year, Male , 175, 62
Vegeta , very strong, 2_000_000, Age-732-year, Male , 164, 56
Piccolo, strong , 1_000_000, Age-753-year, Male , 226, 116
Bulma , very weak , 3, Age-733-year, Female, 165, 49
↓(There are 2 rows)
# インデックス1~3の範囲内の列を削除(インデックス1と2の列を削除)
>>> c.del_column(slice(1, 3))
>>> print(c)
Name , Birthdate , Sex , Height(cm), Weight(kg)
Goku , Age-737-year, Male , 175, 62
Vegeta , Age-732-year, Male , 164, 56
Piccolo, Age-753-year, Male , 226, 116
Bulma , Age-733-year, Female, 165, 49
↓(There are 2 rows)
# インデックス1の列とインデックス2の列を入れ替える
>>> c.chg_colidx(1, 2)
>>> print(c)
Name , Sex , Birthdate , Height(cm), Weight(kg)
Goku , Male , Age-737-year, 175, 62
Vegeta , Male , Age-732-year, 164, 56
Piccolo, Male , Age-753-year, 226, 116
Bulma , Female, Age-733-year, 165, 49
↓(There are 2 rows)
# TwoDimArrayの生データはdataの中に入っているので直接編集可能
# (列操作用のメソッドは用意してあるが、基本的な行操作は簡単な配列操作で行えるので直接dataを操作する)
#
>>> c.data
[['Name', 'Sex', 'Birthdate', 'Height(cm)', 'Weight(kg)'], ['Goku', 'Male', 'Age-737-year', 175, 62], ['Vegeta', 'Male', 'Age-732-year', 164, 56], ['Piccolo', 'Male', 'Age-753-year', 226, 116], ['Bulma', 'Female', 'Age-733-year', 165, 49], ['Krillin', 'Male', 'Age-736-year', 153, 45], ['Yamcha', 'Male', 'Age-733-year', 183, 68]]
>>>
# TwoDimArrayにデータ追加(csv.str2list関数は文字列を配列に変換する)
>>> c.data.append(csv.str2list('Trunks, Male, Age-766-year, 170, 60'))
>>> c.print()
Name , Sex , Birthdate , Height(cm), Weight(kg)
Goku , Male , Age-737-year, 175, 62
Vegeta , Male , Age-732-year, 164, 56
Piccolo, Male , Age-753-year, 226, 116
Bulma , Female, Age-733-year, 165, 49
Krillin, Male , Age-736-year, 153, 45
Yamcha , Male , Age-733-year, 183, 68
Trunks , Male , Age-766-year, 170, 60
# インデックス0に列[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]を追加
>>> c.add_column(0, [i for i in range(10)])
>>> c.print()
0, Name , Sex , Birthdate , Height(cm), Weight(kg)
1, Goku , Male , Age-737-year, 175, 62
2, Vegeta , Male , Age-732-year, 164, 56
3, Piccolo, Male , Age-753-year, 226, 116
4, Bulma , Female, Age-733-year, 165, 49
5, Krillin, Male , Age-736-year, 153, 45
6, Yamcha , Male , Age-733-year, 183, 68
7, Trunks , Male , Age-766-year, 170, 60
8, , , , ,
9, , , , ,
# 身長と体重からBMI係数を算出し、TwoDimArrayの最後尾に追加
#
# cal_columnsメソッドの引数:
# 計算に必要なデータ(身長、体重)がある列の指定(4,5)、
# BMIを計算する関数(lambda h,w: int(w/(h/100)/(h/100)))、
#
>>> bmi = c.cal_columns((4,5), lambda h,w: int(w/(h/100)/(h/100)))
>>> bmi
['', 20, 20, 22, 17, 19, 20, 20, '', '']
>>> bmi[0] = 'BMI'
>>> c.add_column(None, bmi)
>>> print(c)
0, Name , Sex , Birthdate , Height(cm), Weight(kg), BMI
1, Goku , Male , Age-737-year, 175, 62, 20
2, Vegeta , Male , Age-732-year, 164, 56, 20
3, Piccolo, Male , Age-753-year, 226, 116, 22
4, Bulma , Female, Age-733-year, 165, 49, 17
↓(There are 5 rows)
# インデックス1~8の範囲内の行をBMI係数でsort
#
# c.sort(lambda row: row[c['BMI']], True)だとデータ範囲[20, 20, 22, 17, 19, 20, 20, '', '']を
# sortすることになり、数字と文字の異なるタイプのsortはできないのでエラーになる
#
# エラーを回避するために2つの方法がある
# 1. c.data_row_range=slice(1,8)として全体のデータ範囲を変更する
# 2. sortメソッドでsortする際のデータ範囲を指定(row_start_idx=1, row_end_idx=8)する
#
>>> c.sort(lambda row: row[c['BMI']], reverse=True, row_start_idx=1, row_end_idx=8) # c['BMI'] == 6
>>> c.print()
0, Name , Sex , Birthdate , Height(cm), Weight(kg), BMI
3, Piccolo, Male , Age-753-year, 226, 116, 22
1, Goku , Male , Age-737-year, 175, 62, 20
2, Vegeta , Male , Age-732-year, 164, 56, 20
6, Yamcha , Male , Age-733-year, 183, 68, 20
7, Trunks , Male , Age-766-year, 170, 60, 20
5, Krillin, Male , Age-736-year, 153, 45, 19
4, Bulma , Female, Age-733-year, 165, 49, 17
8, , , , , ,
9, , , , , ,
# フィールド値の変換(男と女を記号表記に変換)
>>> c.replace_field('Male', 'M')
>>> c.replace_field('Female', 'F')
>>> c.print()
0, Name , Sex, Birthdate , Height(cm), Weight(kg), BMI
3, Piccolo, M , Age-753-year, 226, 116, 22
1, Goku , M , Age-737-year, 175, 62, 20
2, Vegeta , M , Age-732-year, 164, 56, 20
6, Yamcha , M , Age-733-year, 183, 68, 20
7, Trunks , M , Age-766-year, 170, 60, 20
5, Krillin, M , Age-736-year, 153, 45, 19
4, Bulma , F , Age-733-year, 165, 49, 17
8, , , , , ,
9, , , , , ,
# フィールド値を正規表現で変換
>>> chg_year = c.resub_field(r'Age-(\d+)-year', r'Age \1')
>>> print(chg_year)
0, Name , Sex, Birthdate, Height(cm), Weight(kg), BMI
3, Piccolo, M , Age 753 , 226, 116, 22
1, Goku , M , Age 737 , 175, 62, 20
2, Vegeta , M , Age 732 , 164, 56, 20
6, Yamcha , M , Age 733 , 183, 68, 20
↓(There are 5 rows)
# 男だけを抽出
>>> man = chg_year.filter(lambda row: row[c['Sex']]=='M') # c['Sex'] == 2
>>> man.print()
0, Name , Sex, Birthdate, Height(cm), Weight(kg), BMI
3, Piccolo, M , Age 753 , 226, 116, 22
1, Goku , M , Age 737 , 175, 62, 20
2, Vegeta , M , Age 732 , 164, 56, 20
6, Yamcha , M , Age 733 , 183, 68, 20
7, Trunks , M , Age 766 , 170, 60, 20
5, Krillin, M , Age 736 , 153, 45, 19
# インデックス0の列を列['No.', 0, 1, 2, 3, 4, 5, 6, 7, 8, 9]に置き換える
>>> man.chg_column(0, ['No.', *[i for i in range(1, 10)]])
>>> man.print()
No., Name , Sex, Birthdate, Height(cm), Weight(kg), BMI
1, Piccolo, M , Age 753 , 226, 116, 22
2, Goku , M , Age 737 , 175, 62, 20
3, Vegeta , M , Age 732 , 164, 56, 20
4, Yamcha , M , Age 733 , 183, 68, 20
5, Trunks , M , Age 766 , 170, 60, 20
6, Krillin, M , Age 736 , 153, 45, 19
7, , , , , ,
8, , , , , ,
9, , , , , ,
# インデックス2~4の範囲内の列を取り出す
>>> sex_birthdate = man.remove_column(slice(2,4))
>>> sex_birthdate
[['Sex', 'M', 'M', 'M', 'M', 'M', 'M', '', '', ''], ['Birthdate', 'Age 753', 'Age 737', 'Age 732', 'Age 733', 'Age 766', 'Age 736', '', '', '']]
