The movies are recommended based on the content of the movie you entered or selected. The main parameters that are considered for the recommendations are the genre, director, and top 3 casts. The details of the movies, such as title, genre, runtime, rating, poster, casts, etc., are fetched from TMDB. The reviews of each individual movie given by the users are "web-scraped" from the IMDB, and the reviews are subjected to sentiment analysis, where the model predicts whether the review is positive or negative.
Simply a Recommendation System is a filtration program whose prime goal is to predict the “rating” or “preference” of a user towards a domain-specific item or item. In our case, this domain-specific item is a movie, therefore the main focus of our recommendation system is to filter and predict only those movies which a user would prefer given some data about the user him or herself.
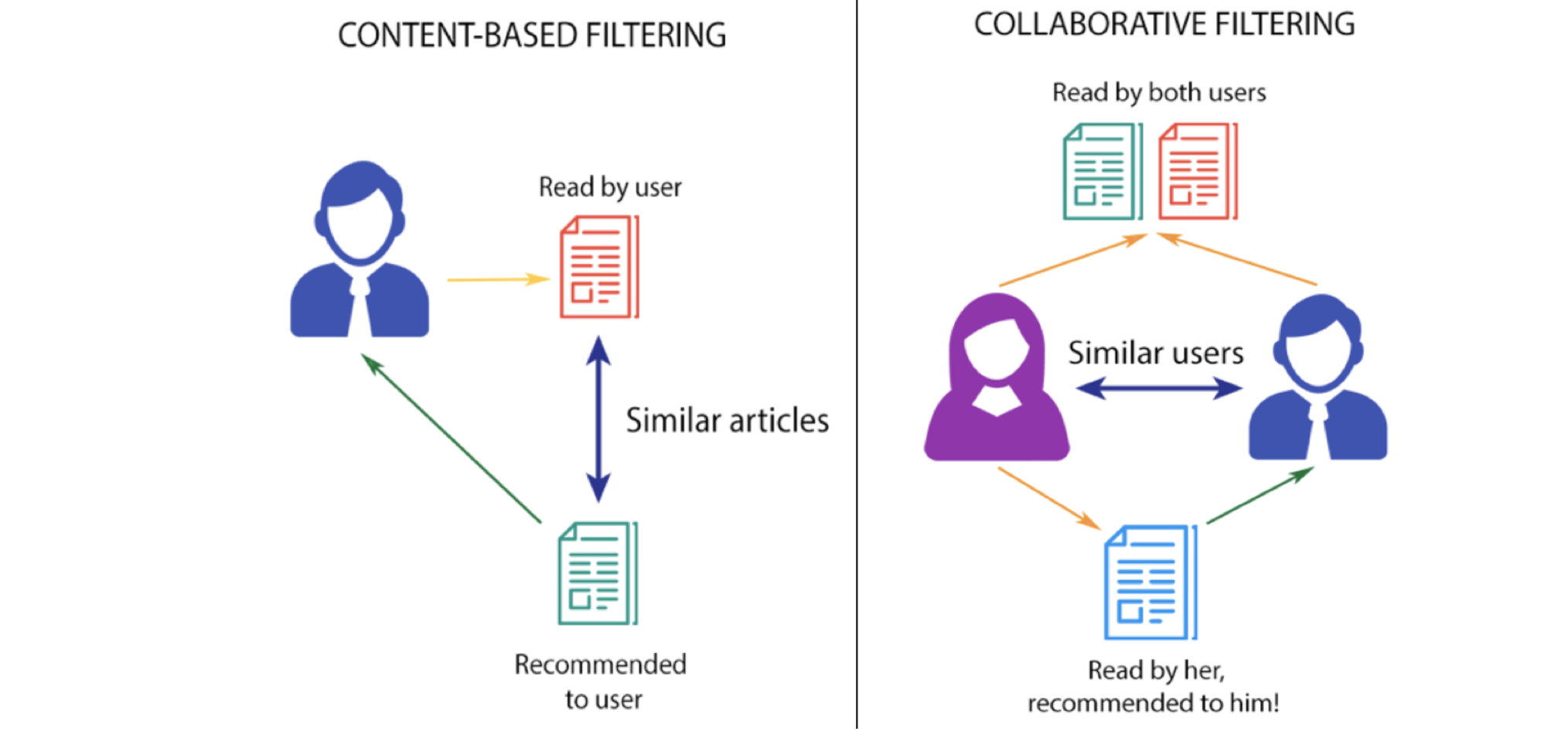

How does it decide which item is most similar to the item user likes(or selects in our case)? Here comes the similarity scores.
It is a numerical value ranges between zero to one which helps to determine how much two items are similar to each other on a scale of zero to one. This similarity score is obtained measuring the similarity between the text details of both of the items. So, similarity score is the measure of similarity between given text details of two items. This can be done by cosine-similarity.
Cosine similarity is a metric used to measure how similar the documents are irrespective of their size. Mathematically, it measures the cosine of the angle between two vectors projected in a multi-dimensional space. The cosine similarity is advantageous because even if the two similar documents are far apart by the Euclidean distance (due to the size of the document), chances are they may still be oriented closer together. The smaller the angle, higher the cosine similarity.

More about Cosine Similarity : Understanding the Math behind Cosine Similarity



