Nats outage due to "TLS handshake error: remote error: tls: bad certificate" errors #25
Comments
|
Hey @stefanlay, @jrussett and I are reviewing this issue together today. Here are some of our initial thoughts and questions:
Both versions of cf-deployment use the same version of nats-release (v34). And both enable nats-tls by default. ❓ Which version of cf-deployment and nats-release were you using before your recent upgrades? Was nats-tls enabled before your upgrade 2 weeks ago?
❓ Is that one per AZ? Do you have two availability zones?
🤔 Here's one hypothesis that may explain why one VM is getting all the traffic: When a NATS VM (let's call it
Perhaps rolling the diego cells and gorouters will rebalance the load. Or, you could restart the route-emitter jobs on each cell and/or gorouter jobs on each router.
It's hard to say which is cause and effect here. In the other log file you attached we also saw many There was another recent issue where network latency turned out to the root cause, but that resulted in "Authorization Violation" errors and some increased CPU load. Perhaps something similar is going on here. |
|
Hi, thanks for the quick reply!
We upgraded from cf-deployment v12.45.0 which uses nats v34 as well but does not seem to enable nats-tls.
Yes, CF is deployed in 2 AZs, 1 nats per AZ Here is also the config - |
|
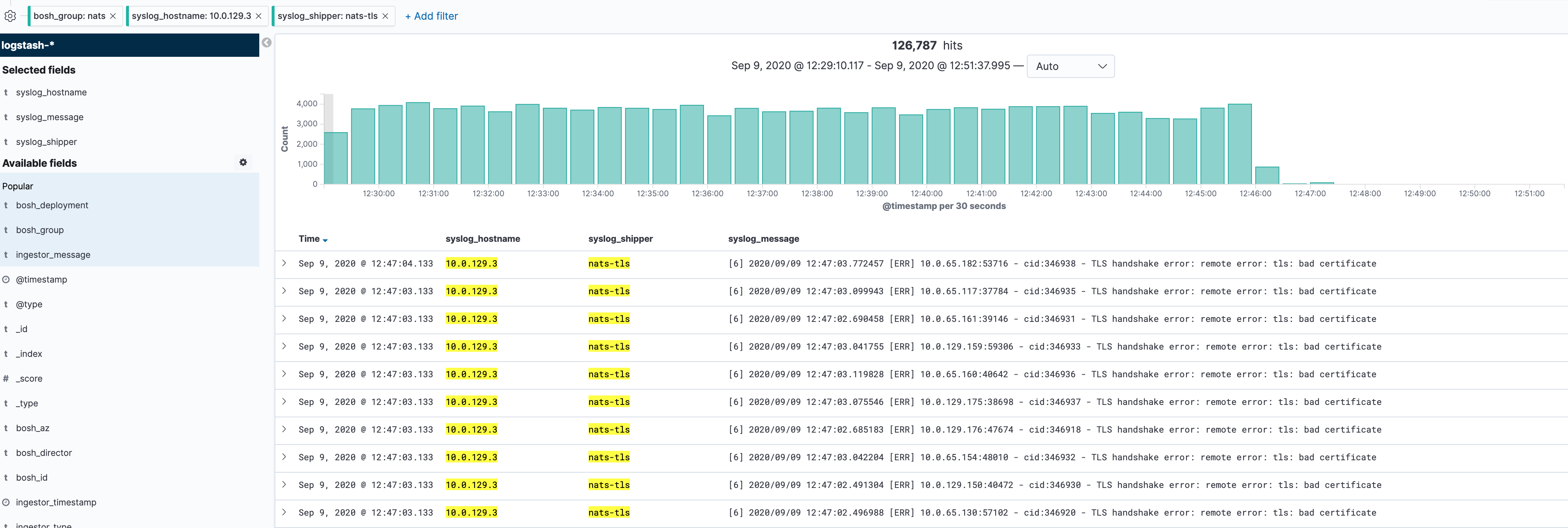
Hi @mcwumbly, also from me many thanks for your quick reply! We have looked more in depth into the logs. We checked how the issue started. On both NATS VMs the errors "TLS handshake error: remote error: tls: bad certificate" started at around the same time and increased in number similarly at 11:44:05: We do not see any other logs on the NATS VMs which may indicate a root cause. At the same time we see an increase in CPU on both NATS VMs: So we think that the increase in CPU is caused by the TLS issues. On diego we see errors in route-emitter only later: We are not very familiar with the message flow in CF NATS. We wonder if the connections where the NATS VMs report TLS issues are opened by the NATS VMs. We thought that the route-emitter calls NATS as a message bus, and not vice versa. Why do we then only see such errors on the NATS VM, but not on the diego cells? What puzzles us even more is that at the time we restarted the VM on zone 1 (10.0.65.3) the error message also vanished on the other VM: Exact times from BOSH log: Logs from stopped VM: Logs from the other VM: Why are the TLS errors gone on the VM which was not touched by us? We would be very happy if you could give us some ideas where we can look into to analyse this issue further. |




|
Here, for completeness also the config for nats-tls
|
Here are the main interactions with NATS within CF:
Since the TLS connectivity is between the two NATS VMs, and there are only two of them in your current deployment, when you take one down, the other has not TLS connections to establish. Regarding this error specifically: It looks like it's either coming from github.com/nats-io/nats-server/server/leafnode.go or github.com/nats-io/nats-server/server/server.go, and then further down, from within the go standard library, either in github.com/golang/go/src/crypto/tls/handshake_server.go or in a handful of places in github.com/golang/go/src/crypto/tls/handshake_client.go Not sure why the certificate would become "bad". If you see this issue again, I might do the following:
|
We could confirm that in our case the router.register go over the unencrypted port 4222 opened by the nats job. If the traffic goes via the 4222 port, what are these connections used for? They seem not to have a lot of traffic. But establishing these connections leads to the errors we see. We also wonder why in https://github.com/cloudfoundry/cf-deployment/releases/tag/v13.5.0 there is the statement "Enables TLS between route-emitter and NATS."
