Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
fix(share/eds): add custom inverted index for badger as storage backe…
…nd (#2053) This PR closes #2045, more specifically it closes #2057 . It introduces a custom inverted index plugin for the dagstore that is more compatible with our usage of badger as a storage backend, as well as more compatible with our usecase (we only need to index one shard per multihash). The issue with the previous implementation was that many keys were being updated very often. This is probably due to padding, but there is more investigation necessary to determine why we have so many CIDs that appear in a lot of shards. Because we use badger as a storage backend, these updates were filling the value log, duplicating the value and adding an extra shard key every time. This resulted in explosive data usage on blockspacerace. At the time of writing, without this fix, the size of the store balloons past 40gb (even more depending on how lucky you are with garbage collection), even though the size of the underlying data is ~4gb and almost all header storage. GC was effective in cleaning up the value log to a point, until they were cleaned to a point where they no longer pass the GC ratio of new to old data (20% is the default from go-badger-ds). This means that the old update logs would just accumulate and not be cleaned further once they are old enough. In this graph, the lines including the fix finished syncing much earlier (unrelated issue), but you can see the data usage stays low and increases monotonically. Without the fix, you can see the explosion of data and the effects of garbage collection. You can also see the size of the /blocks/ storage is not much in comparison to the /data/. This gives us more time to refine the approach in #2038. 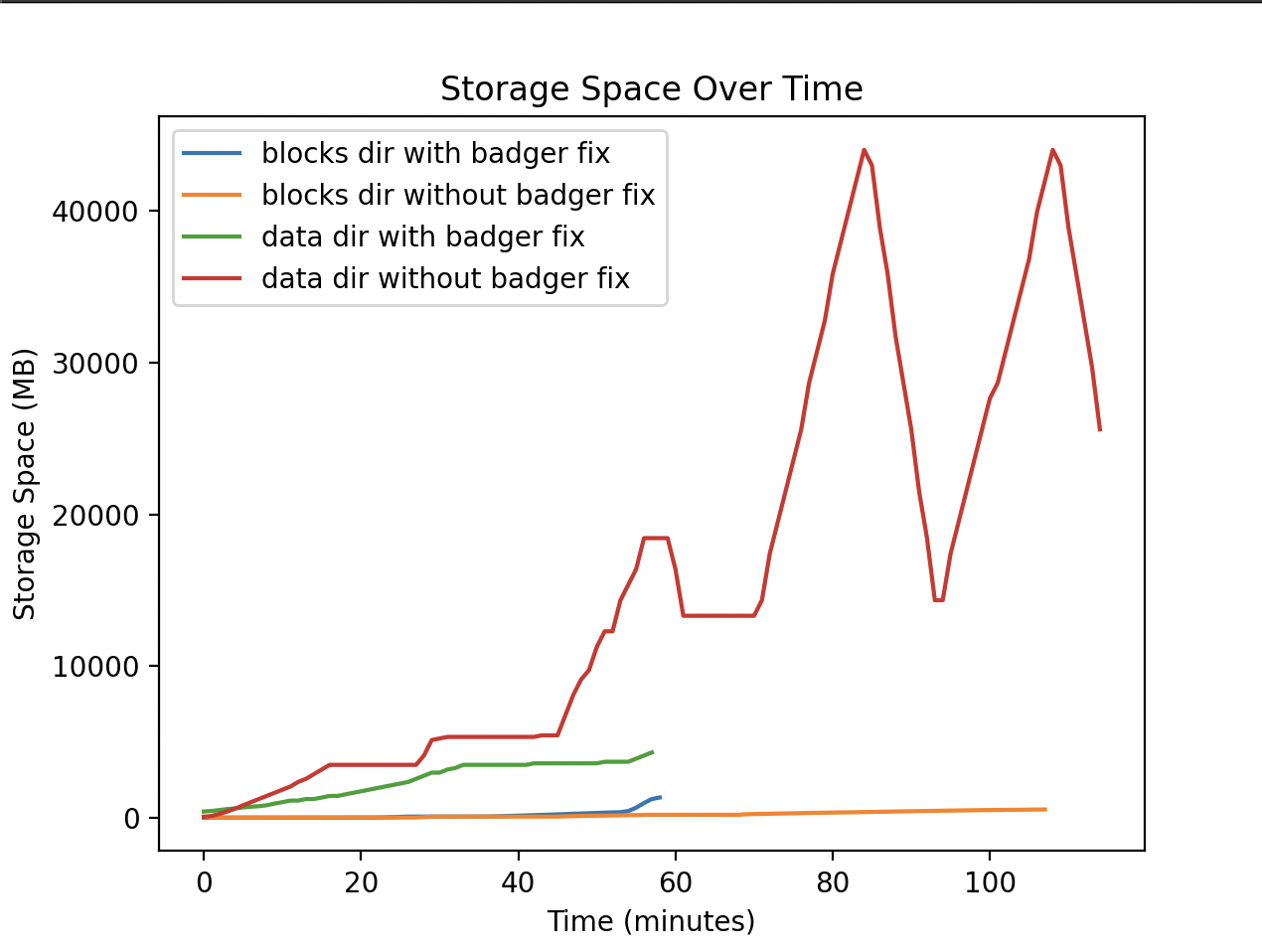 Upon investigation of which CIDs are being stored in multiple shards, we see that the overwhelming majority only point to a single shard. (The value is an array of shard keys)  By removing the first two buckets, we can see there are still a significant amount of CIDs shared between multiple shards. A lot of these CIDs probably just represent blocks that make up padding, but further investigation is needed to see why there are so many. 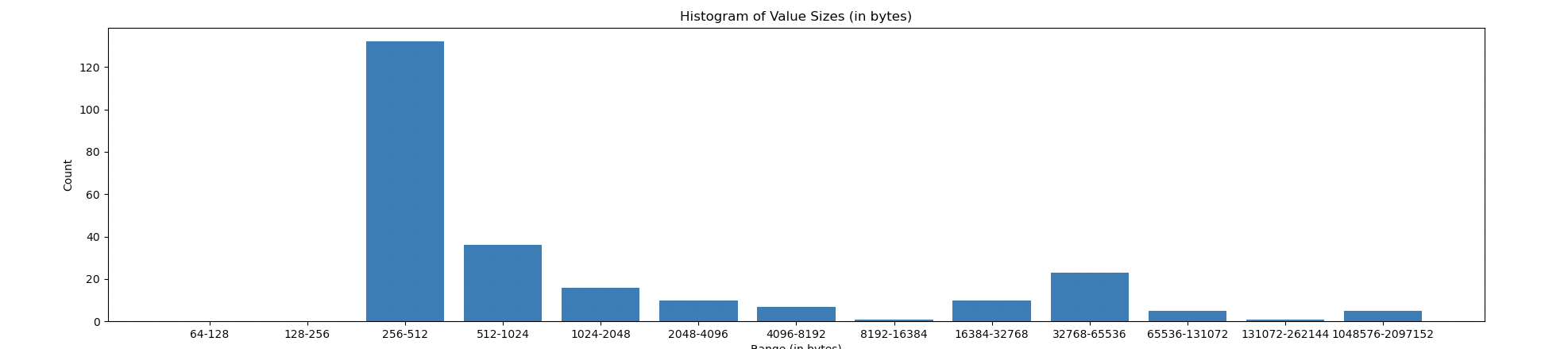 --------- Co-authored-by: rene <41963722+renaynay@users.noreply.github.com>
{kind=link}
{kind=link}
{kind=link}
- Loading branch information
1 parent
e264069
commit 24ea082