FineGrainOCR is a multimodal dataset for grocery product recognition using image and OCR data. The dataset contains products from the following categories: dairy, chocolate, milk/cream, meat, mushroom and toppings. In the dataset, each class has one or more classes that it has a strong resemblance to.
Below are a few challenging cases where different grocery products have a similar appearance and are only differentiable by subtle details (ingredients side, meat packages), lactose and non-lactose product variant, and the same type of product with different weight.




The dataset can be downloaded from the following Dropbox link: FineGrainOCR
The image samples are RGB images with a resolution of 2592x1944. The OCR texts have the JSON format from Google Vision API. Each OCR reading is separated by "\n". An example of the JSON file can be seen below:
[
{
"locale": "fr",
"description": "ORIGINALE\nOCR_READING_2\nOCR_READING_3\n...\nOCR_READING_N\n",
"bounding_poly": {
"vertices": [
{
"x": 1510,
"y": 275
},
{
"x": 2210,
"y": 275
},
{
"x": 2210,
"y": 1396
},
{
"x": 1510,
"y": 1396
}
]
}
},
{
"description": "ORIGINALE",
"bounding_poly": {
"vertices": [
{
"x": 2130,
"y": 1390
},
{
"x": 1891,
"y": 1397
},
{
"x": 1890,
"y": 1372
},
{
"x": 2129,
"y": 1365
}
]
}
},
{
...
},
...
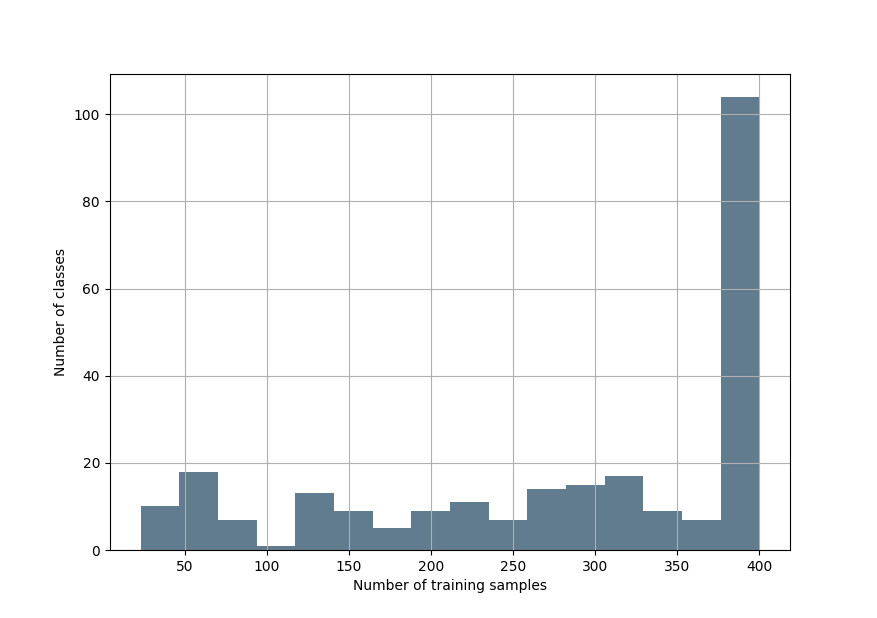
]The dataset contains a total of 256 classes with 73378 images/texts for training and 18416 images/texts for validation. The number of images/texts per class for the training set is shown in the histogram below.
Sample images and OCR texts are provided in the samples folder.
To run experiments with a subset of the training dataset in the same way as described in the paper, a new training dataset can be created using the following command:
python3 scripts/create_dataset_subset_symbolic_links.py --input-folder TRAIN_DATASET_FOLDER --output-folder TRAIN_SUBSET_DATASET_FOLDER --max-samples-class MAX_TRAIN_SAMPLES
where TRAIN_DATASET_FOLDER is the path to the training dataset, TRAIN_SUBSET_DATASET_FOLDER is the path to the
new training dataset, and MAX_TRAIN_SAMPLES is the maximum number of samples per class to be included in the new
training dataset. In the experiments, we MAX_TRAIN_SAMPLES has been set to 50, 100, 200, and 400. Symbolic links are
created to the original images/texts, so no significant storage space is required for subset of the dataset.
If you use this dataset, please cite the following paper:
@article{pettersson2024,
title = {Multimodal fine-grained grocery product recognition using image and OCR text},
author = {Pettersson, Tobias and Riveiro, Maria and L{\"o}fstr{\"o}m, Tuwe},
journal = {Machine Vision and Applications},
volume = {35},
number = {4},
pages = {79},
year = {2024},
publisher = {Springer}
}
- Email: tobias.pettersson[at]itab.com
- LinkedIn: Tobias Pettersson