本文是基于
jdk1.7.0_79分析
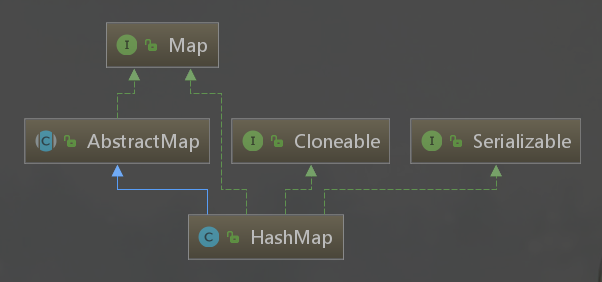
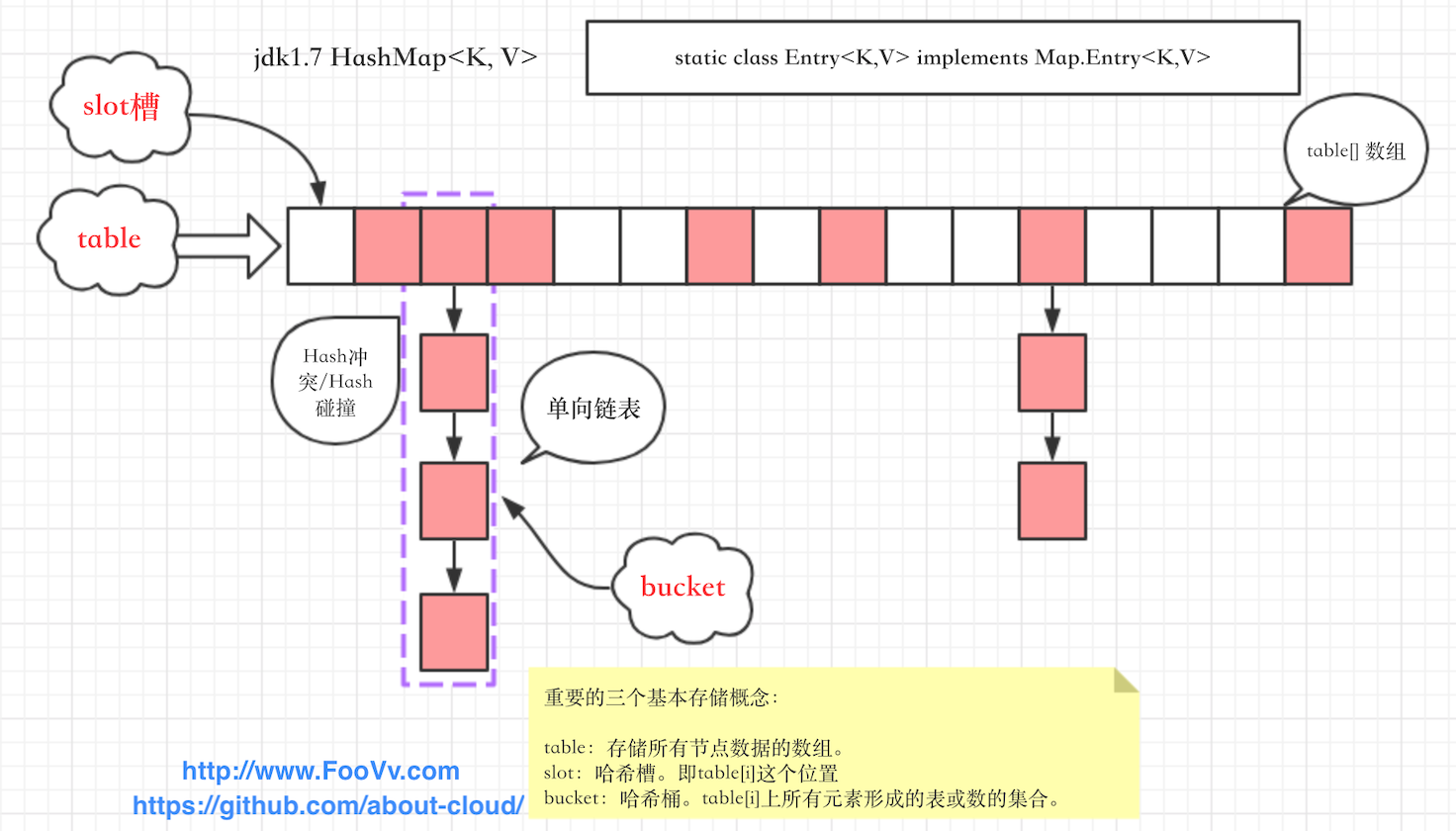
jdk1.7HashMap的底层数据结构:数组 + 单向线性链表。HashMap的元素就是在 Map.Entry 的基础上实现的Entry项。
上一节分析了 哈希冲突 和 解决哈希冲突的算法,HashMap 就是基于 链表法 来解决哈希冲突的。
/** 默认初始容量 16 */
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 既 16
/** 最大容量 10.7亿+(这里也用到效率高的位运算) */
static final int MAXIMUM_CAPACITY = 1 << 30;
/** 默认负载因子 0.75 */
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/** 当 table 未填充的时候,共享这个空table */
static final Entry<?,?>[] EMPTY_TABLE = {};
/** (这个表又称为基本表)该 table 根据需要而调整大小。长度必须始终是2的次幂。 */
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
/** map 中 存储 key-value 映射的数量 */
transient int size;
/** 下次调整大小时的阈值(容量 * 负载因子) */
int threshold;
/** 哈希表的负载因子 */
final float loadFactor;
/** 此 HashMap 修改的次数 */
transient int modCount;
/** 默认容量的最大值:Integer.MAX_VALUE */
static final int ALTERNATIVE_HASHING_THRESHOLD_DEFAULT = Integer.MAX_VALUE;HashMap 重点元素 项Entry<K, V>:之前文章已讲解了 Map.Entry 接口,下面就来分析一下 jdk1.7 HashMap实现Map.Entry 的 Entry<K, V>:
static class Entry<K,V> implements Map.Entry<K,V> {
// final 修饰的 key,防止被重复赋值
final K key;
// 可被重复设置值的value
V value;
// 此项的下一项(用于链表。并没有类四的 Entry<K, V> prev,说名是单链表)
Entry<K,V> next;
int hash;
/**
* 构造方法用于注入 entry项 的属性值(或引用)
* 参数从左至右依次是:key的哈希码,key,value,指向的下一个entry
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
// getter & toString 方法
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
public final String toString() {
return getKey() + "=" + getValue();
}
// 设置节点的新值value
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
// 比较节点的方法
public final boolean equals(Object o) {
// 检查类型
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o;
// 当前项的key
Object k1 = getKey();
// 被比较对象的key
Object k2 = e.getKey();
// 这里说明一下 Object,它的 equals方法很简单,就是用 == 来做判断的
if (k1 == k2 || (k1 != null && k1.equals(k2))) {
Object v1 = getValue();
Object v2 = e.getValue();
if (v1 == v2 || (v1 != null && v1.equals(v2)))
return true;
}
return false;
}
// 返回节点的哈希码
public final int hashCode() {
return Objects.hashCode(getKey()) ^ Objects.hashCode(getValue());
}
/**
* 当entry被访问时,都会调用此方法
* 这里只不过是一个空方法
*/
void recordAccess(HashMap<K,V> m) {
}
/**
* 每当entry项从表格中删除时,都会调用这个空方法
*/
void recordRemoval(HashMap<K,V> m) {
}
}public V put(K key, V value) {
// 判断是否为空表
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
// 如果key为null的情况下,将将键值对放在table[0]处
// 如果table[0]已存在元素,则将替换value
return putForNullKey(value);
// key的哈希值
int hash = hash(key);
// 可以的哈希码对表的长度模运算,计算并得到哈希槽的位置
int i = indexFor(hash, table.length);
// 对哈希桶(链表)进行遍历,靠指针地址移动
// 查找是否包含key的项,如果包含就将value换掉
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
// 该元素的哈希码与新增项的key的哈希码项相等,并且 key 也相同
// 那么就会替换 value(因为key具有唯一性,相同的key要替换value)
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
// 被替换的旧值
V oldValue = e.value;
// 选用新的value
e.value = value;
// 调用上面的空方法
e.recordAccess(this);
// 返回旧值
return oldValue;
}
}
// 如果上面for循环没有查找到key的存在(或者说没有找到相同的key),那么就新添加一项
modCount++; // modCount加1
// 添加entry项
addEntry(hash, key, value, i);
return null;
}
/**
* 将具有指定key、value、key的哈希码、桶号(也就是哈希槽的位置)的条目(元素)(项)
* 添加到指定的桶(哈希桶)。
* 此方法会在适当的情况下调整桶的大小
* 子类也可以重写此方法来改变put添加的行为
*/
void addEntry(int hash, K key, V value, int bucketIndex) {
// 如果已添加元素项的实际大小达到了HashMap所承载的阈值,并且哈希槽的位置不为空
// 那么就进行扩容
if ((size >= threshold) && (null != table[bucketIndex])) {
// 扩容后的大小是2倍于原基本表的长度
resize(2 * table.length);
// 因为基本表已经扩容,那么对key重新计算哈希值
// 如果 key 不为 null 那么计算key的哈希值,否则哈希值直接记为0
hash = (null != key) ? hash(key) : 0;
// 根据哈希码和基本表(数组)长度计算桶号
// indexFor 方法并没有使用模运行,而是使用高性能的逻辑与&运算
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}/**
* 此方法与 addEntry 不同,只有在创建 entry项的时候使用此方法
* 作为构建(或伪构建) Map 的一部分。"伪构建" 是指 克隆、反序列。
* 使用此方法是不必担心扩容问题。
* 子类可以重新此方法改变方法的功能,比如将单向链表改成双向链表等等。
*/
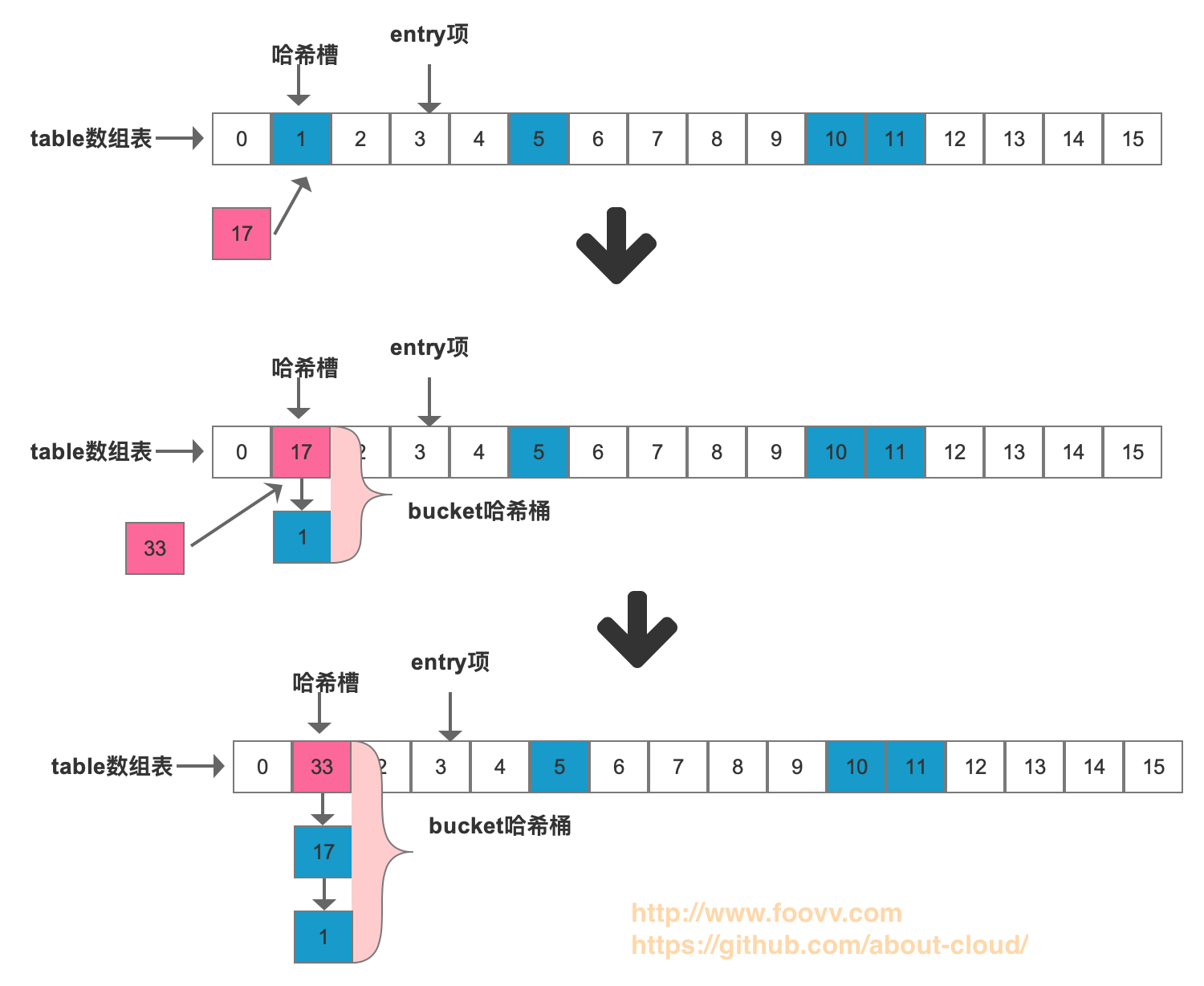
void createEntry(int hash, K key, V value, int bucketIndex) {
// 原位置的元素项要下沉,新的元素放在哈希槽(桶顶)的位置
Entry<K,V> e = table[bucketIndex];
// 构造新的元素项放在哈西槽(桶顶),同步把原有的元素项链入其后
table[bucketIndex] = new Entry<>(hash, key, value, e);
// 实际大小加1
size++;
}链表的时候讲要添加的元素项放到桶顶,那么先进的元素项位于链表的尾部,后进的元素项位于链表的头部。(这只是本版本
HashMap的实现方式)
/**
* 扩容方法就是给 map 换一个更大容量的新数组。
* 前提前提条件是已添加元素项的实际大小达到了HashMap所承载的阈值。
*
* 如果当前容量达到最大容量, 此方法也能给map扩容。但是可以设置阈值为Integer类型的最大值。
*
* @param newCapacity 新的容量, 必须是2的次幂;
* 必须大于当前容量,除非当前容量达到了最大值。
* (在这种情况下值是无关紧要的)
*/
void resize(int newCapacity) {
// 当前table数组
Entry[] oldTable = table;
// 当前table数组长度
int oldCapacity = oldTable.length;
// 如果当前数组达到了最大容量(1<<30),那么赋值阈值为Integer的最大值,并直接返回🔙
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
// new 新的数组
Entry[] newTable = new Entry[newCapacity];
// 将当前的数组上索引元素项转移到新的数组上
transfer(newTable, initHashSeedAsNeeded(newCapacity));
// 当前数组指向新数组,完成扩容
table = newTable;
// 计算阈值
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
/**
* 将当前的数组上索引元素项转移到新的数组上
*/
void transfer(Entry[] newTable, boolean rehash) {
// 新数组的长度(容量)
int newCapacity = newTable.length;
// 首先横向遍历数组
for (Entry<K,V> e : table) {
// 然后纵向遍历链表
while(null != e) {
// 链表中提前获取下一个元素项(节点)
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
// 重新计算存放元素
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}🎯🎯🎯 上面已经看出每次扩容时都伴随着所有元素项的重新 选址 存放,这不仅大大牺牲性能,而且耗时。所以在使用 HashMap 一定要评估存放元素项的数量,指定map的大小。
删除元素项的的思路基本和添加操作相似,只不过一个是添加,一个是删除。先根据
key计算哈希槽(桶的位置),然后循环链表比较判断,这里参考:telescope:之前关于LinkedList文章的删除节点操作吧。
key的哈希码对 基本表 做 逻辑与 运算 h&(length-1),来确定此元素项的数组上的位置。 原因就出在 二进制 的 与& 操作上了。与& 运算规则:
0&0=0;0&1=0;1&0=0;1&1=1;
| (指数形式)length | (十进制)length | (十进制)length - 1 | (二进制)length - 1 |
|---|---|---|---|
| $$1^2$$ | 2 | 1 | 1 |
| $$2^2$$ | 4 | 3 | 11 |
| $$3^2$$ | 8 | 7 | 111 |
| $$4^2$$ | 16 | 15 | 1111 |
| ... | ... | ... |
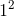{kind=link}
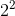{kind=link}
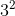{kind=link}
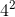{kind=link}
这种情况下,
length - 1二进制的 最右位 永远是1。这样0 & 1 = 0,1 & 1 = 1的结果既有0又有1。对于 哈希槽 的二进制最右位为1(十进制的奇数)的位置就有可能被填充,而不至于浪费存储空间。如果
HashMap的容量不是2的次幂,比如 容量length为19,length - 1的二进制为10010,任何常数与之作 与& 运算,二进制最右位都是0,那么只能存放 (十进制)尾数为偶数的数组位置,这样会大大浪费空间。