OLAP Sharding Model
[Table of Contents](https://github.com/dell-oss/Doradus/wiki/OLAP Databases: Table-of-Contents) | Previous | Next
OLAP Data Model: OLAP Sharding Model
OLAP employs a _sharding_ model that partitions data into named _shards_. The sharding strategy controls how data is loaded and queried.
A shard is a data partition. It is analogous to an OLAP cube, containing data that is organized into queryable dimensions. A shard is an application-level partition: every object is assigned to a shard, and a shard holds objects from all tables. Data is stored in arrays on a per-shard/per-field basis. Queries define one or more shards as their query scope. When a field is accessed by a query for a specific shard, the corresponding array is loaded into memory, typically in one I/O. Accessing field values is very fast: typically millions of values/second. Arrays are cached on an LRU basis.
A shard holds objects that are related by user-defined criteria. The most common criteria is time: for example, objects that were created in the same hour or day. But other criteria can be used such as geography or department. The goal of each shard is to hold "a few million" objects that balances load/merge time with memory usage. (Experimentation is highly encouraged.) A shard's name should reflect its contents, e.g., "2014-01-03" for a shard that holds data from January 3rd, 2014. Shards should use alphabetically-ordered names since queries can operate on shard name ranges (e.g., "2014-01-01" to "2014-01-31").
Objects are loaded into a shard in batches. A batch contains new, modified, and deleted objects in any order for any/all tables. Batches are intended to be large: typically thousands of objects. When one of more batches are loaded, the shard is merged to apply all updates. Once merged, a shard's updates are visible to queries. After a merge, a shard can receive more batches and be merged again.
A given object ID can be inserted into the same table in multiple shards. The duplicates may be identical or they may reflect the state of a given person, account, etc. over time. Duplicating objects between shards is desirable so that shards are self-contained graphs.
A shard can be explicitly deleted, which removes all of its data. Alternatively, each shard can be assigned an expire-date and will be automatically deleted by a background data-aging task when it expires.
An example of the OLAP sharding model is shown below:
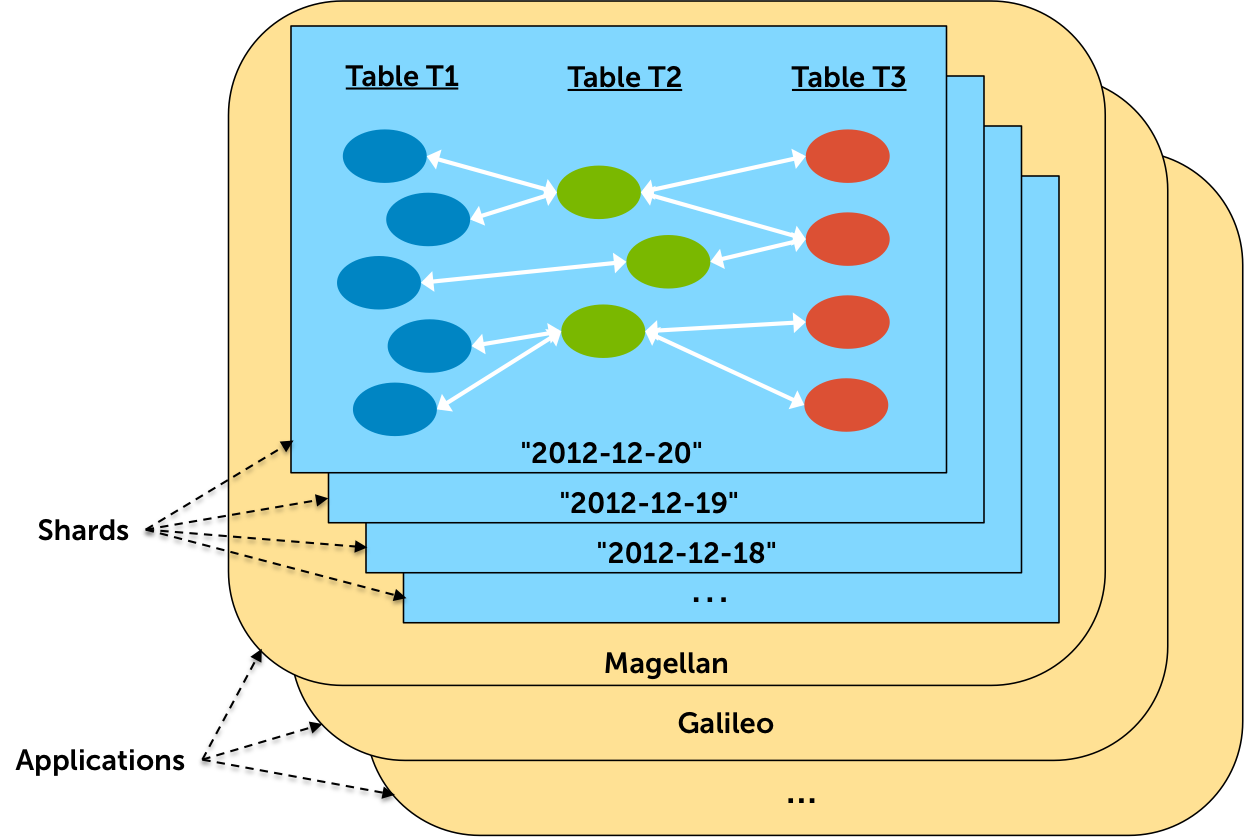
In this example, the database holds multiple applications (Magellan, Galileo.) Each application holds its own shards: The Magellan application's shards are named with dates ("2012-12-20", "2012-12-19", …). Each shard holds objects from all tables and are interrelated using links. Note that it is not necessary for an application to use multiple tables or links in order to take advantage of OLAP: a single table with only scalar fields is all some applications need.
Although data is organized into per-field/per-shard arrays, this structure is hidden from applications. Objects are queried using DQL object and aggregate queries. The only extra parameter required for queries is the shard list or range that defines the query's scope.