Efficiency for GridSearchCV on large graphs #29
Comments
|
I think what you are saying is that top shows scheduler running and using cpu but the workers do not show any cpu usage and there is no activity on the dashboard. |
|
I would need to see how you are setting up your workers. Do you have any set up? If you don't want to deal with setting up a scheduler and workers you might also just create a client without arguments Also, Executor is an old name for Client. I recommend switching. |
|
Yes, we also tried Client() but it does not work. Here is the detail information.
Nothing show up in the section of Task-Stream in dashboard (http://173.208.222.74:8866/status/) Thanks! |
|
Does it run? Does it appear to be using the workers? Is there anything interesting in the logs? What version of bokeh do you have installed? |
|
In this example (model = XGBRegressor), it does not work. But, other example we tried before works. So, in this example, the dash board looks like:
worker status look like: |


|
Does your computation run? Does any computation run? You might be able to isolate your problem by trying a few different things and seeing if they work or don't work. Does client connect? Does it see workers? Can you scatter data out? Can you perform simple computations, etc... To be clear I'm not asking for the answers to these questions. I'm recommending that you try a few things to see what does and does not work. That might help you to identify what is going wrong. |
|
when I saw the following. It means client connect, right? worker: But, |


|
Yes. Have you tried the quickstart yet? That might be a good place to start: http://distributed.readthedocs.io/en/latest/quickstart.html |
|
Sure. I tried these things. But, the issue is the following:
So, my question is why DaskGridSearchCV works in DecisionTreeRegressor but no in XGBRegressor (both of them use Client set-up as your suggestion.). Thank you. |
|
I just noticed that xgboost has a different dask integration. We will try that next. However it seems that the vanilla way of calling XGBoost from scikit learn is broken. So on this one, a summary of what we have tried so far:
So we can conclude that there is something between dask-learn and xgboost that is causing an interaction. Ritesh |
|
So I tried the same computation with the single threaded scheduler And found that it appeared to hang and not make any progress. So I started it, let it ran for a while, and then Ctrl-C'd while running pdb to jump to whatever it was working on. I went up a little bit in the stack and then ran into a point where it was looping over all candidate parameters. It looks like there are half a million of them. It's probably just taking a while to set things up. So I cut down the grid significantly, ran things, and they appeared to run fine. My guess is that this was just spending a while setting up a very large computational graph. I think one lesson here might to start with a small problem and then scale up after you have it running. It would be interesting to look into how to reduce overhead, but we should first verify that the overhead is large relative to expected costs. |
|
Hi, Matt, I work with Pinju and Ritesh, Actually I came out this parameters range.
|
|
From those times it looks like it has an overhead of around 1.5ms per candidate. There might be some tuning we can do to take that down a bit. Is it worth it? What are runtimes in those cases? In the last case it could be that the graph itself is too large to fit comfortably into memory? I made a small case with two parameters with three and five options each. This resulted in a dask graph of size 171. This dask graph took about 15MB to serialize. cc @jcrist if he has thoughts here. |
|
Looks like most of the 15MB in the comment above was just the input data. I've reduced this problem down to the following minimally reproducible example (examples like these are highly preferred). import pandas as pd
from xgboost.sklearn import XGBRegressor
from dklearn import DaskGridSearchCV
import numpy as np
model = XGBRegressor()
x = pd.DataFrame({i: np.random.random(100) for i in range(10)})
y = pd.Series(np.random.random(100) > 0.5)
grid = {'gamma': [0.5, 0.75, 1, 1.25, 1.5], 'colsample_bytree': [0.25,0.5,0.7, 0.9,1]}
gs = DaskGridSearchCV(model, grid).fit(x, y)
>>> len(gs.dask_graph_)
261
import cloudpickle
>>> sum([len(cloudpickle.dumps(v)) for v in gs.dask_graph_.values()])
107559The size of the graph is a little bit interesting. 5 by 5 options yields 260 tasks. I can see how if there were hundreds of thousands of tasks that that might become problematic. I hope that by providing the minimal example above @jcrist is more easily able to play with this example and provide some feedback on what might be going on. |
|
Hi, Matt, I think the 1.5ms overhead is not necessary for tuning right now. Actually I run the exactly same test with 504000 candidates last night before I sleep, strange thing is this time the kernel didn't kill grid search process, but processes memory got freed, scheduler is holding 1.8gb memory and still nothing shows on the status page, I think dask is not working on those tasks. I wish dask (scheduler/worker/DaskGridSearchCV etc.) will have the option shows much more verbose log, then it will be easier to narrow down the problem. And I don't even know what the correct graph size should be to determine minimal example.. |
|
You can increase the verbosity of the log in the logging:
distributed: info
distributed.scheduler: debugYou could also look at the dashboards at |
|
Or if you set up a LocalCluster you can just have the scheduler in your main process. http://distributed.readthedocs.io/en/latest/local-cluster.html |
|
Thanks, that's very good to know! |
|
Hi, Matt, I wrote the code that break large parameters range into list of smaller parameters range with limitation of candidates, and doing grid search one by one and selecting the best score among the list, seems working so far. But still I think the number of tasks need be investigated. And I changed logging into debug level, with large number of candidates, I didn't see too much good info, and there are lots of ping like logging every second. I will try LocalCluster if I have some time, does that logging setting will enable verbose logging on DaskGridSearchCV? |
|
I don't know what logging DaskGridSearchCV does, if any. You'll need to ask @jcrist about most of this (I don't work on dask-learn). The benefit to |
|
I took a look at a profiling the example above with a small set of parameters. There were four parameters with counts 5, 5, 7, and 4. I found that this generated about 9000 tasks we had about 1.7s of overhead, 1.2s of which was due to sklearn calls in getting and setting parameters. I wonder we could avoid this by doing the cloning within the task itself, rather than while building the task. This would also cut down on serialization and tokenization costs because we would only have to push a single sklearn executor into the graph. @jcrist I don't have enough experience with the dask-learn codebase to know if this is reasonable. Thoughts? Can we do some of the estimator manipulation work in the tasks rather than at graph construction time? |
|
For profiling I was doing the following: import pandas as pd
from xgboost.sklearn import XGBRegressor
from dklearn import DaskGridSearchCV
import numpy as np
model = XGBRegressor()
x = pd.DataFrame({i: np.random.random(100) for i in range(10)})
y = pd.Series(np.random.random(100) > 0.5)
grid = {'gamma': [0.5, 0.75, 1, 1.25, 1.5], 'colsample_bytree': [0.25,0.5,0.7, 0.9,1], 'max_depth': range(1,12,2), 'learning_rate' : [0.01, 0.03, 0.05, 0.07, 0.09, 0.1, 0.2],
}
%load_ext snakeviz
%snakeviz gs = DaskGridSearchCV(model, grid).fit(x, y) |
|
Matt, I think you mean following?
since dask has graph, 3 can depended on 2 then depend on 1, thus reduce(scores). |
|
Apologies for the lack of reply here. Constructing the estimators inside the graph (instead of beforehand as we do now) is tricky in a couple respects:
I initially did the easiest thing, which was to initialize each estimator at graph build time, which handles both those cases nicely. I should (hopefully) have some time to look at this soon. My first thought is just to reduce the cost of tokenizing each estimator, which should be possible with some tricks. Since we're only serializing unfit estimators, they're not all that expensive to serialize, so I doubt that's the main cost here. But the tokenizing for each candidate could add up. Worst case, we do all this in the graph, and the code is more complicated. But these are solvable problems. One question I have is how many candidates is it normal to grid_search with? I made the (possibly naive) assumption that these were usually in the tens to low hundreds, not in the hundreds of thousands as I see above. For smaller numbers of candidates, with mildly expensive to run tasks, the current implementation should have low relative overhead. Same question for cv splits? I genuinely don't know how these tools are used in practice. |
|
At a fine grained level I mean the following: estimator = delayed(estimator) # stick the estimator in the graph once
others = [delayed(clone_and_set_params)(estimator, params) for params in candidate_params]
fit = [delayed(fit)(other, data) for other in others]This is obviously way more simple than things actually play out, but the point is that the graph really only has one estimator in it. The workers will move it among themselves as necessary. There are now a bunch of dicts of parameters in the graph instead, along with references to the original estimator, but both dicts and the reference are pretty lightweight. I think that this minimizes overhead on the client and scheduler side and moves that overhead to the workers (who can handle it much more effectively). @jcrist tokenization was an issue, but I also found a nontrivial cost to just calling Of course, all of this only makes sense if checking half a million candidates in a grid search is likely to occur. I think that @pinjutien @bansalr and @yzard may be able to help us understand what is generally common in practice. I have to admit that I'm also somewhat surprised by this number. I would expect people to try other search strategies after a certain point. I wonder if RandomSearchCV would have better performance. I'm also curious if an active search strategy might be preferred. I don't have any experience on the ground on this problem though. If you all have feedback from the field I'd love to hear it. |
|
Thanks for the quick feedback @mrocklin @jcrist For hyperparameter optimization (there are different ways, like Grid Search, Gradient Decent): Neural Network use gradient decent and back propagation to tweaking hyper parameters, it has good and bad sides, it need huge amount of data, also gradient decent need the hyper parameters are continuous, and it might found the local optimal not global optimal. Since the gradient decent, good side is: it can tuning much more hyper parameters, I would like to say, millions (because of the layers), each one can varies from -infinite to +infinite For decision tree based algorithm we used, some of the hyper parameters are even discrete like tree depth, gradient decent way is not capable of doing on those models (you can by setting fixed discrete hyper parameters, but still need lots of data, and only limits to Random Forest). And why we using tree based algorithm? since for problem we are trying to solve, the data is discrete and not as many as images (I mean terabytes). For example, there is a data feature called typeOfHeat, it can be either gas, electrical, propane, etc, it's not from 0~1. And each feature might doesn't have continuous relationship. For example, the cat images, each adjacent pixels have obvious continuous relationship. That's why deep learning working so good on Images, Video, Voice, etc, and then no improvement on other problems. So grid search (either random/or brute force) is a reasonable way to do hyper parameter optimization for tree based algorithm, especially for gradient boosting trees (xgboost). And still, grid search is actually just samples points in the hyper parameters space. Theoretically, the number of candidates should not be the related to the memory problem. Back to the sample we provide, the training data that it's only 15mb and very small, and cross validation will split the data to let's say 3 folds, means 3 identical parts [1,2,3], I think this occupies lots of memory too, ideally each worker need only one copy of [1,2,3] and one raw estimator, if the data is 1gb big, I am not sure what will going on here for gridsearch, and that's not very big actually. Usually more data generates much better models. If there are some better algorithm comes out, grid search might will get retired, but for now, I didn't see any possibilities, as long as those tree based is used widely. |
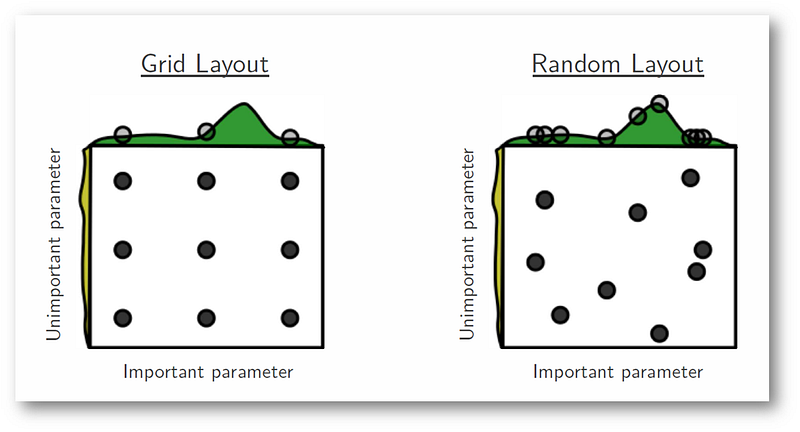
Memory issuesThe memory problems you were seeing had nothing to do with the size of your data. It had to do with the metadata of the graph. I think that we can reduce that with the changes that @jcrist mentions above. Alternatives to GridSearchI rarely put gridsearch and gradient descent in the same category just because gridsearch is more often used on hyperparamters while gridsearch is more often used on parameters (or so I've been told). I think of RandomSearchCV as the standard alternative to GridSearchCV. This sklearn example might be interesting, I haven't run through it yet though: http://scikit-learn.org/stable/auto_examples/model_selection/randomized_search.html This blogpost has the argument that I've heard before: https://medium.com/rants-on-machine-learning/smarter-parameter-sweeps-or-why-grid-search-is-plain-stupid-c17d97a0e881#.w121wqyu6 In particular this image from that blogpost does a decent job of explaining their point quickly, think: But at the end of the day, I don't actually do any of this work. GridSearchCV should run efficiently regardless. |
|
Thanks, @mrocklin, I am so happy you wrote dask library, which I dreamed about, decoupled computation logic and data. made parallel computing capable and efficient. Tensorflow used similar idea, but dask are way more generic, So grid search/random search, even gradient decent can take advantage of this. I put grid search and gradient decent search simply all of their goals are to search the best parameters that fits training data best (I will put overfitting on the side), please see this: |
|
@jcrist cross validation is a method that preventing model from overfitting see https://en.wikipedia.org/wiki/Overfitting. And there is no clear edge said it's overfitting or not. for k folds cv, normally choose 10 is pretty common. But k is also a parameter to choose, more folds normally tend to more close to overfitting: Putting an extreme example, if we want cross validate classifier, got 100 training data, and use 100 folds, so each turn you use 99 data to train model and use 1 to validate the model, and repeat for 100 times, then average the results. for 100 models, they are all very similar. and the same time, it will generates 100 models. I will not talk k too much, this is usually tweaking by the experience, usually more data use smaller k, less data use higher k but not extremely high like the example above. for smaller data set, the purpose is to suck any kind information of the limited data, and avoid overfitting. |
|
@yzard: thanks. I understand what grid search and cross validation are. The big question I have is how large are common grids in the number of candidates. This affects how we choose to balance simplicity of implementation with performance. I assumed large grids (like the 500,000 candidate one you show above) would be uncommon, but may have been mistaken. More insight on common numbers of candidates would be helpful. |
|
When I look at the example @pinjutien provided here https://github.com/pinjutien/grid-search/blob/master/grid_search_issue2/test.py#L13-L27 I'll admit that it does make large grids seem more reasonable. |
|
At a certain point though this must stop making sense. @amueller any thoughts here on active searching through hyperparameter spaces? |
|
Those are not all parameters of DecisionTreeClassifier (gamma and reg_alpha for example) and the code should fail. It looks like a bug to me that it is not. I guess some workers fail silently? Is the question how large a grid is reasonable? I'm not sure that's an easy to answer question ;) |
|
Yes, the grid above is for xgboost.
Yes
There are tradeoffs here in code complexity, feature support, and supporting very large grids. @jcrist and I are curious what the distribution of desired grids would look like. One hypothesis is that after a certain point people will just drop grid search and move to more active strategies (which would be pretty easy to build with dask.distributed's async API by the way if you know anyone). But that might not hold. Question: Is there sufficient appetite for million-candidate-paramter-grids such that we should consider it an reasonable priority. |
|
@amueller 50,000 is just sampled more points :), 50 times of the reasonable number you mentioned as in the , and XGB supports L1/L2 regularization. you can see I disabled L2 for this example. |
|
It's pretty easy to expand the logic "well I want to add a couple more parameters to the grid search" a few times to get to a point where no cluster can handle it. Even if we reduce the overhead of the dask scheduler to zero it seems like it would still take years to go through an exhaustive list of twenty parameters with ten options each. The question I think we should consider is where do we want to place finite developer time? How far do we go into reducing scheduler overhead and when do we switch to exploring different algorithms. @jcrist brought up hyperopt in private conversation. Any thoughts @amueller |
|
cc @jbergstra . Not sure if you're still interested in the tools-for-hyper-parameter-optimization business. Feel free to ignore, or better yet forward to an appropriately interested graduate student :) |
|
@mrocklin, We regularly do grid search with 100k+ folds. We usually do it by using a high compute capacity on AWS and letting it run for 10-30 hours (or more). As I mentioned before, GridSearch is the obvious application for dask to sklearn. However what we see here is that Dask is unable to speedup workloads that sklearn can handle over a matter of 10-30 hours using 30-60 cores. I would say that we are far from approaching anything that would exhaust a moderate sized cluster of 500-1000 cores. I am sure there will be applications that will get to that boundary but this is not one of them. Perhaps naive parallelism for GridSearch using dask is the answer. That will provide data hashing to avoid sending multiple copies to workers but not calculate common computation blocks to memoize those across the graph. That seems to be the thing breaking things right now. PinJu has also had similar results on fairly small problems where setting cv>3 breaks the graph comptutation. This is with the AirBnB dataset from Kaggle where the raw data is 27MB but the workers balloon to ~3GB. |
|
Thanks for the details. I'll let @jcrist follow up. I think he's been doing some tuning. |
|
Thanks for the details here. A few bits:
The reason things are slow right now is that grids of this size are not what I optimized for when writing this. These are solvable problems, they'll just require more complicated code.
Can you explain this? What do you mean "breaks the graph computation"? If you can provide a reproducible test case, I'm sure this can be fixed. |
|
I speak colloquially when I say "breaks the graph computation". Namely that the example works with scikit-learn but dask-learn the workers grow large and run out of memory. Pin-Ju will post the complete details along with an example this evening. |
|
Wasn't this on this thread that I mentioned scikit-optimize and pinged @MechCoder who is working on this right now? And the paper by Snoek on hyperparameter tuning has a section on distributing Bayesian optimization. I think James Bergstra is in stealth mode ;) What are the current boundaries? What size graphs work well and what don't? |
|
This is from an email Pin-Ju sent this weekend to me with some results. He will post the complete example and plots this evening. For CV=3 and workers=7, this fails to complete on a machine with 32 cpus and 32GB of RAM. Data set is ~27mb raw on disk (AirBnB Kaggle data set). Hello, To investigate the memory usage vs number of workers, I did a following study and something interesting happen: For one worker, I increase the cv from 2 to 4 and check the length of dask_graph. number of workers: 1 cv = 2 cv = 3 cv = 4 The size of increasing graph is very similar the increasing of cv number. Thanks, ref: train data set: ~25mb |
|
Yes, the graph size scales linearly with the number of cv splits. Each candidate/split pair gets a task in the graph - twice as many splits leads to twice as many tasks.
This I don't follow - at most each worker should have 1 copy of each cv split. I guess I'll wait until the issue is reported :). @pinjutien, please post your findings as a separate issue, this one is already sufficient in scope. |
|
Graph building was sped up significantly in #37. With a small edit to remove compute from actually happening, I ran the following benchmark on that PR. This builds a grid of 500,000 candidates with 3 splits (1,500,000 individually fit estimators) and measures the time to build and serialize the graph. import numpy as np
from sklearn.tree import DecisionTreeClassifier
from dklearn import DaskGridSearchCV
from sklearn.datasets import make_classification
from timeit import default_timer
import pickle
# Make data small so nbytes cost is negligible
X, y = make_classification(2, n_features=5)
model = DecisionTreeClassifier()
# 500,000 samples
grid = {'max_depth': np.arange(1, 1001), # 1000
'random_state': np.arange(100), # 100
'min_samples_leaf': np.arange(1, 6)} # 5
grid_search = DaskGridSearchCV(model, grid)
start = default_timer()
grid_search.fit(X, y)
stop = default_timer()
print("Graph building took %.3f seconds" % (stop - start))
print("Graph has %d tasks" % len(grid_search.dask_graph_))
start = default_timer()
nbytes = sum(map(len, map(pickle.dumps, grid_search.dask_graph_.values())))
stop = default_timer()
print("Serialized graph takes %.3f GB" % (nbytes / 1e9))
print("Serializing graph took %.3f seconds" % (stop - start))This results in: (dask) jcrist grid-search $ python dklearn_grid_search_script.py
Graph building took 14.465 seconds
Graph has 3000008 tasks
Serialized graph takes 1.403 GB
Serializing graph took 42.132 secondsBuilding the graph is no longer the bottleneck, rather the cost of serializing has become large. However, I'm not sure if there's any way around this when you're creating roughly 3 million tasks. If each task serializes to ~400 bytes each then hitting 1.4GB serialized isn't hard. Still, a graph this size will take many many hours to run, so the upfront cost of serializing it should be negligible in the long run. For the special (and common) case of non-pipeline estimators, the number of tasks could be halved by doing the fit and score all in the same task. However, I'm not likely to work on that until other things have been done first. This would improve serialization time, at the cost of yet-another-code-path. |
|
Thanks a lot! Jim, I will try it out. |
Hi,
We have another issue of DaskGridSearchCV. The example is XGBRegressor (https://github.com/pinjutien/grid-search/tree/master/grid_search_issue2).
In this case, when DaskGridSearchCV is on, there is nothing showing up in dash-board(for example, http://173.208.222.74:8866/status/). Both Client or Executor have no dash-board showing up.
Thanks,
Pin-Ju
The text was updated successfully, but these errors were encountered: