model.get_entities predict output is different from the demo #2
Comments
|
I confirm this problem. |
|
@xashru could you give us a clue as to what could have changed since you wrote the code? Is it something about the underlying Roberta model? |
|
@ZXCY if you are still looking at this - I managed to get the code working after understanding it better. The possible causes for the error:
The second point makes me believe that My solution therefore was:
The trick is that the Output: |
|
@tilusnet Thanks for that explanation, I was able to get the same output as the demo using your steps. However, I have noticed that the |
|
@vivianamarquez by the look of it the parameter name is |
|
I am getting an error like /usr/lib/python3.8/encodings/ascii.py in decode(self, input, final) UnicodeDecodeError: 'ascii' codec can't decode byte 0xe2 in position 508: ordinal not in range(128) Can you please help me to understand this error |
|
Hi! |
|
do pip install markupsafe==2.0.1 |
Hi, I have some trouble in model.get_entities.


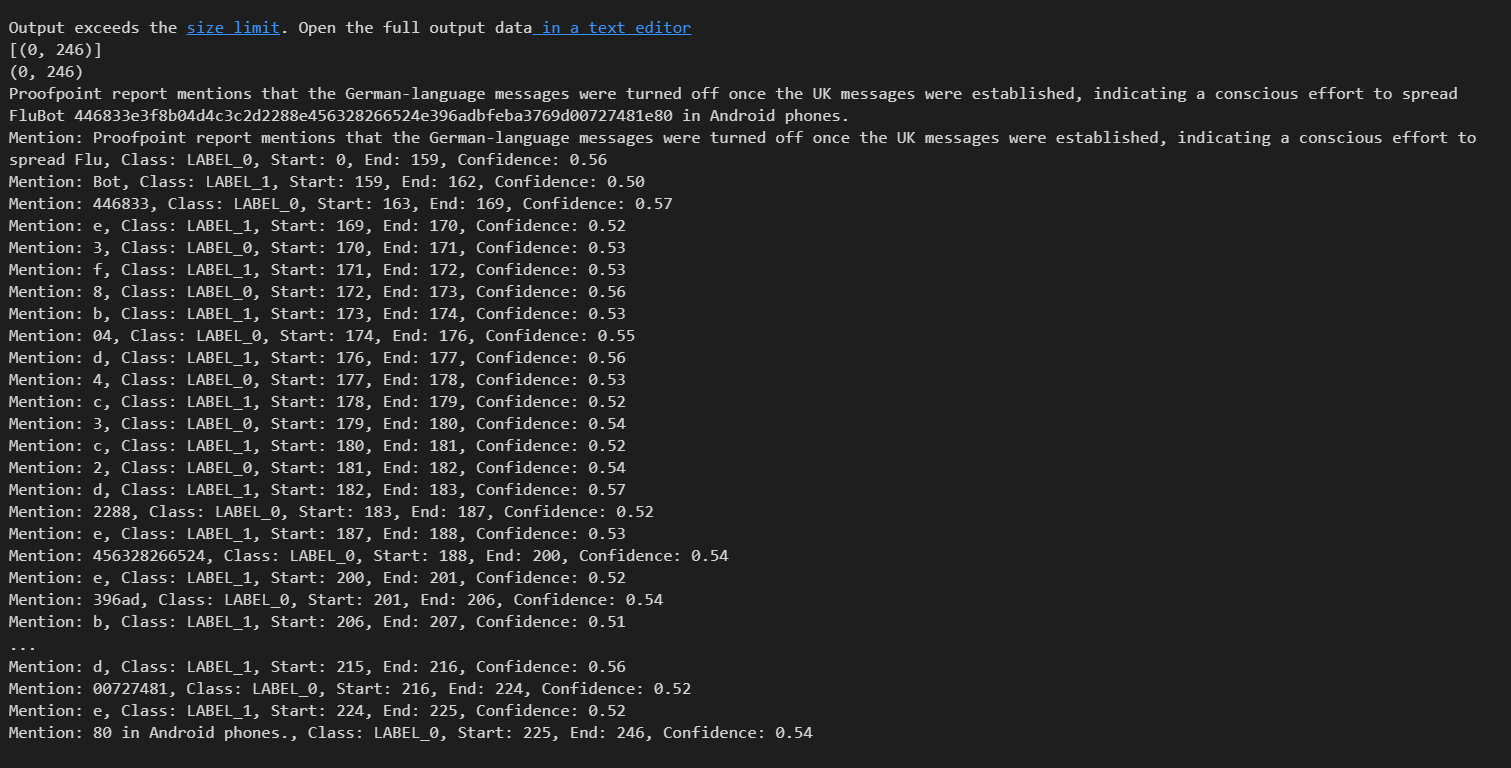
The following picture is my code (same as demo), I'm not sure what's going on. :(
Sometimes will predict the different output with the same code (both of them are different from the demo's output).
The text was updated successfully, but these errors were encountered: