We read every piece of feedback, and take your input very seriously.
To see all available qualifiers, see our documentation.
Have a question about this project? Sign up for a free GitHub account to open an issue and contact its maintainers and the community.
By clicking “Sign up for GitHub”, you agree to our terms of service and privacy statement. We’ll occasionally send you account related emails.
Already on GitHub? Sign in to your account
其主要核⼼流程分为编译和执⾏两步。⾸先需要将JavaScript代码转换为低级中间代码或者机器能够理解的 机器代码,然后再执⾏转换后的代码并输出执⾏结果。
解释执⾏,需要先将输⼊的源代码通过解析器编译成中间代码,之后直接使⽤解释器解释执⾏中间 代码,然后直接输出结果。具体流程如下图所⽰:
编译执⾏。采⽤这种⽅式时,也需要先将源代码转换为中间代码,然后我们的编译器再将中间代码 编译成机器代码。通常编译成的机器代码是以⼆进制⽂件形式存储的,需要执⾏这段程序的时候直接执⾏⼆ 进制⽂件就可以了。还可以使⽤虚拟机将编译后的机器代码保存在内存中,然后直接执⾏内存中的⼆进制代 码。
实际上,V8并没有采⽤某种单⼀的技术,⽽是混合编译执⾏和解释执⾏这两种⼿段,我们把这种混合使⽤ 编译器和解释器的技术称为JIT(Just?In?Time)技术。这是⼀种权衡策略,因为这两种⽅法都各⾃有⾃的优缺点,解释执⾏的启动速度快,但是执⾏时的速度慢, ⽽编译执⾏的启动速度慢,但是执⾏时的速度快。你可以参看下⾯完整的V8执⾏JavaScript的流程图:
相信你注意到了,我们在解释器附近画了个监控机器⼈,这是⼀个监控解释器执⾏状态的模块,在解释执⾏ 字节码的过程中,如果发现了某⼀段代码会被重复多次执⾏,那么监控机器⼈就会将这段代码标记为热点代 码。当某段代码被标记为热点代码后,V8就会将这段字节码丢给优化编译器,优化编译器会在后台将字节码编 译为⼆进制代码,然后再对编译后的⼆进制代码执⾏优化操作,优化后的⼆进制机器代码的执⾏效率会得到 ⼤幅提升。如果下⾯再执⾏到这段代码时,那么V8会优先选择优化之后的⼆进制代码,这样代码的执⾏速 度就会⼤幅提升。
理解了这⼀点,我们就可以来深⼊分析V8执⾏⼀段JavaScript代码所经历的主要流程了,这包括了:
初始化基础环境;
解析源码⽣成AST和作⽤域;
依据AST和作⽤域⽣成字节码;
解释执⾏字节码;
监听热点代码;
优化热点代码为⼆进制的机器代码;
反优化⽣成的⼆进制机器代码
不是的,js是基于对象设计的,但不是面向对象的语言
⾯向对象语⾔是由语⾔本⾝对继承做了充分的⽀持,并提供了⼤量的关键字,如public、protected、friend、interface等,众多的关键字使得⾯向对象语⾔的继承变得异常繁琐和复杂,「⽽JavaScript中实现继承的⽅式却⾮常简单清爽, 只是在对象中添加了⼀个称为原型的属性,把继承的对象通过原型链接起来,就实现了继承,我们把这种继承⽅式称为基于原型链继承」
在V8内部,我们会为函数对象添加了两个隐藏属性,具体属性如下图所⽰:
也就是说,函数除了可以拥有常⽤类型的属性值之外,还拥有两个隐藏属性,分别是name属性和code属 性。隐藏name属性的值就是函数名称,如果某个函数没有设置函数名,如下⾯这段函数:
