You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
function howMuchToRead(n, state) {
if (n <= 0 || (state.length === 0 && state.ended))
return 0;
if (state.objectMode)
return 1;
if (n !== n) {
// Only flow one buffer at a time
if (state.flowing && state.length)
return state.buffer.head.data.length;
else
return state.length;
}
// If we're asking for more than the current hwm, then raise the hwm.
if (n > state.highWaterMark)
state.highWaterMark = computeNewHighWaterMark(n);
if (n <= state.length)
return n;
// Don't have enough
if (!state.ended) { //传输没有结束都是false
state.needReadable = true;
return 0;
}
return state.length;
}
写在最前
本次试图浅析探索Nodejs的Stream模块中对于Readable类的一部分实现(可写流也差不多)。其中会以可读流两种模式中的paused mode即暂停模式的表现形式来解读源码上的实现,为什么不分析flowing mode自然是因为这个模式是我们常用的其原理相比暂停模式下相对简单(其实是因为笔者总是喜欢关注一些边边角角的东西,不按套路出牌=。=),同时核心方法都是一样的,一通百通嘛,有兴趣的童鞋可以自己看下完整源码。
欢迎关注我的博客,不定期更新中——
生产者消费者问题
首先先明确为什么Nodejs要实现一个stream,这就要清楚关于生产者消费者问题的概念。
简单来说就是内存问题。与前端不同,后端对于内存还是相当敏感的,比如读取文件这种操作,如果文件很小就算了,但如果这个文件一个g呢?难道全读出来?这肯定是不可取的。通过流的形式读一部分写一部分慢慢处理才是一个可取的方式。PS:有关为什么使用stream欢迎大家百(谷)度(歌)一下。
实现一个可读流
现在我们将自己实现一个可读流,以此来方便观察之后数据的流动过程:
至此subReadable便是我们实现的自定义可读流。
Paused Mode 暂停模式都做了什么?
先来看下整体的流程:
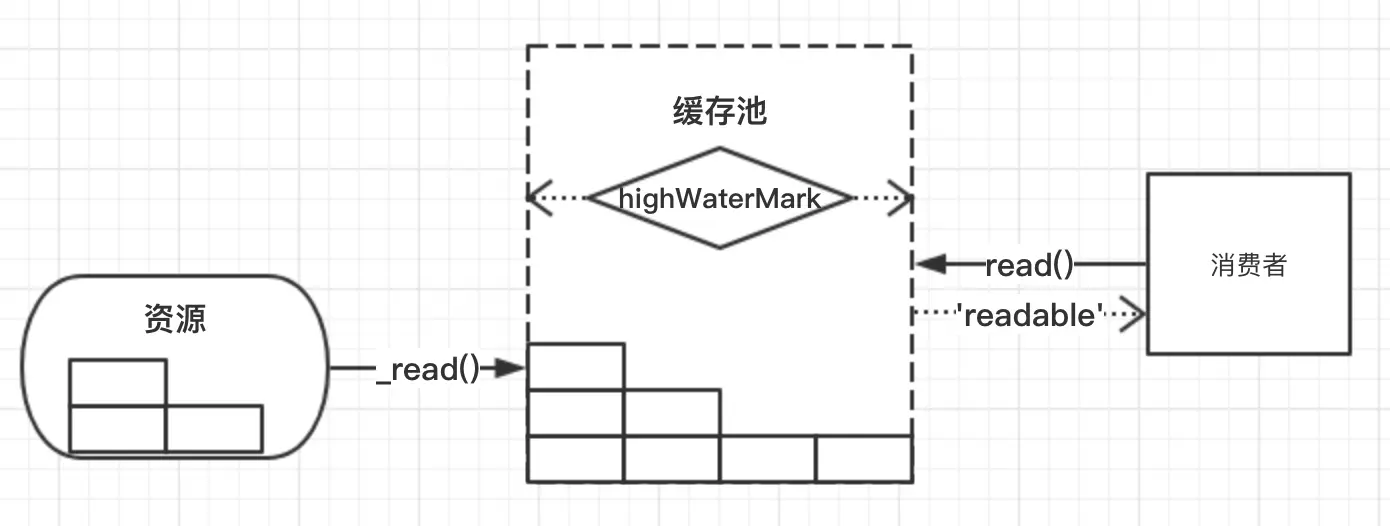
可读流会通过
_read()方式从资源读取数据到缓存池,同时设置了一个阈值highWaterMark,标记数据到缓存池大小的一个上限,这个阈值是会浮动的,最小值也是默认值为16384。当消费者监听了readable事件之后,就可以显式调用read()方法来读取数据。触发暂停模式
通过注册readable事件以此来触发暂停模式:
可以发现当注册
readable事件后可对流会从底层资源推送数据到缓存直到达到超过阈值或者底层数据全部加载完。开始消费数据
调用read(n); n = 1000;
首先修改资源池大小
data: new Array(10000).fill('1')(方便打印数据),执行read(1000)每次读取1000字节资源读取资源:结果执行了两次读取数据,同时如果每次读取的字节少于缓存中的数据,则可读流不会再从资源加载新的数据。
无参调用read()
直接调用
read()后,会逐步读取完全部资源,至于每次读取多少下文会统一探讨。小结
以上我们依次尝试了在实现可读流后触发暂停模式会发生的事情,接下来作者将会对以下几个可能有疑问的点进行探究:
_read()方法并在其中调用push()read()与传入固定数据的区别为什么自己实现的可读流要实现
_read()方法并在其中调用push()当我们调用subReadable.read()便会执行到上面的代码,可以发现,源码中
对于
_read()只是定义了一个接口,里面并没有具体实现,如果我们不自己定义那么就会报错。同时read()中会执行它通过它调用push()来从资源中读取数据,并且传入highWaterMark,这个值你可以用也可以不用因为_read()是我们自己实现的。从代码中可以看出,将底层资源推送到缓存中的核心操作是通过push,通过语义化也可以看出push方法中最后会进行添加新数据的操作。由于之后方法中嵌套很多,不一一展示,直接来看最后调用的方法:
我们可以看出,方法调用的最后确实执行了资源数据推送到缓存的操作。与此同时在会判断needReadable属性值来看是否触发readable回调事件。而这也为之后我们来分析为什么注册了readable事件之后会执行一次回调埋下了伏笔。最后调用maybeReadMore()则是蓄满缓存池的方法。
触发暂停模式后缓存池如何被蓄满
先来看下源码里是如何绑定的事件:
maybeReadMore()中当缓存池存储大小小于阈值时则会一直调用read(0)不读取数据,但是会一直push底层资源到缓存:
绑定监听事件后为何会直接执行一次回调
上文提到过,绑定事件后会开始推送数据至缓存池,最后会执行到addChunk()方法,内部通过needReadable属性来判断是否触发readable事件。当你第一次绑定事件时会执行state.needReadable = true;,从而在最后推送数据后会执行触发readable的操作。
read()与传入特定数值的区别区别在执行read()方法的时候,会将参数n传入到下面这个函数中由它来计算现在应该应该读取多少数据:
当直接调用read(),n参数则为NaN,当处于流动模式的时候n则为buffer头数据的长度,否则是整个缓存的数据长度。若为read(n)传入数字,大于当前的hwm时可以发现会重新计算一个hwm,与此同时如果已缓存的数据小于请求的数据量,那么将设置
state.needReadable = true;并返回0;总结
第一次试图梳理源码的思路,一路写下来发现有很多想说但是又不知道怎么连贯的理清楚=。= 既然代码细节也有些说不清,不过最后还是进行一个核心思路的提炼:
核心方法:
核心属性:
核心思路:
参考资料
最后
源码的边界情况比较多。作者如果哪里说错了请指正=。=
PS:源码地址
惯例po作者的博客,不定时更新中——
有问题欢迎在issues下交流。
The text was updated successfully, but these errors were encountered: