![]()


Docs | Discord | Twitter | LinkedIn
Albumentations is a Python library for image augmentation. Image augmentation is used in deep learning and computer vision tasks to increase the quality of trained models. The purpose of image augmentation is to create new training samples from the existing data.
Here is an example of how you can apply some pixel-level augmentations from Albumentations to create new images from the original one:

- Albumentations supports all common computer vision tasks such as classification, semantic segmentation, instance segmentation, object detection, and pose estimation.
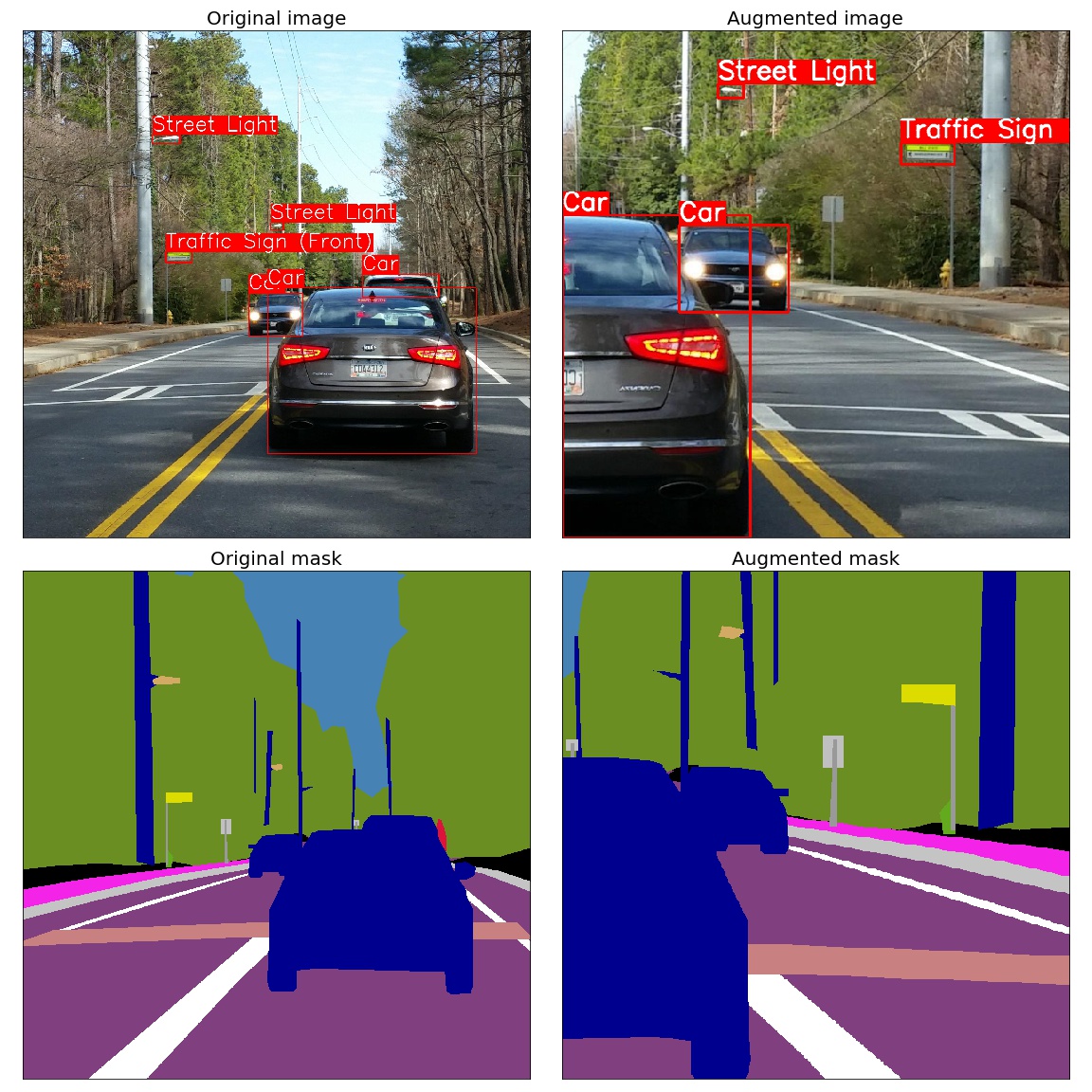
- The library provides a simple unified API to work with all data types: images (RBG-images, grayscale images, multispectral images), segmentation masks, bounding boxes, and keypoints.
- The library contains more than 70 different augmentations to generate new training samples from the existing data.
- Albumentations is fast. We benchmark each new release to ensure that augmentations provide maximum speed.
- It works with popular deep learning frameworks such as PyTorch and TensorFlow. By the way, Albumentations is a part of the PyTorch ecosystem.
- Written by experts. The authors have experience both working on production computer vision systems and participating in competitive machine learning. Many core team members are Kaggle Masters and Grandmasters.
- The library is widely used in industry, deep learning research, machine learning competitions, and open source projects.

- Albumentations
Vladimir I. Iglovikov | Kaggle Grandmaster
Mikhail Druzhinin | Kaggle Expert
Alexander Buslaev — Computer Vision Engineer at Mapbox | Kaggle Master
Evegene Khvedchenya — Computer Vision Research Engineer at Piñata Farms | Kaggle Grandmaster
Albumentations requires Python 3.8 or higher. To install the latest version from PyPI:
pip install -U albumentationsOther installation options are described in the documentation.
The full documentation is available at https://albumentations.ai/docs/.
import albumentations as A
import cv2
# Declare an augmentation pipeline
transform = A.Compose([
A.RandomCrop(width=256, height=256),
A.HorizontalFlip(p=0.5),
A.RandomBrightnessContrast(p=0.2),
])
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("image.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = transform(image=image)
transformed_image = transformed["image"]Please start with the introduction articles about why image augmentation is important and how it helps to build better models.
If you want to use Albumentations for a specific task such as classification, segmentation, or object detection, refer to the set of articles that has an in-depth description of this task. We also have a list of examples on applying Albumentations for different use cases.
We have examples of using Albumentations along with PyTorch and TensorFlow.
Check the online demo of the library. With it, you can apply augmentations to different images and see the result. Also, we have a list of all available augmentations and their targets.














- A list of papers that cite Albumentations.
- A list of teams that were using Albumentations and took high places in machine learning competitions.
- Open source projects that use Albumentations.
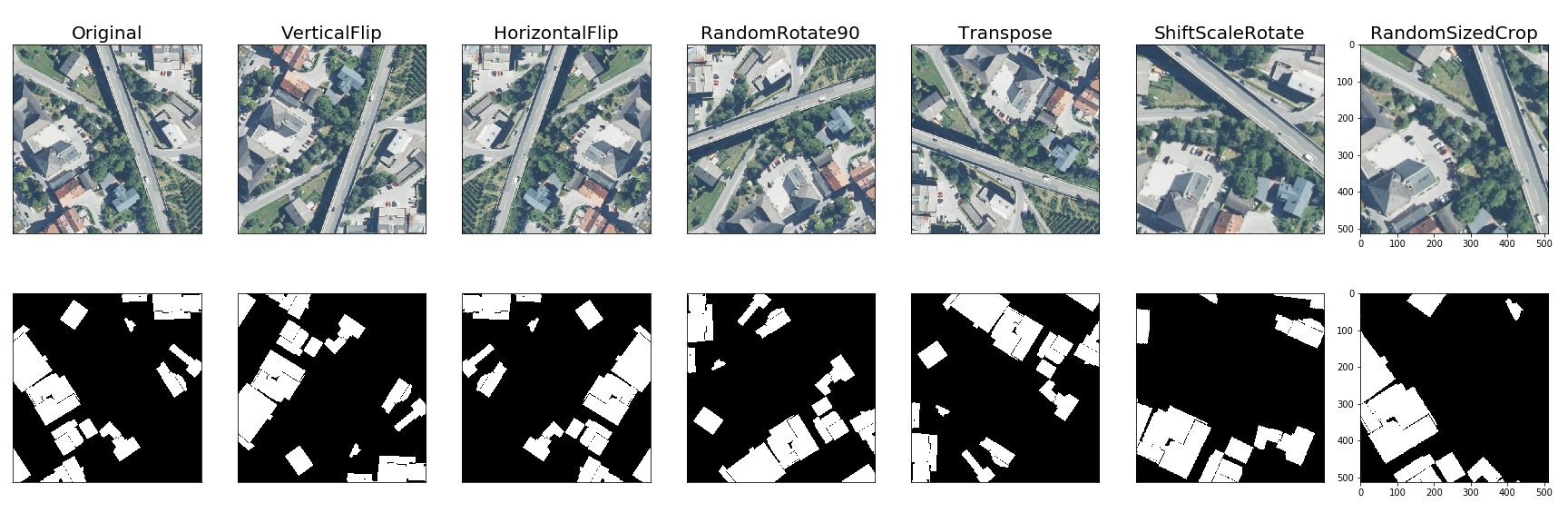
Pixel-level transforms will change just an input image and will leave any additional targets such as masks, bounding boxes, and keypoints unchanged. The list of pixel-level transforms:
- AdvancedBlur
- Blur
- CLAHE
- ChannelDropout
- ChannelShuffle
- ChromaticAberration
- ColorJitter
- Defocus
- Downscale
- Emboss
- Equalize
- FDA
- FancyPCA
- FromFloat
- GaussNoise
- GaussianBlur
- GlassBlur
- HistogramMatching
- HueSaturationValue
- ISONoise
- ImageCompression
- InvertImg
- MedianBlur
- MotionBlur
- MultiplicativeNoise
- Normalize
- PixelDistributionAdaptation
- Posterize
- RGBShift
- RandomBrightnessContrast
- RandomFog
- RandomGamma
- RandomGravel
- RandomRain
- RandomShadow
- RandomSnow
- RandomSunFlare
- RandomToneCurve
- RingingOvershoot
- Sharpen
- Solarize
- Spatter
- Superpixels
- TemplateTransform
- ToFloat
- ToGray
- ToRGB
- ToSepia
- UnsharpMask
- ZoomBlur
Spatial-level transforms will simultaneously change both an input image as well as additional targets such as masks, bounding boxes, and keypoints. The following table shows which additional targets are supported by each transform.
| Transform | Image | Mask | BBoxes | Keypoints |
|---|---|---|---|---|
| Affine | ✓ | ✓ | ✓ | ✓ |
| BBoxSafeRandomCrop | ✓ | ✓ | ✓ | |
| CenterCrop | ✓ | ✓ | ✓ | ✓ |
| CoarseDropout | ✓ | ✓ | ✓ | |
| Crop | ✓ | ✓ | ✓ | ✓ |
| CropAndPad | ✓ | ✓ | ✓ | ✓ |
| CropNonEmptyMaskIfExists | ✓ | ✓ | ✓ | ✓ |
| D4 | ✓ | ✓ | ✓ | ✓ |
| ElasticTransform | ✓ | ✓ | ✓ | |
| Flip | ✓ | ✓ | ✓ | ✓ |
| GridDistortion | ✓ | ✓ | ✓ | |
| GridDropout | ✓ | ✓ | ||
| HorizontalFlip | ✓ | ✓ | ✓ | ✓ |
| Lambda | ✓ | ✓ | ✓ | ✓ |
| LongestMaxSize | ✓ | ✓ | ✓ | ✓ |
| MaskDropout | ✓ | ✓ | ||
| Morphological | ✓ | ✓ | ||
| NoOp | ✓ | ✓ | ✓ | ✓ |
| OpticalDistortion | ✓ | ✓ | ✓ | |
| PadIfNeeded | ✓ | ✓ | ✓ | ✓ |
| Perspective | ✓ | ✓ | ✓ | ✓ |
| PiecewiseAffine | ✓ | ✓ | ✓ | ✓ |
| PixelDropout | ✓ | ✓ | ||
| RandomCrop | ✓ | ✓ | ✓ | ✓ |
| RandomCropFromBorders | ✓ | ✓ | ✓ | ✓ |
| RandomGridShuffle | ✓ | ✓ | ✓ | |
| RandomResizedCrop | ✓ | ✓ | ✓ | ✓ |
| RandomRotate90 | ✓ | ✓ | ✓ | ✓ |
| RandomScale | ✓ | ✓ | ✓ | ✓ |
| RandomSizedBBoxSafeCrop | ✓ | ✓ | ✓ | |
| RandomSizedCrop | ✓ | ✓ | ✓ | ✓ |
| Resize | ✓ | ✓ | ✓ | ✓ |
| Rotate | ✓ | ✓ | ✓ | ✓ |
| SafeRotate | ✓ | ✓ | ✓ | ✓ |
| ShiftScaleRotate | ✓ | ✓ | ✓ | ✓ |
| SmallestMaxSize | ✓ | ✓ | ✓ | ✓ |
| Transpose | ✓ | ✓ | ✓ | ✓ |
| VerticalFlip | ✓ | ✓ | ✓ | ✓ |
| XYMasking | ✓ | ✓ | ✓ |
Transforms that mix several images into one
| Transform | Image | Mask | BBoxes | Keypoints | Global Label |
|---|---|---|---|---|---|
| MixUp | ✓ | ✓ | ✓ |


To run the benchmark yourself, follow the instructions in benchmark/README.md
Results for running the benchmark on the first 2000 images from the ImageNet validation set using an AMD Ryzen Threadripper 3970X CPU. The table shows how many images per second can be processed on a single core; higher is better.
| Library | Version |
|---|---|
| Python | 3.10.13 (main, Sep 11 2023, 13:44:35) [GCC 11.2.0] |
| albumentations | 1.4.1 |
| imgaug | 0.4.0 |
| torchvision | 0.17.1+rocm5.7 |
| numpy | 1.26.4 |
| opencv-python-headless | 4.9.0.80 |
| scikit-image | 0.22.0 |
| scipy | 1.12.0 |
| pillow | 10.2.0 |
| kornia | 0.7.2 |
| augly | 1.0.0 |
| albumentations 1.4.0 |
torchvision 0.17.1+rocm5.7 |
kornia 0.7.2 |
augly 1.0.0 |
imgaug 0.4.0 |
|
|---|---|---|---|---|---|
| HorizontalFlip | 9843 ± 2135 | 2436 ± 29 | 1014 ± 3 | 3663 ± 18 | 4884 ± 51 |
| VerticalFlip | 9898 ± 18 | 2570 ± 37 | 1024 ± 4 | 5325 ± 13 | 8683 ± 5 |
| Rotate | 610 ± 4 | 153 ± 2 | 204 ± 1 | 626 ± 3 | 499 ± 5 |
| Affine | 1705 ± 67 | 159 ± 1 | 200 ± 1 | - | 663 ± 24 |
| Equalize | 1061 ± 14 | 337 ± 1 | 77 ± 1 | - | 845 ± 33 |
| RandomCrop64 | 203197 ± 2105 | 15931 ± 27 | 837 ± 2 | 21858 ± 362 | 5681 ± 96 |
| RandomResizedCrop | 2998 ± 30 | 1160 ± 4 | 190 ± 1 | - | - |
| ShiftRGB | 1400 ± 3 | - | 435 ± 1 | - | 1528 ± 6 |
| Resize | 2581 ± 3 | 1239 ± 1 | 197 ± 1 | 431 ± 1 | 1728 ± 1 |
| RandomGamma | 4556 ± 3 | 230 ± 1 | 205 ± 1 | - | 2282 ± 110 |
| Grayscale | 7234 ± 4 | 1539 ± 7 | 444 ± 3 | 2606 ± 2 | 918 ± 42 |
| ColorJitter | 452 ± 43 | 51 ± 1 | 50 ± 1 | 221 ± 1 | - |
| RandomPerspective | 465 ± 1 | 121 ± 1 | 115 ± 1 | - | 433 ± 16 |
| GaussianBlur | 2315 ± 9 | 106 ± 2 | 72 ± 1 | 161 ± 1 | 1213 ± 3 |
| MedianBlur | 3711 ± 2 | - | 2 ± 1 | - | 566 ± 3 |
| MotionBlur | 2763 ± 25 | - | 101 ± 4 | - | 508 ± 2 |
| Posterize | 4238 ± 51 | 2581 ± 20 | 284 ± 4 | - | 1893 ± 9 |
| JpegCompression | 208 ± 1 | - | - | 692 ± 4 | 435 ± 1 |
| GaussianNoise | 64 ± 9 | - | - | 67 ± 1 | 212 ± 16 |
| Elastic | 129 ± 1 | 3 ± 1 | 1 ± 1 | - | 128 ± 1 |
To create a pull request to the repository, follow the documentation at CONTRIBUTING.md
In some systems, in the multiple GPU regime, PyTorch may deadlock the DataLoader if OpenCV was compiled with OpenCL optimizations. Adding the following two lines before the library import may help. For more details pytorch/pytorch#1355
cv2.setNumThreads(0)
cv2.ocl.setUseOpenCL(False)If you find this library useful for your research, please consider citing Albumentations: Fast and Flexible Image Augmentations:
@Article{info11020125,
AUTHOR = {Buslaev, Alexander and Iglovikov, Vladimir I. and Khvedchenya, Eugene and Parinov, Alex and Druzhinin, Mikhail and Kalinin, Alexandr A.},
TITLE = {Albumentations: Fast and Flexible Image Augmentations},
JOURNAL = {Information},
VOLUME = {11},
YEAR = {2020},
NUMBER = {2},
ARTICLE-NUMBER = {125},
URL = {https://www.mdpi.com/2078-2489/11/2/125},
ISSN = {2078-2489},
DOI = {10.3390/info11020125}
}