Releases: cloudposse/terraform-aws-eks-node-group
v2.12.0
Add `force_update_version` and `replace_node_group_on_version_update` variables @aknysh (#151)
what
- Add
force_update_versionandreplace_node_group_on_version_updatevariables
why
-
force_update_versionallows forcing version update if existing pods are unable to be drained due to a pod disruption budget issue. Default isfalsefor backwards compatibility -
If the variable
replace_node_group_on_version_updateis set totrueand the EKS cluster is updated to a new Kubernetes version, the Node Groups will be replaced instead of updated in-place. This is useful when updating very old EKS clusters to a new Kubernetes version where some old releases prevent nodes from being drained (due to PodDisruptionBudget or taint/toleration issues), but replacing the Node Groups works without forcing the pods to leave the old nodes by using theforce_update_versionvariable. This is related, for example, toistio. Default isfalsefor backwards compatibility
references
Contributors
Assets 2
v2.11.0
Better block device support @Nuru (#150)
Notable Changes
- With this PR/release, the default type of block device changes from
gp2togp3. If you were relying on the default, this will cause your node group to change, but it should be without interruption. - We no longer automatically apply a custom taint to Window nodes. Pods should select (or not) Windows nodes via the
kubernetes.io/ostag. If that is not sufficient, you are free to add your own "NO_EXECUTE" taint viakubernetes_taints
what
- Better support for block device mapping
- Update dependency
terraform-aws-security-groupto current v2.2.0 - Revert portions of #139
why
- Take advantage of
optional()to allow the block device mapping input to be fully specified, with defaults, rather than the previouslist(any), which had no type checking and did not advertise which features were or were not supported - Closes #134
- Bad practices that were not caught in time
add core_count and threads_per_core options to launch templates @Dmitry1987 (#149)
what
added core_count and threads_per_core options in order to run instances with no hyperthreading, for applications that need maximize single core performance (in some cases it's required).
why
the config option is available in the module but was not available in variables
references
Support AWS Provider V5 @max-lobur (#147)
what
Support AWS Provider V5
Linter fixes
why
Maintenance
references
https://github.com/hashicorp/terraform-provider-aws/releases/tag/v5.0.0
Do not sort instance types @xeivieni (#142)
what
Remove sorting on instance type list in the node group definition
why
Because the order of the list is used to define priorities on the type of instance to use.
references
Managed node groups use the order of instance types passed in the API to determine which instance type to use first when fulfilling On-Demand capacity. For example, you might specify three instance types in the following order: c5.large, c4.large, and c3.large. When your On-Demand Instances are launched, the managed node group fulfills On-Demand capacity by starting with c5.large, then c4.large, and then c3.large
Sync github @max-lobur (#145)
Rebuild github dir from the template
🤖 Automatic Updates
Update README.md and docs @cloudpossebot (#148)
what
This is an auto-generated PR that updates the README.md and docs
why
To have most recent changes of README.md and doc from origin templates
Contributors
Assets 2
v2.10.0
- No changes
v2.9.1
Use cloudposse/template for arm support @nitrocode (#129)
what
- Use cloudposse/template for arm support
why
- The new cloudposse/template provider has a darwin arm binary for M1 laptops
references
🚀 Enhancements
fix: variable description for var.bootstrap_additional_options @venkatamutyala (#144)
what
- Fixing variable description as it references another variable that doesn't exist.
why
Should save someone time in the future when they try and find the variable as mentioned in the description.
Contributors
Assets 2
v2.9.0
Groundwork new workflows @max-lobur (#143)
Fix lint/format before workflows rollout
Contributors
Assets 2
v2.8.0
Windows node support @ChrisMcKee (#139)
what
- Adds support for 2019/2022 (windows lts) ami-types as per the aws sdk docs
- Docs to support usage and link to ref docs https://docs.aws.amazon.com/eks/latest/userguide/windows-support.html
why
- Windows EKS Managed node support aws/containers-roadmap#584
references
- https://docs.aws.amazon.com/eks/latest/userguide/windows-support.html
- https://docs.aws.amazon.com/eks/latest/userguide/eks-ami-versions-windows.html
Tested
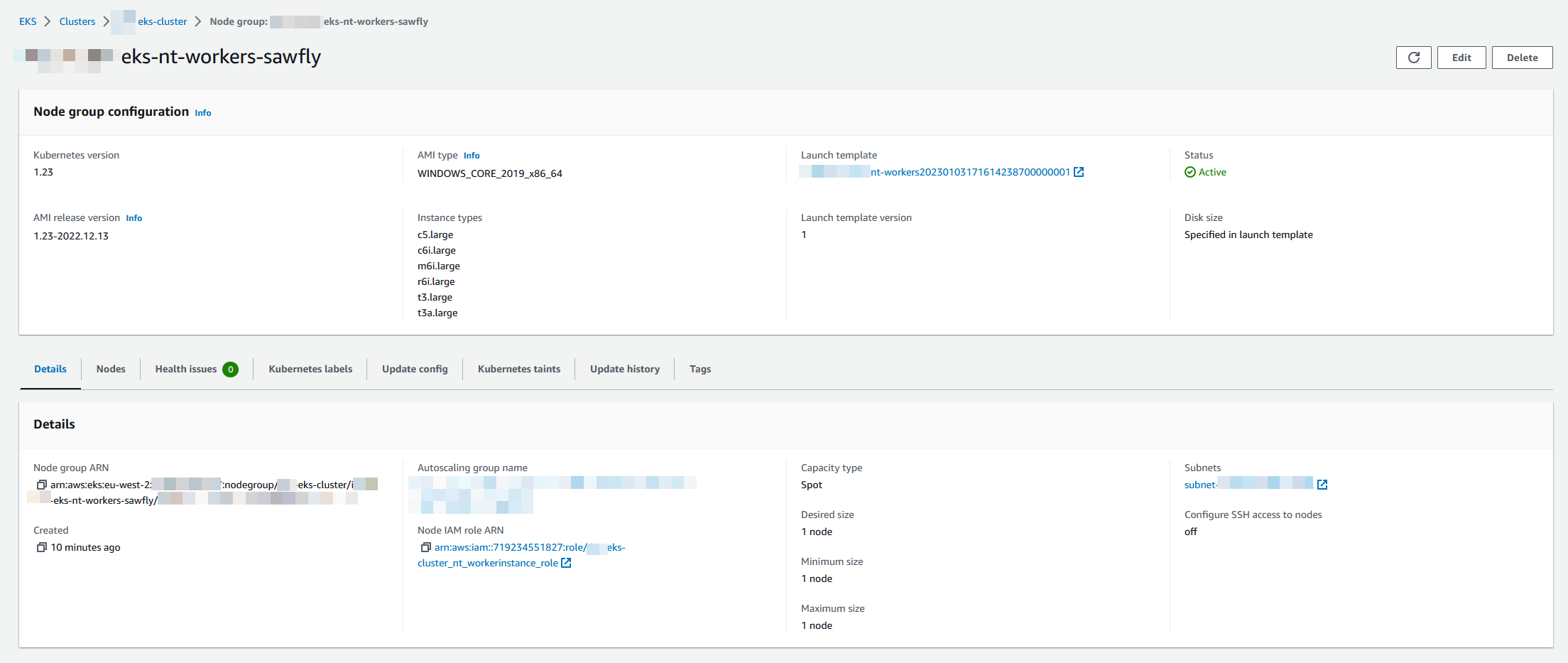



module "eks_windows_node_group" {
# source = "cloudposse/eks-node-group/aws"
# version = "2.6.1"
source = "github.com/ChrisMcKee/terraform-aws-eks-node-group"
instance_types = ["t3.large", "t3a.large", "c5.large", "c6i.large", "m6i.large", "r6i.large"]
subnet_ids = [data.terraform_remote_state.network.outputs.private_subnets[1]]
min_size = 1
max_size = 1
desired_size = 1
cluster_name = module.eks_cluster.eks_cluster_id
kubernetes_version = var.kubernetes_version == null || var.kubernetes_version == "" ? [] : [var.kubernetes_version]
kubernetes_labels = var.labels
ami_type = "WINDOWS_CORE_2019_x86_64"
update_config = [{ max_unavailable = 1 }]
capacity_type = "SPOT"
kubernetes_taints = [{
key = "OS"
value = "Windows"
effect = "NO_SCHEDULE"
}]
node_role_arn = [aws_iam_role.worker_role_nt.arn]
node_role_cni_policy_enabled = false #We use the Service Account as per best practice
associated_security_group_ids = [data.terraform_remote_state.network.outputs.ops_ssh, aws_security_group.workers.id]
# Enable the Kubernetes cluster auto-scaler to find the auto-scaling group
cluster_autoscaler_enabled = true
context = module.windowslabel.context
# Ensure the cluster is fully created before trying to add the node group
module_depends_on = [module.eks_cluster.kubernetes_config_map_id]
# Ensure ordering of resource creation to eliminate the race conditions when applying the Kubernetes Auth ConfigMap.
# Do not create Node Group before the EKS cluster is created and the `aws-auth` Kubernetes ConfigMap is applied.
depends_on = [module.eks_cluster, module.eks_cluster.kubernetes_config_map_id]
create_before_destroy = true
node_role_policy_arns = ["arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCore"]
block_device_mappings = [
{
"delete_on_termination" : true,
"device_name" : "/dev/xvda",
"encrypted" : true,
"volume_size" : 80,
"volume_type" : "gp3"
}
]
node_group_terraform_timeouts = [{
create = "40m"
update = null
delete = "20m"
}]
#Valid types are "instance", "volume", "elastic-gpu", "spot-instances-request", "network-interface".
resources_to_tag = ["instance", "volume", "spot-instances-request", "network-interface"]
}related
Contributors
Assets 2
v2.7.0
Conditionnaly disable default eks security group @xeivieni (#141)
what
Adds the possibility to remove association of the default eks security groups to the launch template
why
- The default security group contains very wide rules (all ports inbound on itself)
- Using the module it gets associated to all nodes by default
- In some cases users may need to explicitly whitelist part of the traffic instead of allowing everything
references
Contributors
Assets 2
v2.6.2
🚀 Enhancements
Prevent unexpected privileges escalation @gillg (#136)
what
The current variable input_metadata_http_put_response_hop_limit condition, prevent to protect users of this module, to be protected against privileges escalation.
The first intent of IMDSv2 is to prevent containers beeing able to assume an EC2 instance profile. It's not a bad idea at all to prevent that. The good practice then is to use the module cloudposse/eks-iam-role/aws to create a kubernetes service account mapped with IAM permissions throug an OIDC IdP.
references
Contributors
Assets 2
v2.6.1
🚀 Enhancements
Add instance, volume, network-interface as resource tag defaults @nitrocode (#132)
what
- Add instance, volume, network-interface as resource tag defaults
why
- Reasonable tagging defaults
references
- Closes #131 (comment)
- Other module also contains this as a default
Contributors
Assets 2
v2.6.0
Detailed monitoring @IkePCampbell (#126)
What did I do
- Add detailed monitoring flag to the launch template of EC2 nodes
Why did I do this
- Some compliance tools will flag nodes used by this module because they don't have detailed monitoring. This also allows metrics to be reported every minute as opposed to five minute intervals