{kind=link}


As of 2/14/2024 this model has been integrated into a standalone application, as outlined here
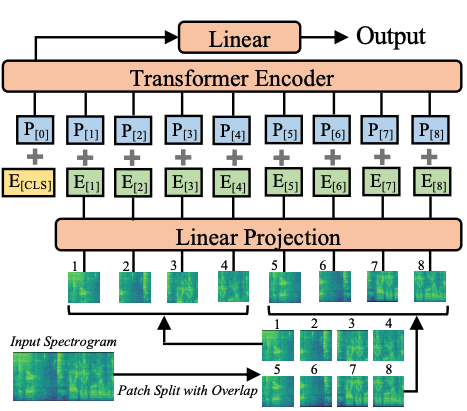
This repository contains Tyler Schwenk's fork of the official implementation (in PyTorch) of the Audio Spectrogram Transformer (AST) proposed in the Interspeech 2021 paper AST: Audio Spectrogram Transformer (Yuan Gong, Yu-An Chung, James Glass).
AST is the first convolution-free, purely attention-based model for audio classification which supports variable length input and can be applied to various tasks.
I have fine tuned the audioset-pretrained model to identify the presence of the endangered frog, Rana Draytonii, in audio files taken from the field. These files are recorded near ponds, and can include noise such as other species of frogs or animals, rain, and wind.
Despite the noise, the model is able to determine the presence of Rana Draytonii with about 98.77% accuracy, calculated as the proportion of predictions where the highest scoring label matches the key data.
The inference first handles all of the preprocessing of the data from raw .wav files into 10 second, 16kHz, mono audio segments that it uses to create spectrograms readable to the model. Beyond just determining if there are any calls heard in an audio file, my scipt will track when in the file they are heard, as well as pull information from the audio files' metadata and output the information in an Excel file as below:
The folder "Rana_Draytonii_ML_Model" contains everything needed to run the model, besides my fine tuned weights which can be downloaded here. Or simply download the entire folder, already setup here.
I recommend placing "Rana_Draytonii_ML_Model" in your google drive, as it integrates well with google colab. Then you can simply open "AST_Inference.ipynb" in google colab and follow my detailed instructions to analyze your .wav files. This mostly amounts to uploading the files to be reviewed to the apporopriate folder in "Rana_Draytonii_ML_Model", inputting a few parameters, and running the script. The script will take care of preprocessing the .wav files, running them through the AST model, and create the above excel file in less than the time it would take to listen to your audio recordings.
In this forked repository I have altered the dataloader.py, and created a new model in egs/Rana7. I have also added my preprossesing scripts (Data_Manager.ipynb) and training script (ASTtraining.ipynb) in the folder "Preprocessing". These are only for training, and so not necessary for those simply wanting to use my pretrained model for audio classification.
I created "Data_Manager.ipynb" to preform the following actions to prepare files for training:
- Takes the .wav files and splits them into 10 second segments.
- Resamples the audio files to have 16 kHz sample rate, which is ideal for most machine learning tasks and required for use with ast.
- Converts any stereo files to be mono for uniformity (most are already mono).
- Splits the files into testing, validation, and training sets (15,15,70) before creating a labels.csv and three .json files to index the files in training.
"ASTtraining.ipynb" will clone this repository, mount google drive and install dependencies, then running the training script. The training script outputs various evaluation metrics as it runs through multiple epochs, and stores the final weights in a .pth file.
Here is an example of how Rana Draytonii sounds on its own. You can hear the deep grunting sound of it's call.
Here is an example of Rana Draytonii's calls among other noise, including the chorus frog. This model will still be able to identify Rana Draytonii through the noise, and similarly would not positively ID when only the chorus frog is present.
Here is an example of audio that would get negatively identified by my model.
- Cut off the unused frequencies from files that record frequencies well out of the range where this species vocalizes
- Also train model to listen for other species, such as bullfrogs which prey on Rana Draytonii. This would only require the labelled training data of the species, all other scripts can remain the same besides a few small tweaks.
- Include more data like where the files were recorded and provide more information like graphs of calls over time or a map.
The first paper proposes the Audio Spectrogram Transformer while the second paper describes the training pipeline that they applied on AST to achieve the new state-of-the-art on AudioSet.
@inproceedings{gong21b_interspeech,
author={Yuan Gong and Yu-An Chung and James Glass},
title={{AST: Audio Spectrogram Transformer}},
year=2021,
booktitle={Proc. Interspeech 2021},
pages={571--575},
doi={10.21437/Interspeech.2021-698}
}
@ARTICLE{gong_psla,
author={Gong, Yuan and Chung, Yu-An and Glass, James},
journal={IEEE/ACM Transactions on Audio, Speech, and Language Processing},
title={PSLA: Improving Audio Tagging with Pretraining, Sampling, Labeling, and Aggregation},
year={2021},
doi={10.1109/TASLP.2021.3120633}
}
If you have a question, would like to develop something similar for another species, or just want to share how you have used this, send me an email at tylerschwenk1@yahoo.com.