Forge を高速な安定版として利用する
Forge の更新が落ち着いてから しばらく経ちます が、更新が無いことは寂しく有りつつも、更新で環境が壊れない安定版として利用することもできます。
環境更新が億劫で旧バージョンを利用しがちな方に向けて、現在の Forge を高速な安定版として利用する方法をまとめておきます。
個人的な利用方法ですので、合う合わないは各自でご判断ください。
Animagine 系でも Pony 系でも Hyper-SD の 8ステップ版 <lora:Hyper-SDXL-8steps-lora:1> を CFGスケール: 1.0 で利用しています。
CFGスケール が 1.0 だと大幅に高速化されることを利用していますので、常に 1.0 で固定したまま利用します。
CFGスケール が 1.0 では ネガティブプロンプト の影響がなくなりますので、空欄のままで問題ありません(調整項目が減ります)。
何かを否定したい場合は NegPip によるマイナスの重み付け (prompt: -1.0) 表記を利用します。
-
サンプリングステップ数はモデルに合わせて10~30あたりでお好みに設定します。- 1ステップの処理速度が上がっていますので、ステップ数を増やしても処理時間への影響は軽微です。
-
サンプリング方法はEuler A SGMUniformが安定ですが、モデル相性とお好みで変更しても問題ありません。
Forge でふたつのモデルを利用する際などに、環境によって torch.cuda.OutOfMemoryError: CUDA out of memory. のエラーが発生する場合があります。
-
<lora:Hyper-SDXL-8steps-lora:1:stop=5>などで LoRA の利用有無を切り替える。 -
高解像度補助、Refiner、ADetailerで利用モデルを切り替える。
このような場合には、画面の左下にある Forge 組み込み機能の Never OOM Integrated で回避します。

-
Enabled for UNet: ふたつのモデルに起因する OOM を回避できます。 -
Enabled for VAE: 画像生成の最後のタイミングで発生する OOM を回避できます。
VAE は自動的に使用されますので、主に UNet を使用します。
この設定は動作が重くなりますので、OOM が発生して困っている時にだけ有効にしてください。
手元の環境では Never OOM Integrated で OOM を回避できていますが、Forge の起動オプションによる回避策もあります。
Never OOM Integrated で回避できない OOM が、起動オプションで回避できた環境がありましたらお知らせください。
Forge の起動オプションに PYTORCH_CUDA_ALLOC_CONF を指定するには SdxlWebUi-forge-DisableAutoLaunch.bat をコピーして、SdxlWebUi-forge-CudaAllocConf.bat などにリネームし、内容を以下のように編集します。
@echo off
set PYTORCH_CUDA_ALLOC_CONF=garbage_collection_threshold:0.6,max_split_size_mb:128
call %~dp0SdxlWebUi-forge.bat
同様に Forge のコマンドライン引数 による OOM の回避や高速化も、以下のように指定できます。
@echo off
call %~dp0SdxlWebUi-forge.bat --always-offload-from-vram --cuda-malloc --cuda-stream --pin-shared-memory
-
--always-offload-from-vramはNever OOM Integratedと同様の設定っぽく、同じならいつでも切り替えられるNever OOM Integratedのほうが便利です。 -
--cuda-malloc --cuda-stream --pin-shared-memoryはいずれも高速化しますが不安定化もします。-
--cuda-mallocはset PYTORCH_CUDA_ALLOC_CONF=backend:cudaMallocAsyncと同じ設定です。
-
設定 の Stable Diffusion を以下のようにすると、ふたつのモデルを高速に扱えます。
下 2つの設定が変更されていないかも確認ください。
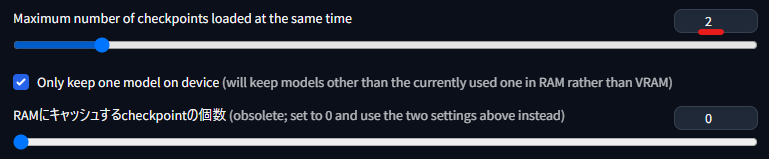
ただし、メインメモリが 32GB 未満であったり、他のプロセスでメインメモリを消費していたりすると、動作が遅くなったり不安定になったりする場合があります。
デフォルトでは Maximum number of checkpoints loaded at the same time が 1 になっています。
SdxlWebUi/config.json に sd_checkpoints_limit の行を以下のように書き加えると、次回起動時から 2 になります。
{
"your_config": "your_config_value",
"ch_civiai_api_key": "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX",
"sd_checkpoints_limit": 2,
"end_of_config": 0
}
Forge の Dev2 ブランチ で安定性が向上するとの声がありますが、確認できていません。
変更点 としては今のところ ControlNet まわりの改善が主に見えます。
EasySdxlWebUi では SdxlWebUi/setup/Checkout-SdxlWebUi-forge-dev2.bat で、Dev2 ブランチへの切り替えと ControlNet エラーへの対策をします。
EasySdxlWebUi の更新時に master ブランチに戻りますので、再度切り替えてください。