>>>
>>> print(man)
No., Name , Height(cm), Weight(kg), BMI
1, Piccolo, 226, 116, 22
2, Goku , 175, 62, 20
3, Vegeta , 164, 56, 20
4, Yamcha , 183, 68, 20
↓(There are 5 rows)
# 取り出した列をTwoDimArrayの最後尾に追加
>>> man.extend_columns(None, sex_birthdate)
>>> man.print()
No., Name , Height(cm), Weight(kg), BMI, Sex, Birthdate
1, Piccolo, 226, 116, 22, M , Age 753
2, Goku , 175, 62, 20, M , Age 737
3, Vegeta , 164, 56, 20, M , Age 732
4, Yamcha , 183, 68, 20, M , Age 733
5, Trunks , 170, 60, 20, M , Age 766
6, Krillin, 153, 45, 19, M , Age 736
7, , , , , ,
8, , , , , ,
9, , , , , ,
fill, map_field, research_field, tda2list, counter_column, arrange_rows, arrange_columnsメソッドの説明
#----------------------------------------------------------------------------------------------------
# TwoDimArrayの操作方法: fill, map_field, research_field, tda2list, counter_column, arrange_rows, arrange_columnsメソッドの説明
#----------------------------------------------------------------------------------------------------
# 2次元配列からTwoDimArray作成
>>> import csv_normal as csv
>>> m = csv.TwoDimArray([[1],[1,2],[1,2,3],[1,2,3,4],[1,2,3],[1,2],[1]])
>>> m.print()
1
1, 2
1, 2, 3
1, 2, 3, 4
1, 2, 3
1, 2
1
# 行列の欠けている箇所をゼロで埋める
>>> m.fill(0)
>>> m.print()
1, 0, 0, 0
1, 2, 0, 0
1, 2, 3, 0
1, 2, 3, 4
1, 2, 3, 0
1, 2, 0, 0
1, 0, 0, 0
# インデックス2~5の範囲内の行のフィールド値を2倍にする
>>> m2 = m.map_field(lambda field: field*2, 2, 5)
>>> m2.print()
1, 0, 0, 0
1, 2, 0, 0
2, 4, 6, 0
2, 4, 6, 8
2, 4, 6, 0
1, 2, 0, 0
1, 0, 0, 0
# 2, 4, 6で構成されたフィールドだけを抽出する
>>> m3 = m2.research_field(r'[246]')
>>> m3.print()
, , ,
, 2, ,
2, 4, 6,
2, 4, 6,
2, 4, 6,
, 2, ,
, , ,
# 4列のデータを6列に変更する
>>> m4 = csv.list2tda(m2.tda2list(), 6)
>>> m4.print()
1, 0, 0, 0, 1, 2
0, 0, 2, 4, 6, 0
2, 4, 6, 8, 2, 4
6, 0, 1, 2, 0, 0
1, 0, 0, 0
# インデックス0の列のフィールド値をカウント
>>> m4.counter_column(0)
Counter({1: 2, 0: 1, 2: 1, 6: 1})
# 列のインデックスを指定してTwoDimArrayを再構築できる
>>> m2 = m2.arrange_columns(3, 2, 1, 0)
>>> m2.print()
0, 0, 0, 1
0, 0, 2, 1
0, 6, 4, 2
8, 6, 4, 2
0, 6, 4, 2
0, 0, 2, 1
0, 0, 0, 1
# 行のインデックスを指定してTwoDimArrayを再構築できる
>>> m2 = m2.arrange_rows(0, 2, 4, 6)
>>> m2.print()
0, 0, 0, 1
0, 6, 4, 2
0, 6, 4, 2
0, 0, 0, 1
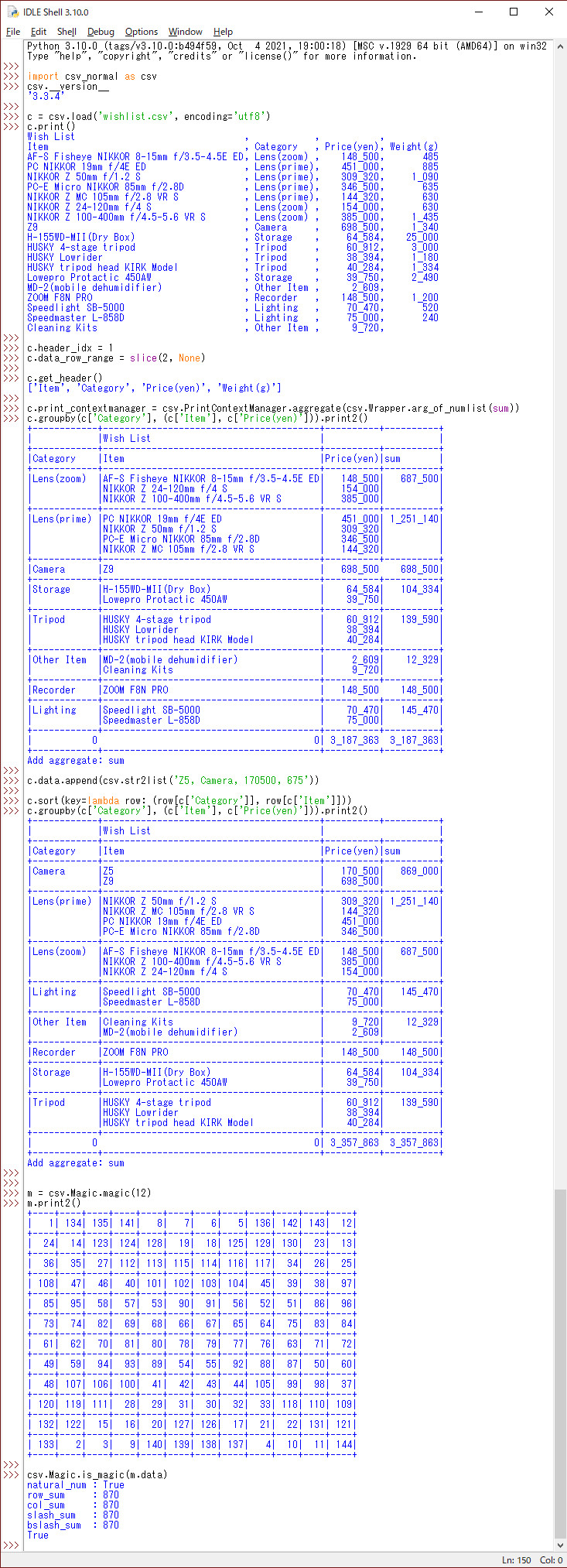
集計: TwoDimArrayの集計操作(groupby, cross_count, describe)
#----------------------------------------------------------------------------------------------------
# TwoDimArrayの操作方法: 集計: TwoDimArrayの集計操作
#----------------------------------------------------------------------------------------------------
>>> import csv_normal as csv
# sample.csvファイルからcsvデータを読み込み、TwoDimArray(二次元配列)を作成
>>> c = csv.load('sample.csv', encoding='utf8')
>>> c.print2()
+--------+------------+------------+------------+------+----------+----------+----------+
|Name |Strength |Buttle Power|Birthdate |Sex |Race |Height(cm)|Weight(kg)|
+--------+------------+------------+------------+------+----------+----------+----------+
|Goku |very strong | 3_000_000|Age-737-year|Male |Saiyan | 175| 62|
+--------+ +------------+------------+ + +----------+----------+
|Vegeta |very strong | 2_000_000|Age-732-year|Male |Saiyan | 164| 56|
+--------+------------+------------+------------+ +----------+----------+----------+
|Piccolo |strong | 1_000_000|Age-753-year|Male |Namekian | 226| 116|
+--------+------------+------------+------------+------+----------+----------+----------+
|Bulma |very weak | 3|Age-733-year|Female|Earthling | 165| 49|
+--------+------------+------------+------------+------+ +----------+----------+
|Krillin |good | 75_000|Age-736-year|Male |Earthling | 153| 45|
+--------+------------+------------+------------+ + +----------+----------+
|Yamcha |weak | 1_480|Age-733-year|Male |Earthling | 183| 68|
+--------+------------+------------+------------+------+----------+----------+----------+
# ヘッダーのインデックスとデータ範囲を設定
>>> c.header_idx = 0
>>> c.data_row_range = slice(1, None)
# 性別でグループ化して各グループの合計値を集計(sum関数で集計できないフィールド値は空になる)
>>> c.groupby(c['Sex'], func=sum).print2()
+------+----+--------+------------+----------+----+----------+----------+
|Sex |Name|Strength|Buttle Power|Birthdate |Race|Height(cm)|Weight(kg)|
+------+----+--------+------------+----------+----+----------+----------+
|Male | | 6_076_480| | 901| 347|
+------+ + +------------+ + +----------+----------+
|Female| | 3| | 165| 49|
+------+----+--------+------------+----------+----+----------+----------+
# 集計対象を身長だけに限定
>>> c.groupby(c['Sex'], c['Height(cm)'], func=sum).print2()
+------+----------+
|Sex |Height(cm)|
+------+----------+
|Male | 901|
+------+----------+
|Female| 165|
+------+----------+
# 性別と種族でグループ化し、集計対象は身長だけに限定
>>> c.groupby((c['Sex'], c['Race']), c['Height(cm)'], func=sum).print2()
+------+----------+----------+
|Sex |Race |Height(cm)|
+------+----------+----------+
|Male |Saiyan | 339|
+ +----------+----------+
|Male |Namekian | 226|
+------+----------+----------+
|Female|Earthling | 165|
+------+ +----------+
|Male |Earthling | 336|
+------+----------+----------+
# 男女別の身長と体重の平均値
>>> c.groupby(c['Sex'], (c['Height(cm)'], c['Weight(kg)']), func=csv.mean).print2()
+------+----------+----------+
|Sex |Height(cm)|Weight(kg)|
+------+----------+----------+
|Male | 180.20| 69.40|
+------+----------+----------+
|Female| 165| 49|
+------+----------+----------+
# 同じ誕生日の人はいるのかな?
>>> c.groupby(c['Birthdate'], c['Name'], func=len).print2()
+------------+----+
|Birthdate |Name|
+------------+----+
|Age-737-year| 1|
+------------+ +
|Age-732-year| 1|
+------------+ +
|Age-753-year| 1|
+------------+----+
|Age-733-year| 2|
+------------+----+
|Age-736-year| 1|
+------------+----+
# 誰と誰が同じ誕生日なのかな?
#
# func引数のデフォルト値はlambda fields: r'\n'.join(map(str, fields))となっているので
# グループ化したフィールド値を並べるだけならば省略可能
#
>>> c.groupby(c['Birthdate'], c['Name']).print2()
+------------+--------+
|Birthdate |Name |
+------------+--------+
|Age-737-year|Goku |
+------------+--------+
|Age-732-year|Vegeta |
+------------+--------+
|Age-753-year|Piccolo |
+------------+--------+
|Age-733-year|Bulma |
| |Yamcha |
+------------+--------+
|Age-736-year|Krillin |
+------------+--------+
>>>
>>> c.groupby(c['Sex']).print2()
+------+--------+------------+------------+------------+----------+----------+----------+
|Sex |Name |Strength |Buttle Power|Birthdate |Race |Height(cm)|Weight(kg)|
+------+--------+------------+------------+------------+----------+----------+----------+
|Male |Goku |very strong | 3_000_000|Age-737-year|Saiyan | 175| 62|
| |Vegeta |very strong | 2_000_000|Age-732-year|Saiyan | 164| 56|
| |Piccolo |strong | 1_000_000|Age-753-year|Namekian | 226| 116|
| |Krillin |good | 75_000|Age-736-year|Earthling | 153| 45|
| |Yamcha |weak | 1_480|Age-733-year|Earthling | 183| 68|
+------+--------+------------+------------+------------+----------+----------+----------+
|Female|Bulma |very weak | 3|Age-733-year|Earthling | 165| 49|
+------+--------+------------+------------+------------+----------+----------+----------+
# 性別と種族でクロス集計
>>> c.cross_count(c['Race'], c['Sex']).print2()
+------+----------+--------+--------+
| |Earthling |Namekian|Saiyan |
+------+----------+--------+--------+
|Female|1 (17%) |0 (0%) 0 (0%) |
+------+----------+--------+--------+
|Male |2 (33%) |1 (17%) |2 (33%) |
+------+----------+--------+--------+
# field_fmt引数でフィールドの表示形式を設定できる
>>> c.cross_count(c['Race'], c['Sex'], field_fmt='{count}').print2()
+------+----------+--------+------+
| |Earthling |Namekian|Saiyan|
+------+----------+--------+------+
|Female| 1| 0 0|
+------+----------+--------+------+
|Male | 2| 1| 2|
+------+----------+--------+------+
# 各列のデータ数、最大値、最小値、合計、平均、中央値、分散、標準偏差などを一度に確認できる
#
# 数字データのみが計算対象となり文字列は無視されるので、
# 文字列データだけで構成された列の計算結果は空白やゼロになる
#
>>> c.describe().print2()
+--------+----+--------+--------------------+----------+----+----+----------+----------+
| |Name|Strength|Buttle Power |Birthdate |Sex |Race|Height(cm)|Weight(kg)|
+--------+----+--------+--------------------+----------+----+----+----------+----------+
|len | 0 0| 6| 0 0 0| 6 6|
+--------+----+--------+--------------------+----------+----+----+----------+----------+
|max | | 3_000_000| | 226| 116|
+--------+ + +--------------------+ + + +----------+----------+
|min | | 3| | 153| 45|
+--------+----+--------+--------------------+----------+----+----+----------+----------+
|sum | 0 0| 6_076_483| 0 0 0| 1_066| 396|
+--------+----+--------+--------------------+----------+----+----+----------+----------+
|mean | | 1_012_747.17| | 177.67| 66|
+--------+ + +--------------------+ + + +----------+----------+
|median | | 537_500.00| | 170.00| 59.00|
+--------+ + +--------------------+ + + +----------+----------+
|variance| |1_570_337_249_772.17| | 665.47| 670|
+--------+ + +--------------------+ + + +----------+----------+
|stdev | | 1_253_130.98| | 25.80| 25.88|
+--------+----+--------+--------------------+----------+----+----+----------+----------+
# グループ化したデータ(multiple-lines)の処理も可能
#
# cal_columnsやmap_fieldメソッドなどはmultiple-linesの処理をサポートしている
#
>>> g = c.groupby(c['Sex'])
>>> g.print2()
+------+--------+------------+------------+------------+----------+----------+----------+
|Sex |Name |Strength |Buttle Power|Birthdate |Race |Height(cm)|Weight(kg)|
+------+--------+------------+------------+------------+----------+----------+----------+
|Male |Goku |very strong | 3_000_000|Age-737-year|Saiyan | 175| 62|
| |Vegeta |very strong | 2_000_000|Age-732-year|Saiyan | 164| 56|
| |Piccolo |strong | 1_000_000|Age-753-year|Namekian | 226| 116|
| |Krillin |good | 75_000|Age-736-year|Earthling | 153| 45|
| |Yamcha |weak | 1_480|Age-733-year|Earthling | 183| 68|
+------+--------+------------+------------+------------+----------+----------+----------+
|Female|Bulma |very weak | 3|Age-733-year|Earthling | 165| 49|
+------+--------+------------+------------+------------+----------+----------+----------+
>>>
>>> bmi = g.cal_columns((c['Height(cm)'], c['Weight(kg)']), lambda h,w: int(w/(h/100)/(h/100)))
>>> bmi
['', '20\\n20\\n22\\n19\\n20', 17]
>>> bmi[0] = 'BMI'
>>> g.add_column(None, bmi)
>>> g.print2()
+------+--------+------------+------------+------------+----------+----------+----------+----+
|Sex |Name |Strength |Buttle Power|Birthdate |Race |Height(cm)|Weight(kg)|BMI |
+------+--------+------------+------------+------------+----------+----------+----------+----+
|Male |Goku |very strong | 3_000_000|Age-737-year|Saiyan | 175| 62| 20|
| |Vegeta |very strong | 2_000_000|Age-732-year|Saiyan | 164| 56| 20|
| |Piccolo |strong | 1_000_000|Age-753-year|Namekian | 226| 116| 22|
| |Krillin |good | 75_000|Age-736-year|Earthling | 153| 45| 19|
| |Yamcha |weak | 1_480|Age-733-year|Earthling | 183| 68| 20|
+------+--------+------------+------------+------------+----------+----------+----------+----+
|Female|Bulma |very weak | 3|Age-733-year|Earthling | 165| 49| 17|
+------+--------+------------+------------+------------+----------+----------+----------+----+
集計: print処理に集計処理を追加する方法(前後処理追加方法)
#----------------------------------------------------------------------------------------------------
# TwoDimArrayの操作方法: 集計: print処理に集計処理を追加する方法(前後処理追加方法)
#----------------------------------------------------------------------------------------------------
# print_contextmanagerプロパティにcontextmanager用の関数を設定することで前後処理を簡単に追加できる
>>> import csv_normal as csv
>>> n = csv.TwoDimArray([[i for i in range(1,j)] for j in range(2,7)])
>>> n.fill(0)
>>> n.print2()
+--+--+--+--+--+
| 1| 0 0 0 0|
+ +--+ + + +
| 1| 2| 0 0 0|
+ + +--+ + +
| 1| 2| 3| 0 0|
+ + + +--+ +
| 1| 2| 3| 4| 0|
+ + + + +--+
| 1| 2| 3| 4| 5|
+--+--+--+--+--+
>>>
>>> def hoge(tda_self): # TwoDimArrayインスタンスを受け取る関数を定義する
print('START')
yield
print('END')
>>> n.print_contextmanager = hoge
>>> n.print2()
START
+--+--+--+--+--+
| 1| 0 0 0 0|
+ +--+ + + +
| 1| 2| 0 0 0|
+ + +--+ + +
| 1| 2| 3| 0 0|
+ + + +--+ +
| 1| 2| 3| 4| 0|
+ + + + +--+
| 1| 2| 3| 4| 5|
+--+--+--+--+--+
END
>>>
# print_contextmanagerプロパティに設定する関数はcsv.PrintContextManagerクラスに幾つか用意されている
>>> n.print_contextmanager = csv.PrintContextManager.aggregate(sum) # 各行列の合計値を追加表示する
>>> n.print2()
+--+--+--+--+--+--+
| 1| 0 0 0 0| 1|
+ +--+ + + +--+
| 1| 2| 0 0 0| 3|
+ + +--+ + +--+
| 1| 2| 3| 0 0| 6|
+ + + +--+ +--+
| 1| 2| 3| 4| 0|10|
+ + + + +--+--+
| 1| 2| 3| 4| 5|15|
+--+--+--+--+ +--+
| 5| 8| 9| 8| 5|35|
+--+--+--+--+--+--+
Add aggregate: sum
>>> n.data
[[1, 0, 0, 0, 0], [1, 2, 0, 0, 0], [1, 2, 3, 0, 0], [1, 2, 3, 4, 0], [1, 2, 3, 4, 5]] # データは元のまま
>>>
# 各列の合計値を追加表示する
>>> n.print_contextmanager = csv.PrintContextManager.aggregate_col(sum)
>>> n.print2()
+--+--+--+--+--+
| 1| 0 0 0 0|
+ +--+ + + +
| 1| 2| 0 0 0|
+ + +--+ + +
| 1| 2| 3| 0 0|
+ + + +--+ +
| 1| 2| 3| 4| 0|
+ + + + +--+
| 1| 2| 3| 4| 5|
+--+--+--+--+ +
| 5| 8| 9| 8| 5|
+--+--+--+--+--+
Add aggregate_col: sum
>>> n.data
[[1, 0, 0, 0, 0], [1, 2, 0, 0, 0], [1, 2, 3, 0, 0], [1, 2, 3, 4, 0], [1, 2, 3, 4, 5]] # データは元のまま
>>>
>>> n.data_row_range = slice(1, -1) # データ範囲を変更(最初と最後の行は無視される)
>>> n.print2()
+--+--+--+--+--+
| 1| 0 0 0 0|
+ +--+ + + +
| 1| 2| 0 0 0|
+ + +--+ + +
| 1| 2| 3| 0 0|
+ + + +--+ +
| 1| 2| 3| 4| 0|
+ + + + +--+
| 1| 2| 3| 4| 5|
+--+--+--+ +--+
| 3| 6 6| 4| 0|
+--+--+--+--+--+
Add aggregate_col: sum
>>>
>>> n.print_contextmanager = None # Noneで無効化
>>> n.print2()
+--+--+--+--+--+
| 1| 0 0 0 0|
+ +--+ + + +
| 1| 2| 0 0 0|
+ + +--+ + +
| 1| 2| 3| 0 0|
+ + + +--+ +
| 1| 2| 3| 4| 0|
+ + + + +--+
| 1| 2| 3| 4| 5|
+--+--+--+--+--+
集計: print処理に集計処理を追加する方法(欠損データがある場合)
#----------------------------------------------------------------------------------------------------
# TwoDimArrayの操作方法: print処理に集計処理を追加する方法(欠損データがある場合)
#----------------------------------------------------------------------------------------------------
# データ内にブランク行があったり、一部のデータが欠けている場合は集計の邪魔になるためデータを整える必要があった
# この問題を解決するために集計関数を「目的のデータだけ受け取るラッパー関数にする」機能が用意されている
#
>>> import csv_normal as csv
>>> n = csv.TwoDimArray([[i for i in range(1,j)] for j in range(2,7)])
>>> n.fill()
>>> n.print2() # 欠損データ(空フィールド)がある
+--+--+--+--+--+
| 1| |
+ +--+ + + +
| 1| 2| |
+ + +--+ + +
| 1| 2| 3| |
+ + + +--+ +
| 1| 2| 3| 4| |
+ + + + +--+
| 1| 2| 3| 4| 5|
+--+--+--+--+--+
>>>
>>> n.print_contextmanager = csv.PrintContextManager.aggregate(sum)
>>> n.print2() # 合計値を集計できるのは欠損データが無い行列だけ
+--+--+--+--+--+--+
| 1| |
+ +--+ + + + +
| 1| 2| |
+ + +--+ + + +
| 1| 2| 3| |
+ + + +--+ + +
| 1| 2| 3| 4| |
+ + + + +--+--+
| 1| 2| 3| 4| 5|15|
+--+--+--+--+--+--+
| 5| |
+--+--+--+--+--+--+
Add aggregate: sum
# csv.Wrapper.arg_of_numlistで集計関数sumをラップして数字だけが渡るようにする
>>> sum_nums = csv.Wrapper.arg_of_numlist(sum)
>>> n.print_contextmanager = csv.PrintContextManager.aggregate(sum_nums)
>>> n.print2() # 空データが無視されて各行列の合計値を集計できる
+--+--+--+--+--+--+
| 1| | 1|
+ +--+ + + +--+
| 1| 2| | 3|
+ + +--+ + +--+
| 1| 2| 3| | 6|
+ + + +--+ +--+
| 1| 2| 3| 4| |10|
+ + + + +--+--+
| 1| 2| 3| 4| 5|15|
+--+--+--+--+ +--+
| 5| 8| 9| 8| 5|35|
+--+--+--+--+--+--+
Add aggregate: sum
multiple-linesの表示切替
#----------------------------------------------------------------------------------------------------
# TwoDimArrayの操作方法: multiple-linesの表示切替
#----------------------------------------------------------------------------------------------------
# multiple-linesのデリミタはr'\n' == '\\n'
# multiple_lines_delimiterプロパティで変更可能
#
>>> import csv_normal as csv
>>> z = csv.csv2tda("""
Name, Born, Occupation
Graham\\nArthur\\nChapman, 1941, Comedian\\nwriter\\nactor
John\\nMarwood\\nCleese, 1939, Actor\\nvoice actor\\ncomedian\\nscreenwriter\\nproducer
Michael\\nEdward\\nPalin, 1943, Actor\\nwriter\\ntelevision\\npresenter\\ncomedian
""")
>>>
>>> z.trim() # 空の行、空の列を削除
>>> z.header_idx = 0 # ヘッダーのインデックスを設定
>>> z.data_row_range = slice(1, None) # データ範囲を設定
>>> z.print2()
+--------+------+------------+
|Name |Born |Occupation |
+--------+------+------------+
|Graham | 1_941|Comedian |
|Arthur | |writer |
|Chapman | |actor |
+--------+------+------------+
|John | 1_939|Actor |
|Marwood | |voice actor |
|Cleese | |comedian |
| | |screenwriter|
| | |producer |
+--------+------+------------+
|Michael | 1_943|Actor |
|Edward | |writer |
|Palin | |television |
| | |presenter |
| | |comedian |
+--------+------+------------+
>>>
>>> z.print_idx2()
index:0 :1 :2 :index
......+--------+------+------------+......
0|Name |Born |Occupation |0
......+--------+------+------------+......
1|Graham | 1_941|Comedian |1
|Arthur | |writer |
|Chapman | |actor |
......+--------+------+------------+......
2|John | 1_939|Actor |2
|Marwood | |voice actor |
|Cleese | |comedian |
| | |screenwriter|
| | |producer |
......+--------+------+------------+......
3|Michael | 1_943|Actor |3
|Edward | |writer |
|Palin | |television |
| | |presenter |
| | |comedian |
......+--------+------+------------+......
index:0 :1 :2 :index
>>>
>>> z.multiple_lines = False # multiple_linesプロパティでmultiple-lines表示を切り替えられる
>>> z.print2()
+------------------------+------+----------------------------------------------------+
|Name |Born |Occupation |
+------------------------+------+----------------------------------------------------+
|Graham\nArthur\nChapman | 1_941|Comedian\nwriter\nactor |
+------------------------+------+----------------------------------------------------+
|John\nMarwood\nCleese | 1_939|Actor\nvoice actor\ncomedian\nscreenwriter\nproducer|
+------------------------+------+----------------------------------------------------+
|Michael\nEdward\nPalin | 1_943|Actor\nwriter\ntelevision\npresenter\ncomedian |
+------------------------+------+----------------------------------------------------+
TwoDimArrayの回転
#----------------------------------------------------------------------------------------------------
# TwoDimArrayの操作方法: TwoDimArrayの回転
#----------------------------------------------------------------------------------------------------
# TwoDimArrayを左右に45度、90度毎に回転させるメソッドが用意されている
# rotate_l45, rotate_r45, rotate_l90, rotate_r90
#
>>> import csv_normal as csv
>>> r = csv.TwoDimArray([[1,2,3], [4,5,6], [7,8,9]])
>>> r.border_grouping = False
>>> r.print2()
+--+--+--+
| 1| 2| 3|
+--+--+--+
| 4| 5| 6|
+--+--+--+
| 7| 8| 9|
+--+--+--+
>>>
>>> r.rotate_r45(); r.print2()
+--+--+--+--+--+
| | | 1| | |
+--+--+--+--+--+
| | 4| | 2| |
+--+--+--+--+--+
| 7| | 5| | 3|
+--+--+--+--+--+
| | 8| | 6| |
+--+--+--+--+--+
| | | 9| | |
+--+--+--+--+--+
>>> r.rotate_r45(); r.print2()
+--+--+--+
| 7| 4| 1|
+--+--+--+
| 8| 5| 2|
+--+--+--+
| 9| 6| 3|
+--+--+--+
魔方陣の作成
#----------------------------------------------------------------------------------------------------
# その他: 魔方陣の作成
#----------------------------------------------------------------------------------------------------
# 任意のサイズの魔方陣を作成できる
# 作成した魔方陣はis_magicメソッドで縦・横・対角線の数字の合計を確認できる
#
>>> import csv_normal as csv
>>>m = csv.Magic.magic(10)
>>>m.print2()
+--+--+--+--+--+--+--+--+--+----+
| 1|92|93| 7| 6| 5|94|98|99| 10|
+--+--+--+--+--+--+--+--+--+----+
|20|12|83|84|16|85|87|88|19| 11|
+--+--+--+--+--+--+--+--+--+----+
|30|29|23|74|75|76|77|28|22| 71|
+--+--+--+--+--+--+--+--+--+----+
|61|39|38|34|65|66|37|33|62| 70|
+--+--+--+--+--+--+--+--+--+----+
|51|52|48|47|45|46|44|53|59| 60|
+--+--+--+--+--+--+--+--+--+----+
|41|49|58|57|55|56|54|43|42| 50|
+--+--+--+--+--+--+--+--+--+----+
|40|69|68|64|35|36|67|63|32| 31|
+--+--+--+--+--+--+--+--+--+----+
|80|79|73|24|26|25|27|78|72| 21|
+--+--+--+--+--+--+--+--+--+----+
|90|82|13|17|86|15|14|18|89| 81|
+--+--+--+--+--+--+--+--+--+----+
|91| 2| 8|97|96|95| 4| 3| 9| 100|
+--+--+--+--+--+--+--+--+--+----+
# 魔方陣の確認
>>>csv.Magic.is_magic(m.data)
natural_num : True
row_sum : 505
col_sum : 505
slash_sum : 505
bslash_sum : 505
True