We now think that the certificate itself is not an issue. We see missing registry update already before the first TLS handshake error occurs. We think that the error "TLS handshake error: remote error: tls: bad certificate" also comes when the handshake is cancelled due to e.g. timeout. Cf deployment sets the timeout: 5 # seconds. In our logs wee see that for a given diego cell the error is logged very regularly every 6 or 7 seconds, which may fit to a retry logic after 1 second: We made an observation which let us assume that the initial issue started already earlier. About two minutes before the routes went down to zero, routes were pruned, but one group of gorouters had a different number of routes than the other group: It looks like both NATS instances have different numbers, that means they can't exchange router.register message anymore. If that is the case, how could such an issue lead to the complete loss of routes later? We did not observe network issues on other VMs, why should two NATS VMs in two AZs have network issues at the same time. |


Huh, whelp, you're right. Looks like cf-d uses tls between route-emitter and NATS.
Now I'm curious how many VMs you see this error for. In the screenshot, it looks like a single Diego Cell and a single NATS VM, but that's probably just because you're filtering things down to understanding timing. During that time, do you see the error from other Diego Cells as well? Do all the Diego Cells have an issue with a single NATS VM? Or do some of them have the same issue with the other NATS VM? |
We are using cf-deployment, but nevertheless we observe that the router.register messages go over the unencrypted port 4222 opened by the nats job. We see it with tcpdump. These are our job definitions in the manifests:
This screenshot was filtered for one NATS VM and one diego cell. in the end we see errors for all cells. We have 451 cells, and for each cell we see a log entry around each 6s, leading to a picture like this for one NATS VM, on the other it looks the same (Note that all the errors are logged each second): |

|
We found some indication that the TLS issue is not the root cause but an effect of an unhealthy cluster. We found log messages telling that one NATS VM on port 4223 which is used for updating the other instance about new messages is considered as being a "slow consumer" by the other NATS VM: Nearly 2 Minutes after the first of such log entry the gorouters start pruning some routes, see https://user-images.githubusercontent.com/358527/92950779-8b094d80-f45d-11ea-85a0-b95156f42a91.png Then, after some time, suddenly all routes are dropped, and then only later, the certificate errors occur for the connections attempts. on port 4224. Btw., we also saw that during a bosh update there are the same error messages "TLS handshake error: remote error: tls: bad certificate" when the NATS job is stopped on another NATS VM, and that this error message is not logged on the diego side. We now have some questions: Do you think that such communication issue between the two NATS instances can lead to such a complete loss of routes and such certificate errors? What would be the best recommendation to analyse such slow consumer issues? Would it be sufficient to scale out to bigger VMs with more network bandwidth? Would you also recommend to scale out to more than two VMs? |
|
Hello from the NATS team 👋 . I'd like to gather some more info on the current setup if possible, I notice that in the release the old version of the NATS Server is being used: nats-release/packages/gnatsd/packaging Line 14 in b2b5717 But is the version of the NATS Server still v1? Or is latest NATS Server v2 being used? I'm saying this because the Slow Consumer behavior between routes would be improved in NATS Server v2 series in some scenarios, specially when there is a very large number of subscriptions. |
|
Hi @stefanlay & @wallyqs, I'm looking into this issue today with @mcwumbly. We've reviewed this discussion, along with the discussion over at nats-io/nats-server#1597. First, we have a few responses to a few of the questions we've seen.
A: We now suspect this is due to additional overhead required by all of the connections being made to NATS which are now using TLS. Notably the 450+ diego cells and that CF-Deployment turns on TLS between the
A: We're happy that you opened the other issue on NATS.io, as it sounds like they have had some good insights to what you're seeing. We will subscribe to that issue as well.
A: We think that scaling up the size of the NATS VMs or scaling out the number of instances of the NATS VMs could both be beneficial in this case. With more instances the load from the TLS connections should be distributed better, and reduce the overhead on each VM overall as the distribution is now greater. With bigger VMs that have more CPU available to them, and perhaps faster Disk & RAM it could also help with what @kozlovic said in the NATS.io issue.
A: @wallyqs as you discovered above, the version of NATS is still v1, specifically v1.4.1. We hear your recommendations clearly and we have created an issue to track that here: #26 @stefanlay we think it is worth exploring ways to resolve this issue independently of the upgrade of NATS v2 as that could take some time to accomplish. One approach as you suggested is to scale up the NATS VMs. Another thing to consider may be to use an ops file to turn off TLS between the |
|
@stefanlay @plowin Could you please describe the steps that were taken to solve the problem? At the moment my team is using the cf-deployment version prior to nats-tls has been introduced and we are trying to understand what could be the impact of upgrading our installtion. The total amount of active routes is not as numerous as in your case (we have ~5k active routes), but we are still concerned about the problem described above. |
|
Hi all, We saw another instance of a bug that looked remarkably like this yesterday. The problem that we saw yesterday:
Something new I learned:
Another thought: ❓ @stefanlay can you confirm what version of routing-release you have deployed? |
|
Hi @Infra-Red, we tried to reproduce the scenario and have strong indication that the slow consumer issue between the two NATS nodes were causing the outage. As a mitigation of the slow consumer issue we increased the NATS VM size, and therefore also other parameters like network bandwidth. Within last month we only saw two slow consumer errors between NATS nodes which were gone after the route connections were recreated. We are still investigating which metrics we can use to better predict a slow consumer issue. Due to our observation, NATS CPU load is not a good metric. Hi @ameowlia We also see that the the metrics-discovery-registrar job uses nats-tls, and the tls errors may also come from these connections when CPU load was 100%. We have however another explanation why in our case the CPU load was increasing: We now understood is that due to a bug in diego the route emitters could not use TLS I do not understand the purpose of the gorouter config property that allowed users to turn on TTL based pruning for stale routes. To our understanding, gorouter prunes all stale routes after 120s (https://github.com/cloudfoundry/routing-release/blob/abd514ad8b78886dd2487309dd19c5fc1c92cf4b/jobs/gorouter/templates/gorouter.yml.erb#L83). When did this property have effect? Note that we do not use route integrity/backend tls router.backends.enable_tls: false. You mentioned that you have turned pruning off in your case. How did you do that? With suspend_pruning_if_nats_unavailable? We were on cf-deployment 13.12.0 but already used routing release 0.206.0 because of cloudfoundry/routing-release#178 Now we are on cf-deployment 13.17.0 and routing release 0.206.0. |
* When advertising is on, clients that are incompatible with nats-tls job will try to connect to nats-tls if nats is unavailable * Clients wanting to connect via TLS get downgraded when connecting to nats if nats-tls is unavailable [#25](#25) [cloudfoundry/routing-release#185](cloudfoundry/routing-release#185)
|
@stefanlay - I agree with your analysis about why the CPU is increasing. This is consistent with issue I encountered as well. 🌹 Re: Gorouter and pruning
🐛 What to do to mitigate this bug
📈 Fixing Bug Status
|
* currently some clients in CF are not configured to properly use nats-tls and rely on being able to downgrade to nats. * we are keeping this ability to downgrade to nats for backwards compatability. * we plan removing the ability to downgrade to nats once we fix all the clients [#25](#25) [cloudfoundry/routing-release#185](cloudfoundry/routing-release#185)
* When advertising is on, clients that are incompatible with nats-tls job will try to connect to nats-tls if nats is unavailable * Clients wanting to connect via TLS get downgraded when connecting to nats if nats-tls is unavailable [cloudfoundry#25](cloudfoundry#25) [cloudfoundry/routing-release#185](cloudfoundry/routing-release#185)
|
Hi @ameowlia, thanks for the analysis and efforts on this issue!
Could you please help me understand how route-integrity and the mass pruning are related? In our case, NATS did not provide updates to the routers and after 120s the routes got pruned. We did not assume route-integrity or diego having an impact here? |
|
@plowin Since TLS ensures you never accidentally talk to the wrong endpoint, you no longer need TTL-based pruning. You just check the cert issuer and subject. If they match you route forward, if they don't you need to update your route table because the app has moved somewhere else. Just tested it myself, deployed with route-integrity and stopped NATS. Never got pruned. So this would protect us against a NATS outage as well as misrouting. @ameowlia Do you have any insights into the cf ssh vs. route integrity thing? |
|
Hi @plowin,
When route integrity is enabled this means that gorouter is sending traffic to apps over TLS. The sidecar envoy presents the app's certificate to the gorouter during this handshake. The certificate contains the app's instance guid. The gorouter no only checks that the cert is valid, but it also checks to make sure that the app instance guid in the cert matches the app instance guid that it expects to be talking to. Essentially, this is checking to make sure that the route is not stale. If the guids don't match, then the gorouter assumes this is a stale route and prunes it from its routing table and then retries another entry. This action is logged as something like "pruned-failed-backend-endpoint" Because we now rely on route-integrity to know if a route is stale, we turned on pruning on a TTL for TLS routes. 😅 @domdom82 you replied 1 minute before me! |
What I have always heard/read in docs: Long Answer: When mtls route integrity is turned on only 2 of those ports are exposed: the DIEGO_CELL_ENVOY_PORT and CONTAINER_ENVOY_SSH_PORT. I'm not sure if the ssh agent can be configured to connect with the CONTAINER_ENVOY_SSH_PORT. Or maybe it already does and but the user need to configure something special? |
|
@ameowlia hmm this is weird. This is what my app looks like on cfdot: So far so good. Here is my diego-cell config of cf-deployment: So to me this looks like mTLS should be enabled, right? ( I also took a tcpdump when I connected the ssh session: So the ssh-proxy does connect to the envoy listener on port 61002 and there is a mTLS handshake happening (both parties present a certificate, see packet nr 46). After that there is