(function (){ var test = 1 console.log(test) })()
该函数对象的默认的name属性值就是anonymous,表⽰该函数对象没有被设置名称。另外⼀个隐藏属性是 code属性,其值表⽰函数代码,以字符串的形式存储在内存中。当执⾏到⼀个函数调⽤语句时,V8便会从 函数对象中取出code属性值,也就是函数代码,然后再解释执⾏这段函数代码
一等公民可以作为函数参数,可以作为函数返回值,也可以赋值给变量
将外部变量和和函数绑定起来的技术称为闭包
function foo(){ var number = 1 function bar(){ number++ console.log(number) } return bar } var mybar = foo() mybar()
观察上段代码可以看到,我们在foo函数中定义了⼀个新的bar函数,并且bar函数引⽤了foo函数中的变量 number,当调⽤foo函数的时候,它会返回bar函数。
function Foo() { this[100] = 'test-100' this[1] = 'test-1' this["B"] = 'bar-B' this[50] = 'test-50' this[9] = 'test-9' this[8] = 'test-8' this[3] = 'test-3' this[5] = 'test-5' this["A"] = 'bar-A' this["C"] = 'bar-C' } var bar = new Foo() for(key in bar){ console.log(`index:${key} value:${bar[key]}`) }
在上⾯这段代码中,我们利⽤构造函数Foo创建了⼀个bar对象,在构造函数中,我们给bar对象设置了很多 属性,包括了数字属性和字符串属性,然后我们枚举出来了bar对象中所有的属性,并将其⼀⼀打印出来, 下⾯就是执⾏这段代码所打印出来的结果
index:1 value:test-1 index:3 value:test-3 index:5 value:test-5 index:8 value:test-8 index:9 value:test-9 index:50 value:test-50 index:100 value:test-100 index:B value:bar-B index:A value:bar-A index:C value:bar-C
观察这段打印出来的数据,我们发现打印出来的属性顺序并不是我们设置的顺序,我们设置属性的时候是乱 序设置的,⽐如开始先设置100,然后有设置了1,但是输出的内容却⾮常规律,总的来说体现在以下两 点:
设置的数字属性被最先打印出来了,并且按照数字⼤⼩的顺序打印的;
设置的字符串属性依然是按照之前的设置顺序打印的,⽐如我们是按照B、A、C的顺序设置的,打印出来,依然是这个顺序。
之所以出现这样的结果,是因为在ECMAScript规范中定义了 「数字属性应该按照索引值⼤⼩升序排列,字符 串属性根据创建时的顺序升序排列。」在这⾥我们把对象中的数字属性称为 「排序属性」,在V8中被称为 elements,字符串属性就被称为 「常规属性」, 在V8中被称为 properties。在V8内部,为了有效地提升存储和访问这两种属性的性能,分别使⽤了两个 线性数据结构来分别保存排序 属性和常规属性,具体结构如下图所⽰:
在elements对象中,会按照顺序存放排序属性,properties属性则指向了properties对 象,在properties对象中,会按照创建时的顺序保存了常规属性。
将不同的属性分别保存到elements属性和properties属性中,⽆疑简化了程序的复杂度,但是在查找元素 时,却多了⼀步操作,⽐如执⾏?bar.B这个语句来查找B的属性值,那么在V8会先查找出properties属性所 指向的对象properties,然后再在properties对象中查找B属性,这种⽅式在查找过程中增加了⼀步操作, 因此会影响到元素的查找效率。基于这个原因,V8采取了⼀个权衡的策略以加快查找属性的效率,这个策略是将部分常规属性直接存储到 对象本⾝,我们把这称为 「对象内属性(in-object?properties)」。对象在内存中的展现形式你可以参看下图:
采⽤对象内属性之后,常规属性就被保存到bar对象本⾝了,这样当再次使⽤bar.B来查找B的属性值时, V8就可以直接从bar对象本⾝去获取该值就可以了,这种⽅式减少查找属性值的步骤,增加了查找效率。不过对象内属性的数量是固定的,默认是10个,如果添加的属性超出了对象分配的空间,则它们将被保存在 常规属性存储中。虽然属性存储多了⼀层间接层,但可以⾃由地扩容。
通常,我们将保存在线性数据结构中的属性称之为“快属性”,因为线性数据结构中只需要通过索引即可以 访问到属性,虽然访问线性结构的速度快,但是如果从线性结构中添加或者删除⼤量的属性时,则执⾏效率 会⾮常低,这主要因为会产⽣⼤量时间和内存开销。因此,如果⼀个对象的属性过多时,V8为就会采取另外⼀种存储策略,那就是“慢属性”策略,但慢属性 的对象内部会有独⽴的⾮线性数据结构(词典)作为属性存储容器。所有的属性元信息不再是线性存储的,⽽ 是直接保存在属性字典中。
同样是在定义的函数之前调⽤函数,第⼀段代码就可以正确执⾏,⽽第⼆段代码却报错,这是为什么呢?其主要原因是这两种定义函数的⽅式具有不同语义,不同的语义触发了不同的⾏为。
因为语义不同,所以我们给这两种定义函数的⽅式使⽤了不同的名称,第⼀种称之为 「函数声明」,第⼆种称之 为「函数表达式」
V8在执⾏JavaScript的过程中,会先对其进⾏编译,然后再执⾏,⽐如下⾯这段代码:
var x = 5 function foo(){ console.log('Foo') }
V8执⾏这段代码的流程⼤致如下图所⽰:
在编译阶段,如果解析到函数声明,那么V8会将这个函数声明转换为内存中的函数对象(「函数名放在栈,函数体放在堆」),并将其放到作⽤ 域中。同样,如果解析到了某个变量声明,也会将其放到作⽤域中,但是会将其值设置为undefined,表⽰ 该变量还未被使⽤。
然后在V8执⾏阶段,如果使⽤了某个变量,或者调⽤了某个函数,那么V8便会去作⽤域查找相关内容。
因为在执⾏之前,这些变量都被提升到作⽤域中了,所以在执⾏阶段,V8当然就能获取到所有的定义变量 了。我们把这种在编译阶段,将所有的变量提升到作⽤域的过程称为「变量提升」
简单地理解,表达式就是表⽰值的式⼦,⽽语句是操作值的式⼦。
⽐如:
x = 5
就是表达式,因为执⾏这段代码,它会返回⼀个值。同样,6 === 5?也是⼀个表达式,因为它会返回 False。
⽽语句则不同了,⽐如你定义了⼀个变量:
var x;
这就是⼀个语句,执⾏该语句时,V8并不会返回任何值给你。同样,当我声明了⼀个函数时,这个函数声明也是⼀个语句,⽐如下⾯这段函数声明:
function foo(){ return 1 }
当执⾏到这段代码时,V8并没有返回任何的值,它只是解析foo函数,并将函数对象存储到内存中。
「这么一来就说明了,语句的执行是 编译阶段,把变量放到作用域,导致变量提升,表达式的执行是在执行阶段,导致作用域中的变量的值的改变。」
function foo(){ console.log('Foo') }
执⾏上⾯这段代码,它并没有输出任何内容,所以可以肯定,函数声明并不是⼀个表达式,⽽是⼀个语句。
总的来说,在V8解析JavaScript源码的过程中,如果遇到普通的变量声明,那么便会将其提升到作⽤域中, 并给该变量赋值为undefined,如果遇到的是函数声明,那么V8会在内存中为声明⽣成函数对象,并将该对 象提升到作⽤域中。
我觉得最有意思的是下面这道题
JavaScript中有⼀个圆括号运算符,圆括号⾥⾯可以放⼀个表达式,⽐如下⾯的代码:
(a=3)
括号⾥⾯是⼀个表达式,整个语句也是⼀个表达式,最终输出3。如果在⼩括号⾥⾯放上⼀段函数的定义,如下所⽰:
(function () { //statements })
因为⼩括号之间存放的必须是表达式,所以如果在⼩阔号⾥⾯定义⼀个函数,那么V8就会把这个函数看成 是函数表达式,执⾏时它会返回⼀个函数对象
存放在括号⾥⾯的函数便是⼀个函数表达式,它会返回⼀个函数对象,如果我直接在表达式后⾯加上调⽤的 括号,这就称 ⽴即调⽤函数表达式(IIFE),⽐如下⾯代码:
(function () { //statements })()
因为函数⽴即表达式也是⼀个表达式,所以V8在编译阶段,并不会为该表达式创建函数对象。这样的⼀个 好处就是不会污染环境,函数和函数内部的变量都不会被其他部分的代码访问到。
var a = (function () { return 1 })()
因为函数⽴即表达式是⽴即执⾏的,所以将⼀个函数⽴即表达式赋给⼀个变量时,不是存储?IIFE?本 ⾝,⽽是存储?IIFE?执⾏后返回的结果,所以a=1。
全局作⽤域和函数作⽤域类似,也是存放变量和函数的地⽅,但是它们还是有点不⼀样:? 「全局作⽤域是在 V8启动过程中就创建了,且⼀直保存在内存中不会被销毁的,直⾄V8退出。? ⽽函数作⽤域是在执⾏该函数 时创建的,当函数执⾏结束之后,函数作⽤域就随之被销毁掉了。」
因为JavaScript是基于词法作⽤域的,词法作⽤域就是指,查找作⽤域的顺序是按照函数定义时的位置来决 定的。bar和foo函数的外部代码都是全局代码,所以⽆论你是在bar函数中查找变量,还是在foo函数中查找 变量,其查找顺序都是按照当前函数作⽤域‒>全局作⽤域这个路径来的。
由于我们代码中的foo函数和bar函数都是在全局下⾯定义的,所以在foo函数中使⽤了type,最终打印出来 的值就是全局作⽤域中的type。
因为词法作⽤域是根据函数在代码中的位置来确定的,作⽤域是在声明函数时就确 定好的了,所以我们也将词法作⽤域称为静态作⽤域。和静态作⽤域相对的是动态作⽤域,动态作⽤域并不关⼼函数和作⽤域是如何声明以及在何处声明的,只关 ⼼它们从 何处调⽤。换句话说,作⽤域链是基于调⽤栈的,⽽不是基于函数定义的位置的。
V8会提供了⼀个ToPrimitve⽅法,其作⽤是将a和b转换为原⽣数据类型,其转换流程如下:
先检测该对象中是否存在valueOf⽅法,如果有并返回了原始类型,那么就使⽤该值进⾏强制类型转换;
如果valueOf没有返回原始类型,那么就使⽤toString⽅法的返回值;
如果vauleOf和toString两个⽅法都不返回基本类型值,便会触发⼀个TypeError的错误。
将对象转换为原⽣类型的流程图如下所⽰:
当V8执⾏1+“2”时,因为这是两个原始值相加,原始值相加的时候,如果其中⼀项是字符串,那么V8会默 认将另外⼀个值也转换为字符串,相当于执⾏了下⾯的操作:
Number(1).toString() + "2"
「注意」:上面valueOf和toString的调用顺序仅适用于 运算。其他情况可以参考8. {} 和 [] 的 valueOf 和 toString 的结果是什么?.
The text was updated successfully, but these errors were encountered:
No branches or pull requests
一、V8是如何执⾏⼀段JavaScript代码的?
1.V8是怎么执⾏JavaScript代码的呢
其主要核⼼流程分为编译和执⾏两步。⾸先需要将JavaScript代码转换为低级中间代码或者机器能够理解的 机器代码,然后再执⾏转换后的代码并输出执⾏结果。
2.什么是解释执行
解释执⾏,需要先将输⼊的源代码通过解析器编译成中间代码,之后直接使⽤解释器解释执⾏中间 代码,然后直接输出结果。具体流程如下图所⽰:
3.什么是编译执行
编译执⾏。采⽤这种⽅式时,也需要先将源代码转换为中间代码,然后我们的编译器再将中间代码 编译成机器代码。通常编译成的机器代码是以⼆进制⽂件形式存储的,需要执⾏这段程序的时候直接执⾏⼆ 进制⽂件就可以了。还可以使⽤虚拟机将编译后的机器代码保存在内存中,然后直接执⾏内存中的⼆进制代 码。
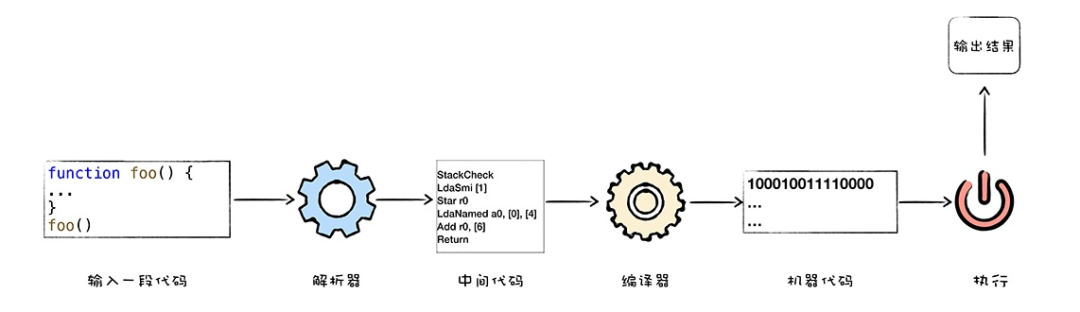
4.V8作为JavaScript的虚拟机的⼀种,?是解释执⾏,还是编译执⾏呢?
实际上,V8并没有采⽤某种单⼀的技术,⽽是混合编译执⾏和解释执⾏这两种⼿段,我们把这种混合使⽤ 编译器和解释器的技术称为JIT(Just?In?Time)技术。这是⼀种权衡策略,因为这两种⽅法都各⾃有⾃的优缺点,解释执⾏的启动速度快,但是执⾏时的速度慢, ⽽编译执⾏的启动速度慢,但是执⾏时的速度快。你可以参看下⾯完整的V8执⾏JavaScript的流程图:
相信你注意到了,我们在解释器附近画了个监控机器⼈,这是⼀个监控解释器执⾏状态的模块,在解释执⾏ 字节码的过程中,如果发现了某⼀段代码会被重复多次执⾏,那么监控机器⼈就会将这段代码标记为热点代 码。当某段代码被标记为热点代码后,V8就会将这段字节码丢给优化编译器,优化编译器会在后台将字节码编 译为⼆进制代码,然后再对编译后的⼆进制代码执⾏优化操作,优化后的⼆进制机器代码的执⾏效率会得到 ⼤幅提升。如果下⾯再执⾏到这段代码时,那么V8会优先选择优化之后的⼆进制代码,这样代码的执⾏速 度就会⼤幅提升。
理解了这⼀点,我们就可以来深⼊分析V8执⾏⼀段JavaScript代码所经历的主要流程了,这包括了:
初始化基础环境;
解析源码⽣成AST和作⽤域;
依据AST和作⽤域⽣成字节码;
解释执⾏字节码;
监听热点代码;
优化热点代码为⼆进制的机器代码;
反优化⽣成的⼆进制机器代码
二、函数即对象,函数的特点
1.js是一门面向对象的语言吗?
不是的,js是基于对象设计的,但不是面向对象的语言
2.js与面向对象语言在继承上有什么区别?
⾯向对象语⾔是由语⾔本⾝对继承做了充分的⽀持,并提供了⼤量的关键字,如public、protected、friend、interface等,众多的关键字使得⾯向对象语⾔的继承变得异常繁琐和复杂,「⽽JavaScript中实现继承的⽅式却⾮常简单清爽, 只是在对象中添加了⼀个称为原型的属性,把继承的对象通过原型链接起来,就实现了继承,我们把这种继承⽅式称为基于原型链继承」
3.V8内部是怎么实现函数可调⽤特性的呢?
在V8内部,我们会为函数对象添加了两个隐藏属性,具体属性如下图所⽰:
也就是说,函数除了可以拥有常⽤类型的属性值之外,还拥有两个隐藏属性,分别是name属性和code属 性。隐藏name属性的值就是函数名称,如果某个函数没有设置函数名,如下⾯这段函数:
该函数对象的默认的name属性值就是anonymous,表⽰该函数对象没有被设置名称。另外⼀个隐藏属性是 code属性,其值表⽰函数代码,以字符串的形式存储在内存中。当执⾏到⼀个函数调⽤语句时,V8便会从 函数对象中取出code属性值,也就是函数代码,然后再解释执⾏这段函数代码
4.function在JavaScript中是一等公民 ,何为一等公民?
一等公民可以作为函数参数,可以作为函数返回值,也可以赋值给变量
5.什么是闭包?
将外部变量和和函数绑定起来的技术称为闭包
观察上段代码可以看到,我们在foo函数中定义了⼀个新的bar函数,并且bar函数引⽤了foo函数中的变量 number,当调⽤foo函数的时候,它会返回bar函数。
三、快属性和慢属性:V8采⽤了哪些策略提升了对象属性的访问速度?
1.什么是对象中的 常规属性和 排序属性
在上⾯这段代码中,我们利⽤构造函数Foo创建了⼀个bar对象,在构造函数中,我们给bar对象设置了很多 属性,包括了数字属性和字符串属性,然后我们枚举出来了bar对象中所有的属性,并将其⼀⼀打印出来, 下⾯就是执⾏这段代码所打印出来的结果
观察这段打印出来的数据,我们发现打印出来的属性顺序并不是我们设置的顺序,我们设置属性的时候是乱 序设置的,⽐如开始先设置100,然后有设置了1,但是输出的内容却⾮常规律,总的来说体现在以下两 点:
设置的数字属性被最先打印出来了,并且按照数字⼤⼩的顺序打印的;
设置的字符串属性依然是按照之前的设置顺序打印的,⽐如我们是按照B、A、C的顺序设置的,打印出来,依然是这个顺序。
之所以出现这样的结果,是因为在ECMAScript规范中定义了 「数字属性应该按照索引值⼤⼩升序排列,字符 串属性根据创建时的顺序升序排列。」在这⾥我们把对象中的数字属性称为 「排序属性」,在V8中被称为 elements,字符串属性就被称为 「常规属性」, 在V8中被称为 properties。在V8内部,为了有效地提升存储和访问这两种属性的性能,分别使⽤了两个 线性数据结构来分别保存排序 属性和常规属性,具体结构如下图所⽰:
在elements对象中,会按照顺序存放排序属性,properties属性则指向了properties对 象,在properties对象中,会按照创建时的顺序保存了常规属性。
2.什么是对象内属性
将不同的属性分别保存到elements属性和properties属性中,⽆疑简化了程序的复杂度,但是在查找元素 时,却多了⼀步操作,⽐如执⾏?bar.B这个语句来查找B的属性值,那么在V8会先查找出properties属性所 指向的对象properties,然后再在properties对象中查找B属性,这种⽅式在查找过程中增加了⼀步操作, 因此会影响到元素的查找效率。基于这个原因,V8采取了⼀个权衡的策略以加快查找属性的效率,这个策略是将部分常规属性直接存储到 对象本⾝,我们把这称为 「对象内属性(in-object?properties)」。对象在内存中的展现形式你可以参看下图:
采⽤对象内属性之后,常规属性就被保存到bar对象本⾝了,这样当再次使⽤bar.B来查找B的属性值时, V8就可以直接从bar对象本⾝去获取该值就可以了,这种⽅式减少查找属性值的步骤,增加了查找效率。不过对象内属性的数量是固定的,默认是10个,如果添加的属性超出了对象分配的空间,则它们将被保存在 常规属性存储中。虽然属性存储多了⼀层间接层,但可以⾃由地扩容。
3.什么是快属性和慢属性
通常,我们将保存在线性数据结构中的属性称之为“快属性”,因为线性数据结构中只需要通过索引即可以 访问到属性,虽然访问线性结构的速度快,但是如果从线性结构中添加或者删除⼤量的属性时,则执⾏效率 会⾮常低,这主要因为会产⽣⼤量时间和内存开销。因此,如果⼀个对象的属性过多时,V8为就会采取另外⼀种存储策略,那就是“慢属性”策略,但慢属性 的对象内部会有独⽴的⾮线性数据结构(词典)作为属性存储容器。所有的属性元信息不再是线性存储的,⽽ 是直接保存在属性字典中。
四、函数表达式:涉及⼤量概念,函数表达式到底该怎么学?
1.函数声明与函数表达式的差异
同样是在定义的函数之前调⽤函数,第⼀段代码就可以正确执⾏,⽽第⼆段代码却报错,这是为什么呢?其主要原因是这两种定义函数的⽅式具有不同语义,不同的语义触发了不同的⾏为。
因为语义不同,所以我们给这两种定义函数的⽅式使⽤了不同的名称,第⼀种称之为 「函数声明」,第⼆种称之 为「函数表达式」
2.V8是怎么处理函数声明的?
V8在执⾏JavaScript的过程中,会先对其进⾏编译,然后再执⾏,⽐如下⾯这段代码:
V8执⾏这段代码的流程⼤致如下图所⽰:
在编译阶段,如果解析到函数声明,那么V8会将这个函数声明转换为内存中的函数对象(「函数名放在栈,函数体放在堆」),并将其放到作⽤ 域中。同样,如果解析到了某个变量声明,也会将其放到作⽤域中,但是会将其值设置为undefined,表⽰ 该变量还未被使⽤。
然后在V8执⾏阶段,如果使⽤了某个变量,或者调⽤了某个函数,那么V8便会去作⽤域查找相关内容。
3.什么是变量提升?
因为在执⾏之前,这些变量都被提升到作⽤域中了,所以在执⾏阶段,V8当然就能获取到所有的定义变量 了。我们把这种在编译阶段,将所有的变量提升到作⽤域的过程称为「变量提升」
4.表达式和语句的区别是什么
简单地理解,表达式就是表⽰值的式⼦,⽽语句是操作值的式⼦。
⽐如:
就是表达式,因为执⾏这段代码,它会返回⼀个值。同样,6 === 5?也是⼀个表达式,因为它会返回 False。
⽽语句则不同了,⽐如你定义了⼀个变量:
这就是⼀个语句,执⾏该语句时,V8并不会返回任何值给你。同样,当我声明了⼀个函数时,这个函数声明也是⼀个语句,⽐如下⾯这段函数声明:
当执⾏到这段代码时,V8并没有返回任何的值,它只是解析foo函数,并将函数对象存储到内存中。
「这么一来就说明了,语句的执行是 编译阶段,把变量放到作用域,导致变量提升,表达式的执行是在执行阶段,导致作用域中的变量的值的改变。」
5.函数声明是表达式还是语句呢?
