100万行代码是怎样的体验? #13
Comments
|
感谢好文,不知道方不方便输出具体的工程样例模板作为学习呢 |
|
在ATA好像看到过这篇文章 |
|
这是来自QQ邮箱的假期自动回复邮件。您好,我最近正在休假中,无法亲自回复您的邮件。我将在假期结束后,尽快给您回复。
|
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
近年来,阿里数据中台产品发展迅速。核心产品之 Quick BI 连续 2 年成为国内唯一入选 Gartner 魔力象限的国产 BI。Quick BI 单一代码仓库源码突破了 100万行。整个开发过程涉及到的人员和模块都很多,因为下面分享的一些原则,产品能一直做到快速迭代。
先分享几个关键数据:
很多人会问,这么多代码,为什么不切分代码库?还不赶快引入微前端、Serverless 框架?你们就不担心无法维护,启动龟速吗?
实际情况是,从第一天开始,就预估到会有这么大的代码量。启动时间也从最初的几秒钟到后面越来越慢5~10分钟,再优化到近期的5秒钟。整个过程下来,团队更感受到 Monorepo(单一代码仓库)的优势。
这个实践想说明:
开工
2019年4月30号,晴朗的下午,刚好是喜迎五一的前一天,发挥集体智慧,投票选出满意的仓库名。最开始是做 Quick BI 的底座,后来底座越来越大,把上层业务代码也吸纳进来。
commit 769bf68c1740631b39dca6931a19a5e1692be48d Date: Tue Apr 30 17:48:52 2019 +0800 A New Era of BI BeginsWhy Monorepo?
在开工之前,对单一仓库(Monorepo)和多仓库(Polyrepo)团队内做了很多的讨论。
曾经我也很喜欢 Polyrepo,为每个组件建立独立 repo 独立 npm,比如2019年前,单是表单类的编辑器组件就有 43 个:
本以为这样可以做到 完美的解耦、极致的复用??
但实际上:
最终我们把所有这些组件都合并到一个仓库,其实像 Google/Facebook/Microsoft 这些公司内部都很推崇 Monorepo。
但我们不是原教旨主义的 Monorepo,没必要把不相关的产品代码硬放到一起。在实线团队内部,单个产品可以使用 Monorepo,会极大降低协同成本。但开始的时候,团队内还是有很多疑问。
关于 Monorepo 的几个核心疑问?
1. 单一仓库,体积会很大吧?
100 万行代码的体积有多大?
先来猜一下:1GB?10GB?还是更多?
首先,按照公式计算一下:
i. 我们一起来算一下源码的体积:
一般建议每行小于 120 字符,我们取每行 100 个字符来算,100 万行就是:
那我们的仓库实际多大呢?
只有 85 MB!也就是平均每行 85 个字符。
ii. 再来算一下
.git的体积:.git里记录了所有代码的提交历史、branch 和 tag 信息。会很大体积吧?实际上 Git 底层做了很多的优化:1. 所有 branch 和 tag 都是引用;2. 对变更是增量存储;3. 变更对象存储的时候会使用 zlib 压缩。(对于重复出现的样板代码只会存储一次,对于规范化的代码压缩比例极高)。
按照我们的经验,
.git记录10,000次 commit 提交只需要额外的1~3个代码体积即可。iii. 资源文件大小
Git 做了很多针对源码的优化,但视频和音频这类资源文件除外。我们最近使用 BFG 把另一个产品的仓库从 22GB 优化到 200MB,降低 99%!而且优化后代码的提交历史和分支都得到了保留(因为 BFG 会编辑 Git 提交记录,部分 commit id 会变化)。
以前 22 GB 是因为仓库里存放视频、发布的 build 文件和 sourcemap 文件,这些都不应该放到源码仓库。
小结一下,百万行代码体积一般在 200MB ~ 400MB 之间。那来估算下
1000 万行代码占用体积是多少?乘以十也就是
2GB ~ 4GB之间。这对比node_modules随随便便几个 G 来说,并不算什么,很容易管理。补充个案例,Linux 内核有 2800 万行,使用 Monorepo,数千人协同。据说当时 Linus 就是为了管理 Linux 的源码而开发出 Git。
2. 启动很慢吧?5分钟还是10分钟?
听到有些团队讲,代码十几万行,启动 10+分钟,典型的“巨石”项目,已经很难维护了。赶紧拆包、或者改微前端。可能团队才 3 个人却拆了 5 个项目,协同起来非常麻烦。
我们做法有3个:
尤其是 Webpack 切换到 Vite 以后,最终项目冷启动时间由 2-5分钟 优化到 **5秒 **内。
热编译时间由原来 5秒 优化到 1秒 内,Apple M1 电脑基本都是 500ms 以内。
3. 代码复用怎么办?Monorepo 复用的时候是否要引入全部?
传统的软件工程思想追求 DRY,但并不是越 DRY 越好。
每写一行代码,都产生了相应代价:维护的成本。为了减少代码,我们有了可复用的模块。但是代码复用有一个问题:当你以后想要修改的时候它就会成为一个障碍。
对于像 Quick BI 这样长期迭代的产品,绝大部分需求都是对原有功能的扩展,所以写出易维护的代码最重要。因此,团队不鼓励使用 magic 的特技写法;不单纯追求代码复用率,而是追求更易于修改;鼓励在未来模块下线的时候易于删除的编码方式。
对于确实存在复用的场景,我们做了拆包。Monorepo 内部我们拆了多个 package(后面有截图),比如其他产品需要 BI 搭建,可以复用
@alife/bi-designer,并借助于 Tree-Shaking 做到依赖引入的最小化。目前的开发体验
这样的体验要保持并不容易,开发中还有很多问题要解决:
真正需要解决的问题
Monorepo 不是银弹,对于不成熟的团队反而可能是炸弹。因为每个人每次提交都有摧毁整个产品的风险。
要产生价值,需要团队在 协同、技术文化、工程化、质量保障等方面达到深度认可。
1. 包依赖管理
拆包的主要原因有2个,给外部复用以及减少打包后的体积(Tree Shaking 做的不够)。对于小闭环的团队,直接使用子目录让业务快跑就够用了,架构上更简单。
内部拆分多个子包,每个子包对应一个子文件,可以单独发布 npm,见下图:
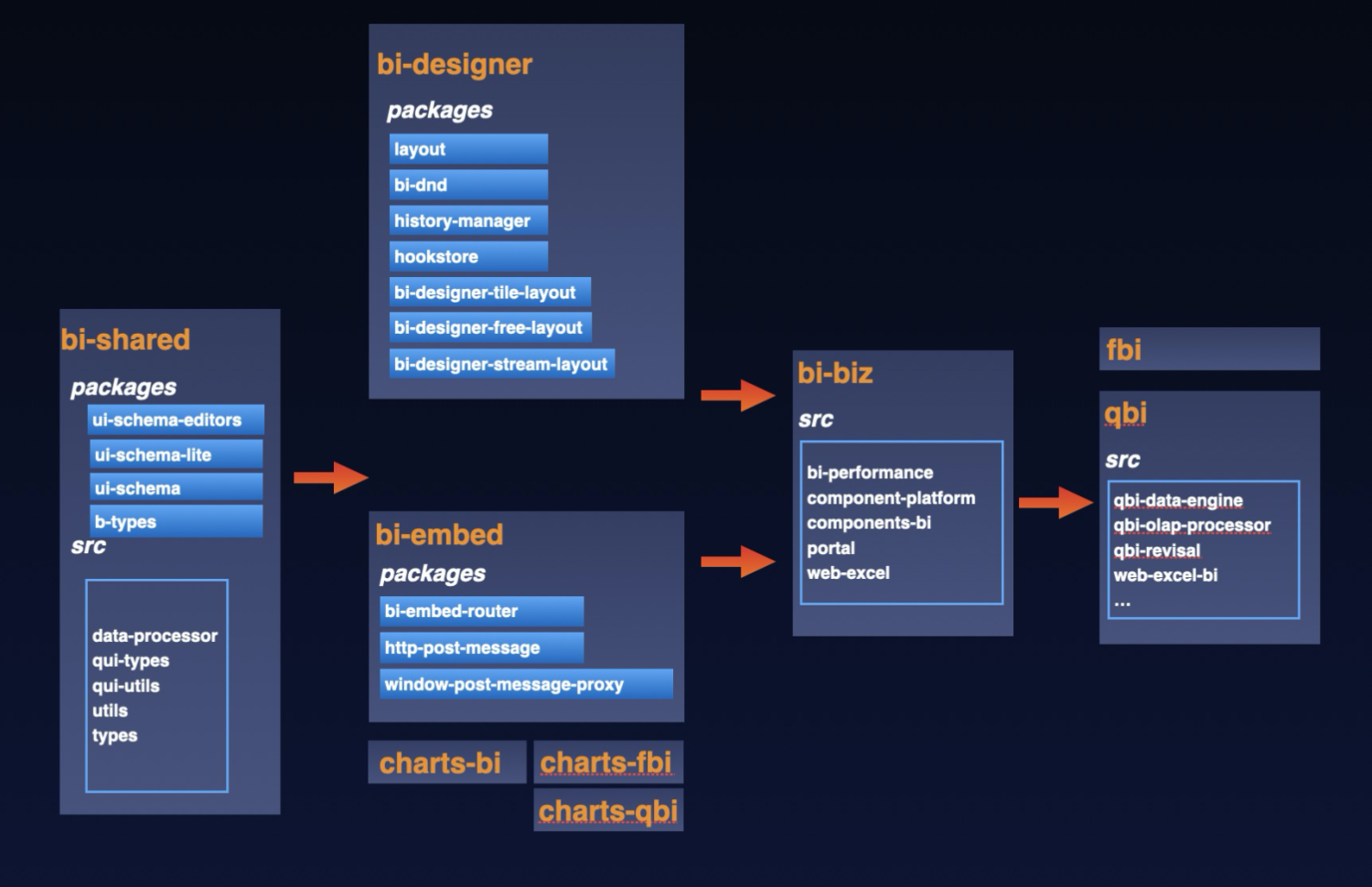
内部包管理的核心原则是:
对于开源 npm 的引入,需要更慎重。大部分 npm 的维护时长不超过x年,即使像 Moment.js 这样曾经标配的工具库也会终止维护。可能有 20% 的 npm 是没人维护。但未来如果你的线上用户遇到问题,你就需要靠自己啃源码,陷入被动。所以我们的原则是,引入开源 npm 要架构组评审通过才行。
2. Code Review 文化
互相 Code Review 能帮助新人快速成长,同时也是打造团队技术文化的方式。
过去几年一直在团队内推行 100% CR,但这还不够。机械的执行很容易把 CR 流于形式,去年开始探索分场景来做。
目前我们的 Code Review 主要分为3个场景:
过去几年,一万两千多次 Code Review 积累的经验有很多,主要是:
3. 工程化建设
这个过程首先要感谢阿里 Def 工程化团队的支持,代码的增加在不断挑战打包机性能和灵活性的边界,Def 都能快速支持。
一般团队都会有开发规范,但能做到自动化工具检查的规范才是好规范。
检查器:ESLint、TS 类型校验、Prettier
语法检查器是推动规范落地的重要方法,ESLint 可以做增量,优化后 git commit 的 pre-hooks 依旧很快。但 TS type check 因为不支持增量就比较慢了,放到本地体验就不好,需要搭配 CI/CD 来使用。
Webpack vs Vite
Webpack 的优势是插件丰富,打包产物兼容性好,页面打开快速,但开发模式启动慢、极慢,而 Vite 恰恰切中了这个痛点,开发模式启动快、飞快。
最近,我们做到了 Webpack 和 Vite 混合的模式,使用了两者的优点。
开发环境使用 Vite 快速调试,生产环境依旧使用 Webpack 打包出稳定兼容性好的产物。
风险是开发和生产编译产物不一致,这一块需要上线前回归测试避免。
4. 性能优化
对于数据类产品而言,性能的挑战除了来自于 Monorepo 后构建产物的变大,还有大数据量对渲染计算带来的挑战。
性能优化可以分为3个环节:
另外还有性能检测工具,定位性能卡点。计划做代码性能门闩,代码提交前如果发现包体积增大发出提醒。
5. 数据化驱动架构优化
身在数据中台,我对数据的业务价值深信不疑。但对于开发本身而言,很少深度使用过数据。
所以 S1 重点探索了开发体验的数字化。通过采集大家的开发环境和启动耗时数据来做分析【不统计其他数据避免内卷】。发现很多有意思的事情,比如有个同学热编译 3~5 分钟,他以为别人也是这样慢,严重影响了开发效率,当从报表发现数据异常后十分钟帮他解决。
另外一个例子,为了保持线上打包产物的一致性,推动团队做 Node.js 版本统一,以前都是靠钉,钉多少次都无法知道效果如何。有了报表以后就一目了然。
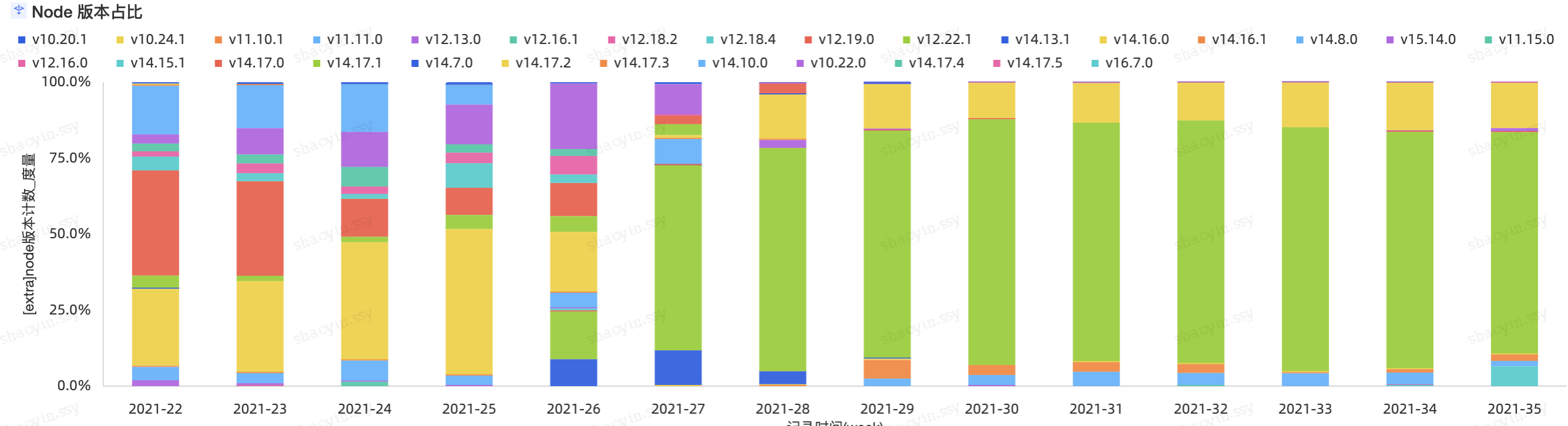
目前整个数据化的流程跑通,初步尝到甜头。未来还有很多好玩的分析可以做。
更深层的经验
效率最高的方式就是一次最好
每行代码都会留下成本。长远考虑,效率最高的方法就是一次做好。
苏世民说“做大事和做小事的难度是一样的。 两者都会消耗你的时间和精力”。既然如此,不妨把代码一次写好。代码中如果遗留 “TODO” 可能就永远 TO DO。客观来讲,一次做好比较难,首先是每个人认为的“好”标准不同,背后是个人的技术能力、体验的追求、业务的理解。
组织文化技术 相辅相成
技术架构和组织结构有很大关系,选择适合组织的技术架构更重要。
如果一个组织是分散的,使用 Monorepo 会有很大的协同成本。组织如果是内聚的,Monorepo 用好能极大提效。
工程化和架构底座是团队的事情,靠个人很难去推动。
短期可以靠战役靠照搬,长期要形成文化才能持续迭代。
组织沟通成本高应该通过组织来解,通过技术来解的力量是渺小的。技术可以做的是充分发挥工具的优势,让变化快速发生。
简单不先于复杂,而是在复杂之后
这是借用Alan Perlis的一句话。
对于一个简单的架构,总会有人会想办法把它做复杂。踩了坑,下决心重构,成功则回归简单,失败就会被新的简单模式颠覆。架构就是这样不断的在做复杂和做简单中交替着螺旋式演进。
踩坑本身也是有价值的,不然新人总是按捺不住还会再踩一次。做复杂很容易,但保持简单需要远见和克制。没有经历过过程的磨练,别人的解药对你可能是毒药。
架构不会一成不变,Quick BI 的图表最开始直接使用 D3、ECharts 简单快速,后来非常多定制化的功能逐渐复杂到难以扩展,于是基于 G2 自研 bi-charts 后架构又一次变简单,每一次重构都是对架构中各个元素的重新思考和整合,能够以更简单高效的方式支持业务。
总结与展望
百万行代码没什么可怕,是一个正常的节点,仍然可以像几万行代码那样敏捷。
现在 Quick BI 已经向千万行迈进,向世界一流 BI 的目标迈进。需要考虑研发效率、质量管控、组织协同、工程化、体验性能多方面的优化。以上内容限于篇幅。BI 数据分析业务开发涉及的技术挑战非常多,因为数据分析天生就要与海量数据打交道,在大数据量渲染和导出上我们在不断的探索;洞察丰富异样的数据,可视化及复杂表格方面有极其多样的需求,可视化能力不仅是技术,还变成业务本身;手机平板电视等多端展示,跨端适配需要融入到每个功能点。未来还希望能够把数据分析打造成一个引擎,能够快速集成到技术产品和商业流程中。
目前的开发模式并不完美,你有任何方面的建议,欢迎交流。
The text was updated successfully, but these errors were encountered: