1.0.0-alpha.29 New syntax matching approach
A brand new syntax matching
This release brings a brand new syntax matching approach. The syntax matching is important feature that allow CSSTree to provide a meaning of each component in a declaration value, e.g. which component of a declaration value is a color, a length and so on. You can see example of matching result on CSSTree's syntax reference page:

Syntax matching is now based on CSS tokens and uses a state machine approach which fixes all problems it has before (see #67 for the list of issues).
Token-based matching
Previously syntax matching was based on AST nodes. Beside it possible to make syntax matching such way, it has several disadvantages:
- Synchronising of CSS parsing result (AST) and syntax description tree traverses is quite complicated:
- Every tree represents different things: one node type set for CSS parsing result and another one for syntax description tree
- Some AST nodes consist of several tokens and contain children nodes
- Some AST nodes doesn't contain symbols that will be in output on AST translating to string. For instance,
Functionnode contains a function name and a list of children, but it also produce parentheses that isn't store in AST. This introduces many hacks and workarounds. However, it was not enough since approach doesn't work for nodes likeBrackets. Also it forces matching algorithm to know a lot of about node types and their features.
Starting this release, AST (CSS parse result) is converting to a token stream before matching (using CSSTree's generator with a special decorator function). Syntax description tree is also converting into so called Match graph (see details below). Those tree transformations allow to align both tree to work in the same terms – CSS tokens.
This change make matching algorithm much simpler. Now it know nothing about AST structure, hacks and workarounds were removed. Moreover, syntaxes like <line-names> (contains brackets) and <calc()> (contains operators in nested syntaxes) are now can be matched (previously syntax matching failed for them).
Update syntax AST format
Since syntax matching moved from AST nodes to CSS tokens, syntax description tree format was also changed. For instance, functions is now represented as a token sequence. It allows to handle syntaxes that contains a group with several function tokens inside, like this one:
<color-adjuster> =
[red( | green( | blue( | alpha( | a(] ['+' | '-']? [<number> | <percentage>] ) |
[red( | green( | blue( | alpha( | a(] '*' <percentage> ) |
...
Despite that<color-mod()> syntax was recently removed from CSS Color Module Level 4, such syntaxes can appear in future, since valid (even looks odd).
As the result of format changes, all syntaxes in mdn/data can now be parsed, even invalid from the standpoint of CSS Values and Units Module Level 3 spec syntaxes. Due to this, some errors in syntaxes were found and fixed (mdn/data#221, mdn/data#226). Also some suggestions on syntax optimisation were made (mdn/data#223, mdn/data#230).
Introducing Match graph
As mentioned above, syntax tree is now transforming to Match graph. This happens on first match for a syntax and then reused. Match graph represents a graph of simple actions (states) and transitions between them. Some complicated thing, like multipliers, are translating in a set of nodes and edges. You can explore which a match graph is building for any syntax on CSSTree's syntax reference page, e.g. the match graph for <'animation-name'>:
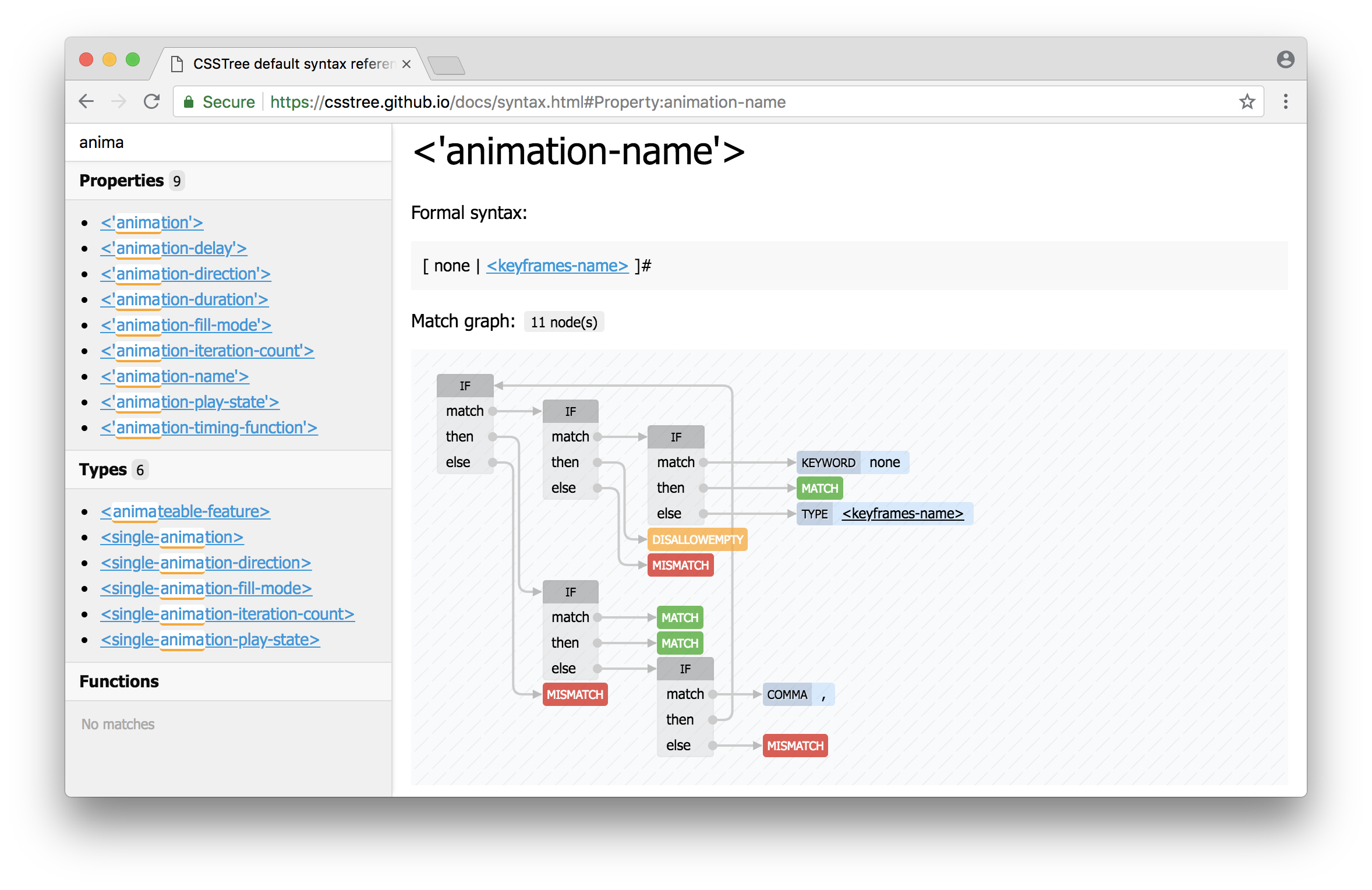
There were some challenges during implementation, most notable of them:
&&-and||-groups. Actually it was a technical blocker that suspended moving to match graph. Finally, a solution was found: split a groups in smaller one by removing a term one by one. For example,a && b && ccan be represented as following (pseudo code):
if match a
then [b && c]
else if match b
then [a && c]
else if match c
then [a && b]
else MISMATCH
So, a size of groups is reducing by one on each step, then we process the smaller groups until a group consists of a single term.
a && b
=
if match a
then if match b
then MATCH
else MISMATCH
else if match b
then if match a
then MATCH
else MISMATCH
else MISMATCH
It works fine, but for small groups only. Since it produces at least N! (factorial) nodes, where N is a number of terms in a group. Hopefully, there are not so many syntaxes that contain a group with a big number of terms for &&- or ||- group. However, font-variant syntax contains a group of 20 terms, that means at least 2,432,902,008,176,640,000 nodes in a graph. It's huge and we can't create such number of object due a memory limit. So, alternative solution for groups greater than 5 terms was introduced, it uses special buffer and iterate terms in a loop. The solution is not ideal, but there are just 9 such groups (with 6 or more terms) across all syntaxes, so it should be ok for now.
- A comma. The task turned out to be a tough nut to crack, because of specific rules. For example, if we have a syntax like that:
a?, b?, c?
We can match a, b, c, a, c, b, b, c and so on. But input like , b, c, a, , c or a, is not allowed. In other words, comma must not be hanged and must not be followed by an another comma. And when comma is matching to an input, it should notify a positive match even there is no a comma token in the input. This was a blocker that could cancel the whole approach.
Nevertheless, the problem was solved in elegant way, by checking adjacent tokens for a several patterns. It most non-trivial part of new syntax matching, several lines of code works well only with along other parts of implementation, so may looks like a magic.
Using state machine
Another improvement in syntax matching is replacing a recursion-based algorithm with a state machine approach. This allowed to check all possible alternatives during the syntax matching. Previously if nothing matched by a chosen path, algorithm just exited with a mismatch result. New algorithm is returning back to a branching point and choose an alternative path when possible. This fixes following:
- Syntaxes with alternative paths, like
<bg-position>.
<bg-position> =
[ left | center | right | top | bottom | <length-percentage> ] |
[ left | center | right | <length-percentage> ] [ top | center | bottom | <length-percentage> ] |
[ center | [ left | right ] <length-percentage>? ] && [ center | [ top | bottom ] <length-percentage>? ]
This syntax didn't work before, since it defines shortest form first and matching fell in this path with no chance to use an alternative path. However, reverse order of groups in this syntax makes it work with old algorithm.
Another example is a new syntax for <rgb()>:
rgb() = rgb( <percentage>{3} [ / <alpha-value> ]? ) |
rgb( <number>{3} [ / <alpha-value> ]? ) |
rgb( <percentage>#{3} , <alpha-value>? ) |
rgb( <number>#{3} , <alpha-value>? )
Old algorithm doesn't exit from a function content when matched a function, and can't handle such syntaxes. To make matching work for syntaxes like this one, an adoption is required (by a patch as workaround). Now patches are not required.
Matching for syntaxes not compatible with greedy algorithms. For instance, syntax of composes (CSS Modules) is defined as <custom-ident>+ from <string>, and old matching algorithm failed on it because from is a valid value for <custom-ident> and it's capturing by <custom-ident>+ with no alternatives. New algorithm is not greedy, on first try it takes a minimum count of tokens allowed by a syntax and increases that count if possible on each returning in the branching point. Syntaxes like composes can be matched now as well.
A state machine approach gives some other benefits like a precise error locations. Previously, location of a problem could be confusing:
SyntaxMatchError: Mismatch
syntax: ...
value: rgb(1,2)
------------^
And now it's more helpful:
SyntaxMatchError: Mismatch
syntax: ...
value: rgb(1,2)
---------------^
Further improvements on syntax matching can improve error handling and probably provide some sort of suggestions.
Performance
New syntax matching approach requires more memory and time, because of AST to token stream transformation and checking all possible alternatives. However, new approach is more effective itself and have a room for further optimisations. Usually it takes the same or ~50% more time (depending on syntax and a matching value) compared with previous algorithm. So that's not a big deal.
The main goal the release was make it all works, so not every possible optimisation were implemented and more will come in next releases.
Other changes
- Lexer
- Syntax matching was completely reworked. Now it's token-based and uses state machine. Public API has not changed. However, some internal data structures have changed. Most significant change in syntax match result tree structure, it's became token-based instead of node-based.
- Grammar
- Changed grammar tree format:
- Added
Tokennode type to represent a single code point (<delim-token>) - Added
Multiplierthat wraps a single node (termproperty) - Added
AtKeywordto represent<at-keyword-token> - Removed
SlashandPercentnode types, they are replaced for a node withTokentype - Changed
Functionto represent<function-token>with no children - Removed
multiplierproperty fromGroup
- Added
- Changed
generate()method:- Method takes an
optionsas second argument now (generate(node, forceBraces, decorator)->generate(node, options)). Two options are supported:forceBracesanddecorator - When a second parameter is a function it treats as
decorateoption value, i.e.generate(node, fn)->generate(node, { decorate: fn }) - Decorate function invokes with additional parameter – a reference to a node
- Method takes an
- Changed grammar tree format:
- Tokenizer
- Renamed
Atruleconst toAtKeyword
- Renamed