regular application data going over the wire. (I could log in, got a shell, did some echo hello etc.) Here is a So there is the envoy running, my node app and the diego-sshd that forked off my shell. Here is a list of connections on the app container: The connection between ssh-proxy and my container on port 61002 can be seen. Not sure about the local connection on port 2222. I guess this is ssh being forwarded by envoy to the sshd? But it all looks like it is working just fine. |
|
@domdom82 maybe it has been fixed 🤷 If you want to talk about sshing with mtls further, lets move the conversation elsewhere. Related to the original issue @stefanlay, this has been fixed in versions v35 -> v38. It took many releases to get it just right 😅 . This release will become available in cf-deployment very soon. I am going to consider this fixed. @stefanlay, if you find that this does not fix your issue then please reopen. |
|
Thanks @ameowlia ! I have opened a docs issue for the cf-ssh thing in lieu of a better place. |
|
Hi @ameowlia, thanks for all your input, that helps a lot. I have a question about your fixes to NATS (cloudfoundry/routing-release#185 (comment)). With v37 nats.no_advertise is switched on for the nats job but switched off for the nats-tls job. What will happen to the connections from the route-emitters when the nats vms are updated? Assume we have two nats vms, NATS1 and NATS2. In the route-emitter configuration nats is configured with "nats.service.cf.internal:4224". The nats-docu is inconsistent in what will happen: in [1] (docu for the config option) it states "When set to true, do not advertise this server to clients." in [2] (docu for the command line flag) it however states: "Do not advertise known cluster information to clients" What is the actual behaviour? I also think that switching off advertising for the nats-tls jobs makes sense because currently reconnecting to an advertised nats-tls would not work, as the nats nodes are advertised with their IP addresses, but the certificate contains the DNS name. So already now the route-emitter would fall back to the nats job on port 4222. I think the TLS issues we had were not caused by route-emitters or other clients not using tls like you mentioned in #25 (comment), but by a bug which was fixed by cloudfoundry/diego-release@44260f2 On the other hand, when the diego-VMs are updated after NATS, the route-emitters will again connect on 4224, so in that case that's ok. In general, i think we still haven't found the root cause of all the issues, as the TLS errors only came later after all routes were dropped (#25 (comment)). But we now have improved our nats monitoring in order to better predict slow consumer issues, so we are ok with having this ticket closed. [1] https://docs.nats.io/nats-server/configuration/clustering/cluster_config |
|
Hi @stefanlay , you are correct. Clients of nats-tls may fall back to nats when the default values in the release. This is in the release notes as:
If all of your nats-tls clients can successfully connect to nats-tls, then you can turn on |
We are using cf-deployment v13.8.0 since Aug 13 and v13.12.0 since two weeks.
On two different installations of cf we had severe issues with NATS.
The most recent one at Sep 9, 2020 led to a complete loss of all gorouter routes.
We use two NAT VMs in our deployment
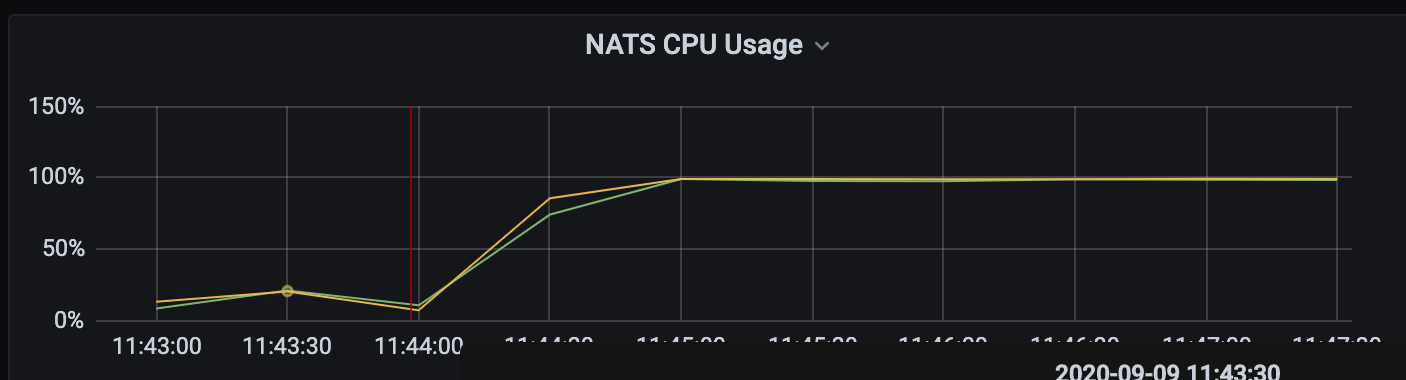
At the same time both NATS cpu's went up to nearly 100%. The gorouter pruned all routes. The nats logs show many errors "TLS handshake error: remote error: tls: bad certificate" for different target server, see
nats_bad_certificate_eu10.txt
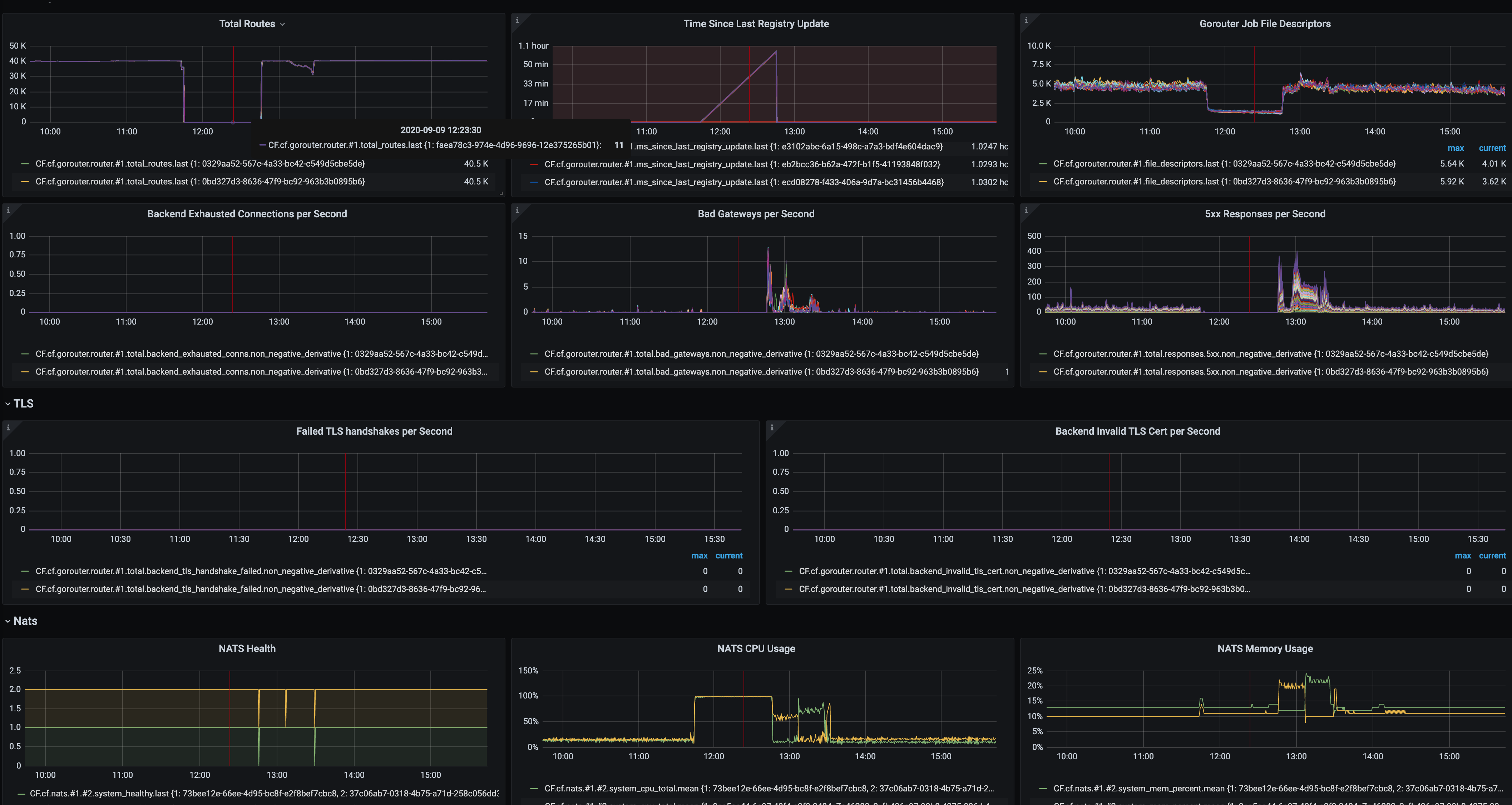
The situation did not change until we restarted one VM. Then the routes recovered. When the restarted the other VM, the routes went down again. Then we restarted the first one again, and the metrics looked ok, see
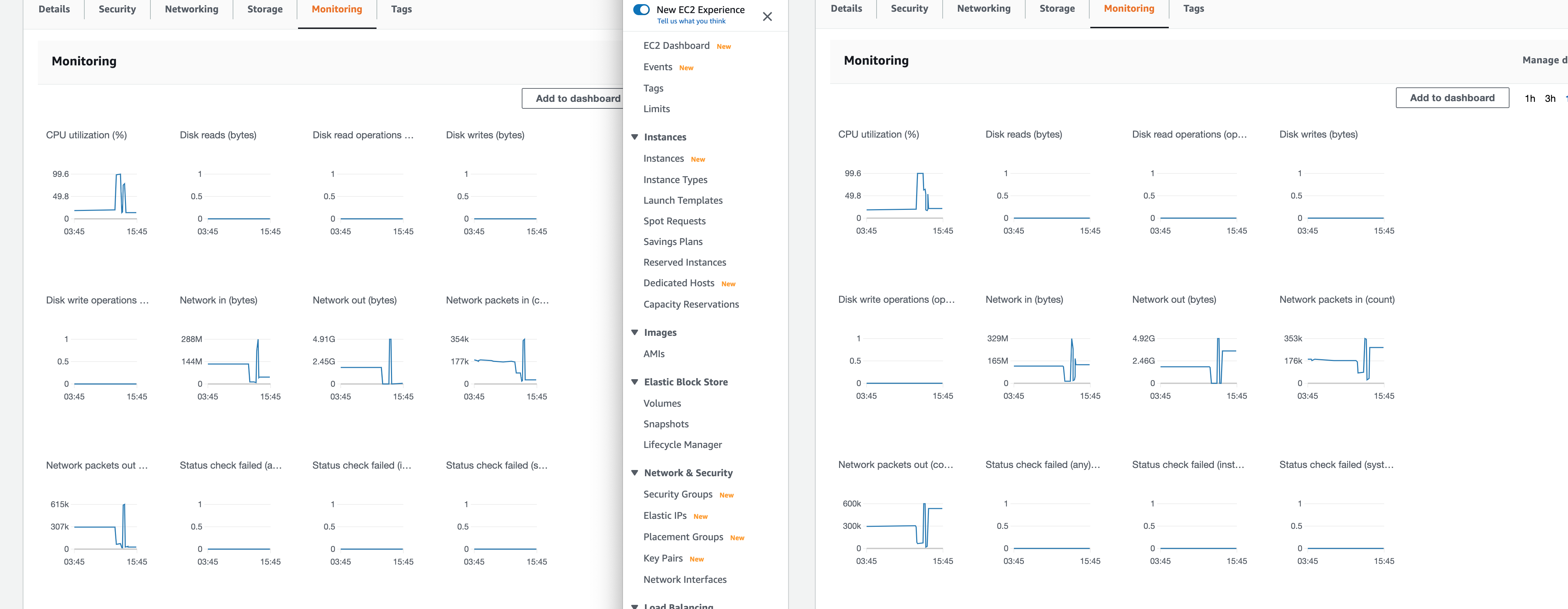
But still we see that one VM is not fully functional. On AWS dashboard we see that network traffic mainly goes via one VM:
The other issue happened at Sept 4, 2020
Here only the CPU of one NATS VM went up, but only to 30%. About 35% of the routes were pruned by the gorouter. Nats recovers after about 3 minute. But it seems that the instance where the CPU spiked does not have much network traffic as we see on the AWS console and on the VM itself using netstat and tcpdump.
The errors on the NATS VMs were different at the beginning compared to the issue above. It started with "TLS handshake error" from bosh-dns and "Slow Consumer" from nats, both only on 10.0.65.3.
About 4 seconds later (Sep 4, 2020 @ 07:07:58.250) errors like that started on both VMs 10.0.129.3 nats-tls [6] 2020/09/04 07:07:57.937454 [ERR] 10.0.73.85:40008 - cid:581 - TLS handshake error: remote error: tls: bad certificate
See
nats.txt.
We would like to understand:
The text was updated successfully, but these errors were encountered: