Replies: 18 comments 33 replies
-
|
I honestly was not on board with this at all until this line:
In practice, I see so many people screw themselves up trying to split up projects for the wrong reasons. They quickly blow up the great unifying ability of dbt to create a single source of truth, and lose the most positive effect of dbt's current limitations in this area, which is forcing you to collaborate across functions, create unified definitions, and break down silos (it's a feature 🦋 not a 🐛!). The easier we make this, the more likely analytics teams are to end up with two different orders models for two different teams and find themselves hating life. That said! -- housing these projects in a unified repo would help mitigate a lot of the worst effects of separation while gaining the benefits of increased modularity. This actually is the idea of the modern monorepo, and what you're trying to break down is the monolith -- so I would say your alternative title should be 'Down with monolith, up with the monorepo'. |
Beta Was this translation helpful? Give feedback.
-
|
@jtcohen6 , this makes a lot of sense and nicely fits into the whole #DataMesh concept that is emerging. If you want multiple domain teams to each be responsible for a part of the code, those individual code bases should still work together nicely / know of each others existence and dependencies. By doing this, dbt Labs could also start selling dbt as a tool that fits nicely into the 'Data Mesh hype train', which will for sure attract new customers! :-) |
Beta Was this translation helpful? Give feedback.
-
|
More thoughts on model versioning, after a great conversation this afternoon with some interested folks. There are two options here:
|
Beta Was this translation helpful? Give feedback.
-
|
oooh i like the module level w/ cloning and deferment idea a lot, you get the best of both there 🔥 |
Beta Was this translation helpful? Give feedback.
-
|
I am extremely interested in this topic. I think there are very few topics being discussed right now that are more impactful for the long-term experience of dbt project development. We have always wanted to provide the modularity of software development when it comes to building knowledge graphs, but dbt in its current form does not yet provide this. Being able to take large chunks of functionality and call them
There are a million other things that are important in this as well (i.e. how does all of this get represented in a visual DAG? i don't believe the correct answer is always just "explode everything and show all of the detail!!") but I think the above two things are the biggest items and other stuff must fall out of the approaches we take there. |
Beta Was this translation helpful? Give feedback.
-
|
re: "how do we represent it in the DAG," it would be cool if you had the option of exploding (ok, exploring) black boxes of upstream projects, and then closing them up once you've seen what you need to see. Just like a collapsible nested menu on a website, or a file system with subdirectories. |
Beta Was this translation helpful? Give feedback.
-
|
I hear you! Something like this diagram? https://whimsical.com/public-private-dbt-models-monorepo-edition-2NxeKuU8oUiPxpKrkWpsvo@2Ux7TurymMZyQVhtBJxg |
Beta Was this translation helpful? Give feedback.
-
|
@jtcohen6, what if we treat cross project objects just like a source? My colleague's model is a source. (I think, atleast, separate project/repo by team) For all of development purposes they act like a source: you can't (shouldn't) schedule them; you don't need to rebuild them for your development or PR checks. Only when visualizing the lineage or building the dbt docs, dbt would need to extract metadata from the other project and get mapping between database object name and model name to show the upstream lineage. The core of dbt could stay the same. It make sense to use database object name as an interface between teams rather than dbt model name because most (95%+) of the downstream user are your analyst that using various reporting tools. Also, if teams are using alias in models, then you don't have to confirm individual model name. Whereas, if you use model name for reference between dbt project, then model name will also be tied to dependencies along with database object name. Main advantage for customer with existing data transformation that are gradually switching to dbt is: As other teams migrate their code to dbt, your lineage would automatically grow. You don't have to update your code to switch from source() to ref(). If your database has mix of tables build using dbt (from source data already replicated into your database server) and other external integration, then other teams using your table don't need to know how individual tables are built beforehand. Lineage or dbt docs can highlight such tables differently depending on whether they exists in the dbt project or not. Regarding getting the downstream dependencies between project: Like you said, there should be a purpose built "one big docs" jobs that combines metadata from all project. It is safe to assume that this job will have access to metadata from all projects in an account. Versioning has always been tricky with data analytics because you have to continually refresh data in old and new versions. As long as the grain of a table is staying the same, it is efficient manage it within single model (by adding new column for change in logic or if you have to drop a column, wait for all downstream to remove their dependencies). So i think, versioning would be a separate topic on it own. |
Beta Was this translation helpful? Give feedback.
-
|
@karunpoudel Really appreciate the comment! I have two main points of disagreement:
I do take your point that downstream BI users reference dbt models by their database locations today, not by their model names. That doesn't need to be the case forever, though—and it's been one of our motivations for developing (separately) a semantic layer that can translate between BI queries and dbt project context, and unify disjoint lineage. |
Beta Was this translation helpful? Give feedback.
-
|
Good feedback from @lostmygithubaccount: Whether this is a source-that's-actually-a-model (inferred by dbt after the fact), or a public-model-from-someone-else's-project (resolved by cross-project Maybe a distinct color in the |
Beta Was this translation helpful? Give feedback.
-
|
I'm happy to own the blueprints and mechanical discovery of how exactly this can be a reality in dbt. Going to draft my ideas and work internally at dbt Labs before sharing complete thoughts in this discussion 🧃 |
Beta Was this translation helpful? Give feedback.
-
|
very interested in this topic and will be eagerly waiting to hear more! |
Beta Was this translation helpful? Give feedback.
-
|
Okay Community! This is going to be a juicy 2 part post. The first is philosophical and the second has code snippets to crystallize the philosophy with something tangible to discuss! Goals:
Note: Portions of this are thematically consistent with @jtcohen6's original post. I do this to prevent you scrolling up and down to understand the full story :) Part 1: Old Problems with New ParadigmsThe ProblemsHaving a monorepo is overwhelming to newcomers and maintainers of a dbt project.
Using a multirepo approach is less overwhelming to reason about files but brittle in building lineage and confident dependencies across repos
Both approaches in their current state hit a ceiling and requires tech lead heroes to roll up their sleeves and offer themselves as PR babysitter tributes. New ParadigmsData Contracts are the API analogy for data
Working with data is very different from APIs
Values of this system
Use Cases/ Who is this for?
|
Beta Was this translation helpful? Give feedback.
-
|
Some comments regarding data contracts - might be worth to have another discussion on that:
|
Beta Was this translation helpful? Give feedback.
-
I would suggest to infer downstream dependencies for a project (through the unified lineage) so that in case of a version upgrade, you can notify the people who depend on you. Explicitly specifying downstream dependencies means that we need to keep dependencies in sync in multiple places, so that would be hard to maintain. |
Beta Was this translation helpful? Give feedback.
-
|
@sungchun12 Lots of good stuff in these comments!! I agree with lots of the conceptual things you've laid out here. Any of the specific code or implementation details can change between now and later; it's helpful to make the discussion concrete. What are we going to call this thing? I've heard "upstream namespace," "upstream/data contract"... for now I'm going to refer to this thing as ATM (Another Team's Models), until we have a final name for it. I think an ATM could include more than just models — I want to make a few strong claims to help us clarify points of potential disagreement. These claims aren't final, they're intended to spark further discussion! Access to source codeUnlike other modes of installing packages, I believe that adding an ATM should not require access to the source code for the project generating those models. As a developer in the downstream project, I should know which public models exist, be able to read their documentation, and see the tests / metadata on their columns. But I should not be able to see its source code or its upstream dependencies. I should not be able to see the existence of private models at all — I shouldn't even know their names, let alone not having the database permissions to query them. A few corollaries:
In order to generate a full DAG, containing every model (private + public) from every single project/namespace, I'd need either:
Data contracts@Junobijlard Love the questions you're asking! At their simplest, for dbt's purposes, I've been thinking about data contracts, for data produced by a data team, as comprised of:
I think contracts are and remain an essential part of the discussion. At the same time, I also recognize that there have been broader conversations floating around about the need for data contracts further up the ELT stack, starting with the application developer who's performing a database migration. API middleware to handle those renames?). I don't think dbt can solve for that all by itself, not nearly as well as it can help the (data) team creating models depended on by (another data) team. We need other things: API middleware, between app db and EL tool? I'm open to thoughts on how the solution we pursue in dbt could fit into a larger narrative. (What if the the I'm also open to the argument that there's a fundamental difference between contracts for "raw" data (true sources), and "transformed" data produced by another data team — and we'd need different mechanisms to define and enforce each one.
Agreed! This feels totally plausible with a unified metadata service, whether in dbt Cloud or home-grown. Much, much trickier to do in dbt Core only. As the upstream project maintainer, you need access to metadata / logs from downstream projects one way or another. |
Beta Was this translation helpful? Give feedback.
-
|
Is dbt really the tool to define data contracts? What do you see as the interface of a contract?
Should this config include imports only(think: upstream) OR both upstream/downstream projects? Access to source code
|
Beta Was this translation helpful? Give feedback.
-
@jtcohen6 I tend to think that instead of the distinction being between contracts for "raw" data and those for "transformed" data, there is a fundamental difference between the "promises" a data producer makes about the data assets they make available and the "expectations" a data consumer has of the assets they're referencing from these upstream producers. Applying that to your example, those two feel different because in one case the dbt project is a consumer of data being produced by an external service or API and in the other it is a producer for a downstream dbt project. I'd argue that these two are fundamentally the same:
These two, on the other hand, are both examples of the opposite relationship:
While both are "contracts" in some sense, I think one can exist without the other. In my ideal world, a dbt project would be able to make freshness, schema, test coverage promises to downstream consumers just as it would be able to declare expectations of upstream sources (whether true sources or other dbt projects). I imagine you can do the latter with some combination of dbt tests, source freshness, and zero copy clones as @sungchun12 describes here. Importantly, you could do either one without doing the other! What do you think? |
Beta Was this translation helpful? Give feedback.
-
In the 'exposing a model' interface, you should be able to specify who (e.g. google group) you want to expose your model to. Ideally, we also automatically apply the permissions to access the table to that group |
Beta Was this translation helpful? Give feedback.
-
|
IMO this is exactly what (And on BigQuery, google groups are indeed supported as recipients of grants) In addition to "publishing" a model with a contract, you'd also coordinate database-level permissions so that the right folks can actually use it. |
Beta Was this translation helpful? Give feedback.
-
|
The base mechanics of granting permissions is definitely something that should be configurable in the data contract! |
Beta Was this translation helpful? Give feedback.
-
I'm not sure if you should allow an 'outsider' to trigger an upstream model to build
|
Beta Was this translation helpful? Give feedback.
-
|
Deployment is a super interesting question here! As a general rule, I do not think we should allow downstream consumers to run models from upstream namespaces. Access to source code for those models should be absolutely optional, and same for database permissions on their upstream dependencies. So, I think there are three potential mechanisms for deployment:
|
Beta Was this translation helpful? Give feedback.
-
|
Sounds like we generally agree that strong gatekeeping to invoke any upstream/downstream projects is necessary. I also see a future where BOTH Agnostic and uncoordinated and God mode happen. Metadata-driven I'm fully aligned and there needs to be a persisted database behind the scenes to track this info! I'm aligned that in general, downstream projects should NOT invoke upstream projects. Agnostic and uncoordinated:
God mode:
$ terraform apply
aws_instance.app_server: Refreshing state... [id=i-01e03375ba238b384]
Terraform used the selected providers to generate the following execution plan.
Resource actions are indicated with the following symbols:
-/+ destroy and then create replacement
Terraform will perform the following actions:
# aws_instance.app_server must be replaced
-/+ resource "aws_instance" "app_server" {
~ ami = "ami-830c94e3" -> "ami-08d70e59c07c61a3a" # forces replacement
~ arn = "arn:aws:ec2:us-west-2:561656980159:instance/i-01e03375ba238b384" -> (known after apply)
##...
Plan: 1 to add, 0 to change, 1 to destroy.
Do you want to perform these actions?
Terraform will perform the actions described above.
Only 'yes' will be accepted to approve.
Enter a value: |
Beta Was this translation helpful? Give feedback.
-
|
Thanks for laying this out @sungchun12 ! It definitely helps to visualize it. I concede that others may be more “in the thick of it” than I ever have been, but here’s my thoughts: Setup
Upgrading contracts
Invoking upstream contract models
Limiting the use of modelsThere’s no questions to answer here, but this section has satisfied the use case of the downstream contracts thought above. I wonder if you could also just reference a folder path here, as I’m imagining a scenario where you want to share most models except a few. Maybe something like: from models:
# Model folder level
+shared: true
+except:
- ref('my_model')
# Sub-folder level
marts:
+shared: trueor sharing from the dbt_project.yml level after defining contracts (which might be a messy idea): from models:
marts:
+share_with: [contract('finance-only'), contract('marketing-only')]@_@ big brain thinking with too smol brain |
Beta Was this translation helpful? Give feedback.
-
|
Should this be additional configs within dbt_project.yml OR its own config like dbt_contracts.yml?
Should this config include imports only(think: upstream) OR both upstream/downstream projects?
Should this file live in a single git repo to centralize contracting? If I’m running this command starting from the core-only project, how does core-only know about downstream projects?
Limiting the use of models |
Beta Was this translation helpful? Give feedback.
-
|
Quick and Dirty Thoughts
|
Beta Was this translation helpful? Give feedback.
-
|
I was talking about a similar idea to your first point this morning to @lbenezra-FA! It would also be great to be able to return the code for a particular model, to see what it's doing vs. navigating to the repo to see it! Currently for packages you could go look in the repo at the code, but when you install the package you can also navigate directly to the code in your |
Beta Was this translation helpful? Give feedback.
-
|
Hey Everyone! Please follow progress here: https://github.com/orgs/dbt-labs/projects/24 |
Beta Was this translation helpful? Give feedback.
-
|
A nice weekend gift for everyone! Please let me know if I'm going the right way or this is so wrong you want me to throw away this code now. Demo video on consuming an upstream project's nodes: here |
Beta Was this translation helpful? Give feedback.
-
|
Example Terminal Output |

Beta Was this translation helpful? Give feedback.
-
|
In conversation with dbt users: Background:
Downside:
Considerations:
|
Beta Was this translation helpful? Give feedback.
-
|
@sungchun12 Our team has a similar solution where we have an upstream dbt repo with two dbt projects. An orchestrated project that takes the common sources across our teams, cleans them and produces the data marts. Then, an external project defines the data marts from the first project as sources and creates ephemeral models from them. Downstream projects then consume that external project. I wrote a proposal for a blog post on sharing dbt models across multi-repos that goes over this approach that includes using code cleanliness tools like commitizen to properly version your dbt projects as a way of communicating how up to date those imported models are. Is this how teams are commonly doing this now? |
Beta Was this translation helpful? Give feedback.
-
|
@brandon-segal Thanks for sharing this. This is the first time I've seen ephemeral models and commitzen in use, but the mechanics are spiritually aligned to feedback I got from dbt users today. If this works for your team, that's so great, but the common pattern is what I illustrated above! |
Beta Was this translation helpful? Give feedback.
-
|
Hey @jtcohen6 , I agree with your assessment of the problem you are trying to solve. Context and problemTo add more context, I work in an organisation where we have thousands of nodes in a single dbt DAG. This is a new and natural phenomenon because of how dbt enables data analysts and analytics engineers to easily contribute models to the dbt project DAG. #power-to-the-people. And yes, at some point, those DAGs get large and unwieldy, resulting in long build times. So the next logical option is to break the big project down into sub-projects, effectively creating a DAG of DAGs. That's where the nightmare begins:
I have summarised these issues and more in my blog post. Clarifying questionI like your proposed solution of having cross-project dependencies using refs: This implies that there would need to be two dbt run modes in the future:
dbt run would be executed at the root of some kind of folder that sits outside of a dbt project folder. Are you thinking along the same lines too? My proposed solutionAn alternative and adjacent approach I would like to suggest is to de-couple the DAG and have each node of the DAG execute independently based on a freshness or condition-based trigger. I have written a blog to propose this approach here. The key highlights are: Create an event-loop that checks every 5 minutes to see if the run conditions are
This is similar to the approach of a distribution centre. Packages arrive from multiple sources, however each package is not shipped to a customer immediately. Instead, the distribution centre waits for more packages to arrive before sending a batch of packages at once to maximise delivery. In our context, each node is its own distribution centre, and checks for upstream dependencies before triggering itself. Benefits: Prevents joins on stale data Loose coupling and independent sync frequency This means that each node has its own execution frequency, which allows each node to be executed independently from other nodes at varying intervals. This is in stark contrast to the mono-dag where the entire DAG is triggered on one schedule (e.g. 00:00 daily). Faster build and test times Uses critical path I am open to anyone's thoughts and critique of this approach. |
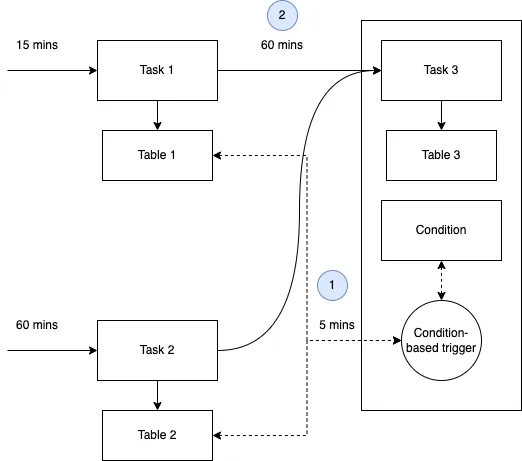

Beta Was this translation helpful? Give feedback.
-
|
Airflow has recently released something similar in their Sept 2022 2.4.0 release called data-aware scheduling which uses a push mechanism as opposed to a poll mechanism in my blog article. |

Beta Was this translation helpful? Give feedback.
-
|
Hey Folks! I’m here to wrap up this month-long R&D effort for dbt Contracts. There’s been a lot of work tracked across slack, github, demo videos, draft PRs that deserve to be consolidated and digestible for you all. Here it goes! TLDR: This work was so rewarding because in the midst of navigating this giant ocean of a problem, the community rose to the occasion to provide constructive feedback, and solidified this problem is worth solving for large data teams. Together, we parsed what building block efforts are needed to make dbt contracts work cohesively. These are efforts that are a win in the short term AND re-usable for contracts work in the long term. Although this research phase is over(at least Sung leading it), the work continues with statically typed SQL coming to dbt(think: enforce data types on columns). Read below to see more :) Goals:
Relevant Videos: https://loom.com/share/folder/30c6ce127a6143e0b28a6720ffe1ca9b Github Project: https://github.com/orgs/dbt-labs/projects/24/views/1 Relevant Docs:
Relevant Slack Threads: Draft PRs as Research: ref works across two projects: #5966 ref permissions within a monorepo: #6007 Exposures as dbt Contracts configs: #5944 Building Block Efforts: These are necessary components to make dbt Contracts function as a whole, integrated experience. Instead of boiling the ocean at once, these should be built and then reused for dbt Contracts when the time comes!
Next Steps:
|
Beta Was this translation helpful? Give feedback.
-
|
@jonathanneo check this one to see if it works! https://loom.com/share/folder/30c6ce127a6143e0b28a6720ffe1ca9b |
Beta Was this translation helpful? Give feedback.
-
|
Thanks @sungchun12 the link works. I've had a look at the recordings to understand what you've defined as dbt contracts. This one in particular. I don't really agree with your definition of a dbt contract at the moment. In your demo, your implementation of a dbt contract seems to cater more towards solving the problem of cross-project dependencies between nodes, rather than implementing a data contract. The term 'contract' implies an agreement between a producer and a consumer. A data contract should have the following characteristics (taken from Chad's blog article):
In conclusion: |
Beta Was this translation helpful? Give feedback.
-
|
I see that you have also implemented a models:
- name: my_table
config:
has_constraints: true
columns:
- name: id
data_type: int64
- name: color:
data_type: string That is currently used by the producer to generate the table DDLs. What is missing is using that as a contract for each producer-consumer relationship. For example: graph LR;
producer_A-->consumer_B;
producer_A-->consumer_C;
producer_A-->consumer_D;
Producer_A has 3 consumers: consumer_B, consumer_C, consumer_D. Therefore, there will need to be 3 data contracts that exist:
Each contract should contain specifications for:
|
Beta Was this translation helpful? Give feedback.
-
|
@jonathanneo Thanks so much for the thoughtful feedback and explaining why you disagree!
Yes, the purpose of this specific demo was primarily focused on cross-project dependencies between nodes. To build confidence in these dependencies, I envision we take components of the data contracts concepts and/or mechanisms. You already listed out a couple of them. I agree with all of the concepts. The implementations are up for debate!
OOoo. On a fist glance, I'd like this approach as it reduces the need to manage another credential. But taking a pause, there may be compiled SQL with multiple environment variables that make this approach prohibitive. I could see a producer create multiple contracts with the same dbt code that compiles to many different targets(think: multiple databases/schemas). In addition, the S3 approach mirrors the battle-tested mechanisms Terraform is successful with today. I recommend watching that here: https://www.loom.com/share/34d29d1151444ac9be98053612da0994
You're right! Our research doesn't cover this in too much detail, that's where we realize the short term work needs to happen! Column names and data types are critical to verifying data is looking and feeling as expected. I also like your idea on column position! I didn't think of that. My Ask: Want to work on bringing data types as native to the dbt experience together? |
Beta Was this translation helpful? Give feedback.
-
|
Sounds good! Let's work on this together, I'm happy to contribute where I can. |
Beta Was this translation helpful? Give feedback.
-
|
Hi team, want to pass on feedback I'm hearing from customers (incl. an organization that could have 100+ developers contributing and where they need to share code across teams while maintaining control on who can modify that code, when and where.)
|
Beta Was this translation helpful? Give feedback.
-
|
Hi all, hope I'm not late to the party but wanted to bring up some suggestions for the contract feature: In the context of data privacy / retention, I think it'd be very useful if the contracts would allow for different column / row level permissions, depending on the consumer. That way we could very easily ensure that people within the company don't have access to data they don't have to use. Is this something you're looking at? Thanks in advance! |
Beta Was this translation helpful? Give feedback.
-
|
Hey @paulbakkerbloom - to keep this work within a reasonable scope, we're keeping our thinking here at a model level. And I don't anticipate us attempting any magic to implicitly coordinate between a model being public/private (can or cannot be Certain data platforms support column-level policies for dynamic data masking/hashing, and row-level policies for restricting access. There are already community members applying these policies via dbt today, though it requires a bit of custom code (macros + hooks). I agree that it's compelling to envision a future where a single "public" model being able to serve multiple downstream dbt consumers, with differential access to rows/columns, all configurable natively from within dbt. |
Beta Was this translation helpful? Give feedback.
-
|
Hi @jtcohen6 and dbt team, |
Beta Was this translation helpful? Give feedback.
-
Newer discussion: #6725
Projects should be smaller.
Cross-project lineage should just work.
Alt title: "Down with the monorepo."
Context:
This isn't something we can make immediate progress on—but it's something I've been thinking a lot about, and I want to share that thinking to hear more folks' thoughts. Hence a discussion for now, with issues to follow when we're ready.
Strong premises, loosely stated
dbt runand see1 of 5000 STARTref.What is it?
There's a lot more to say here, and many implementation details I'm still trying to figure out, but I think it comes down to:
.yml) files for the same-named model. That property disambiguation is work we should still pursue, and we should also think about namespacing support for two models with the same names. Those aren't blockers for this work in particular, though, so they're outside scope for this proposal.ref()for models from other projects.dbt-coreskips resolving those refs at parse time, and resolves them as the first step of execution instead.dbt depsto access their source code.dbt-coregets access to a limited amount of metadata, which is more 1:1 mapping table than it is big badmanifest.json. This metadata could be extracted from those other projects, and provided as some sort of artifact.What might it look like?
In my project code:
There's no package named
another_packagein mypackages.yml, and there's no filedim_usersin thedbt_packagesdirectory. That's ok; dbt observes this at parse time, and leaves itself a reminder for later.At runtime, dbt gets access to a "mapping" artifact, akin to:
{ "upstream_project": { "model.upstream_project.dim_users": "analytics.acme.dim_users", "model.upstream_project.fct_activity": "analytics.acme.fct_activity", }, "upstream_project_two": { "seed.upstream_project_two.country_codes": "seed_db.seed_schema.iso2_country_codes", ... }, ... }And dbt compiles accordingly:
Considerations
CODEOWNERS), slim CI even slimmer.dbt-utils, respectively). Within an org, private packages will continue to serve the purpose of configuring.ref'ing a model, dbt will tell you where it lives in the database. That database location could include a version specifier in its schema/alias. As these cross-team and cross-project relationships mature, "public" models will naturally constitute a contracted API, and it will be important to retain the ability to make breaking and backwards-compatible changes. As the maintainer of downstream project B, I could continue referencing a versioned deployment of upstream project A, and then migrate to the new version at my own readiness (within some acceptable window).Beta Was this translation helpful? Give feedback.
All reactions