执⾏上⾯这段代码,它并没有输出任何内容,所以可以肯定,函数声明并不是⼀个表达式,⽽是⼀个语句。
总的来说,在V8解析JavaScript源码的过程中,如果遇到普通的变量声明,那么便会将其提升到作⽤域中, 并给该变量赋值为undefined,如果遇到的是函数声明,那么V8会在内存中为声明⽣成函数对象,并将该对 象提升到作⽤域中。
我觉得最有意思的是下面这道题
6.为什么⽴即调⽤的函数表达式(IIFE)可以拥有私有作用域
JavaScript中有⼀个圆括号运算符,圆括号⾥⾯可以放⼀个表达式,⽐如下⾯的代码:
括号⾥⾯是⼀个表达式,整个语句也是⼀个表达式,最终输出3。如果在⼩括号⾥⾯放上⼀段函数的定义,如下所⽰:
因为⼩括号之间存放的必须是表达式,所以如果在⼩阔号⾥⾯定义⼀个函数,那么V8就会把这个函数看成 是函数表达式,执⾏时它会返回⼀个函数对象
存放在括号⾥⾯的函数便是⼀个函数表达式,它会返回⼀个函数对象,如果我直接在表达式后⾯加上调⽤的 括号,这就称 ⽴即调⽤函数表达式(IIFE),⽐如下⾯代码:
因为函数⽴即表达式也是⼀个表达式,所以V8在编译阶段,并不会为该表达式创建函数对象。这样的⼀个 好处就是不会污染环境,函数和函数内部的变量都不会被其他部分的代码访问到。
7. 变量a的值是什么
因为函数⽴即表达式是⽴即执⾏的,所以将⼀个函数⽴即表达式赋给⼀个变量时,不是存储?IIFE?本 ⾝,⽽是存储?IIFE?执⾏后返回的结果,所以a=1。
五、作⽤域链:V8是如何查找变量的?
1.全局作⽤域和函数作⽤域
全局作⽤域和函数作⽤域类似,也是存放变量和函数的地⽅,但是它们还是有点不⼀样:? 「全局作⽤域是在 V8启动过程中就创建了,且⼀直保存在内存中不会被销毁的,直⾄V8退出。? ⽽函数作⽤域是在执⾏该函数 时创建的,当函数执⾏结束之后,函数作⽤域就随之被销毁掉了。」
2.什么是词法作⽤域
因为JavaScript是基于词法作⽤域的,词法作⽤域就是指,查找作⽤域的顺序是按照函数定义时的位置来决 定的。bar和foo函数的外部代码都是全局代码,所以⽆论你是在bar函数中查找变量,还是在foo函数中查找 变量,其查找顺序都是按照当前函数作⽤域‒>全局作⽤域这个路径来的。
由于我们代码中的foo函数和bar函数都是在全局下⾯定义的,所以在foo函数中使⽤了type,最终打印出来 的值就是全局作⽤域中的type。
3.什么是动态作用域和静态作用域
因为词法作⽤域是根据函数在代码中的位置来确定的,作⽤域是在声明函数时就确 定好的了,所以我们也将词法作⽤域称为静态作⽤域。和静态作⽤域相对的是动态作⽤域,动态作⽤域并不关⼼函数和作⽤域是如何声明以及在何处声明的,只关 ⼼它们从 何处调⽤。换句话说,作⽤域链是基于调⽤栈的,⽽不是基于函数定义的位置的。
六.类型转换:V8是怎么实现1-“2”的?
1.V8是怎么实现1-“2”的
V8会提供了⼀个ToPrimitve⽅法,其作⽤是将a和b转换为原⽣数据类型,其转换流程如下:
先检测该对象中是否存在valueOf⽅法,如果有并返回了原始类型,那么就使⽤该值进⾏强制类型转换;
如果valueOf没有返回原始类型,那么就使⽤toString⽅法的返回值;
如果vauleOf和toString两个⽅法都不返回基本类型值,便会触发⼀个TypeError的错误。
将对象转换为原⽣类型的流程图如下所⽰:
当V8执⾏1+“2”时,因为这是两个原始值相加,原始值相加的时候,如果其中⼀项是字符串,那么V8会默 认将另外⼀个值也转换为字符串,相当于执⾏了下⾯的操作:
「注意」:上面valueOf和toString的调用顺序仅适用于 运算。其他情况可以参考8. {} 和 [] 的 valueOf 和 toString 的结果是什么?.
The text was updated successfully, but these errors were encountered: