Newslator is a newspaper cover aggregator made with Symfony 3. This is my first project with Symfony, and it only has learning purposes and to check my skills.
First of all you will need php and composer. I'm using v7, but will work with v5.4 or superior:
$ apt-get install php7.0 php7.0-mysql php7.0-xml php7.0-simplexml
Then clone the repo:
$ git clone https://github.com/desaroger/newslator
And install everything:
$ composer install
First you will need to prepare the databases:
$ php bin/console doctrine:database:create
$ php bin/console doctrine:schema:create
And don't forget to set the credentials to let doctrine log on your mysql server. Finally, run the develop server:
$ php bin/console server:run
Then you can access localhost:8000 to see the newslator.
The newslator is made with some ingredients:
- Feed entity: It's a basic doctrine entity, the only model used on newslator.
- Feed controller: Inside
/feedsroute you will find a full CRUD service to create and manipulate feeds manually. - Feed type: A super basic form builder for our CRUD.
- Scraper service: It's a service in charge of load the html, get the data from the DOM and return a Feed entity.
- Scraper command: It's a console command you (or your cron) can run in order to load the today's news feeds.
- Scraper route: You can, as an alternate way to run the scraper, access to
/scraper. The arrow icon on the top right corner on the homepage loads this route. - Feed search: You also can make a search for feeds thanks to the route
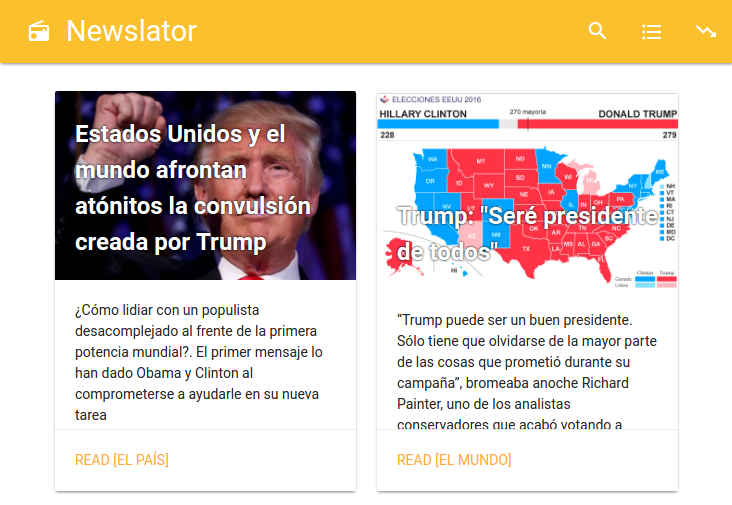
/feeds/search/anythingYouWant. - Homepage: The homepage shows all the feeds created today. Also is the way to go to the others services, like search for a feed, get the feed administration CRUD or call the scraper.
- Tests: Finally, a test battery will thinks not to break. I'm currently adding more tests, as I'm not happy with coverage.
It's basically the file that doctrine will create for you throught the command console. I added only 3 modifications:
- Added a created property with creation day automatically filled.
- Added hydrate method to merge two Feed entities. I know it can be done using the native symfony hydrate, but I was unable to make it works so finally I coded a simple function.
- Added toArray method to make Feed entities work nice with twig variables.
Can be found on src/AppBundle/Entity/Feed.php.
This is based on the autogenerated by symfony crud generator, but with some major modifications:
- Modified the indexAction in order to get the results paginated. I'm using the KnpPaginatorBundle.
- Added the indexSearchAction, which mades a search of the feeds containing a term. Isn't optimized for the database, it's only a test concept. It's out of my principal goals optimize the database, but it's on my sight.
Can be found on src/AppBundle/Controller/FeedController.php.
Based on the autogenerated by symfony crud generator, but with changes:
- Modified property publisher to be a selector of publishers and not an text input. It's made taking for granted that the publishers will always be the ones that exists for our scraper.
Can be found on src/AppBundle/Form/FeedType.php.
Well, this is the core functionality. It loads the html from the url and converts it to a Symfony crawler. Then navigates throught the DOM and finds out the information of the feed (title, body, image, etc). Then builds a Feed with this information. A log information is made on var/logs, with a rotary log by day.
This is the scraper v2. For learning (and future utility) I keep the v1, where the rss channels of the newspapers webpages were used. That was more easy and robust way to obtain the information, but this had a problem: there was no way to get the frontpage new from the rss, all was a mess (maybe intentionally) without any order. So finally was forced to go to a DOM crawler solution. This is the reason you needed to install php-simplexml, as I use it to crawl over the rss feed.
The big problem to develop this was that was made on the United States election's day, so all newspapers had a special frontpage with live information. Now I'm not sure yet if the crawler implementation will work with all possible covers.
Also, some newspapers load the images with javascript, hiding them until some checks are made. Because of that I was unable (for now) to get the image from some newspaper.
Can be found on src/AppBundle/Utils/Scraper2.php.
It's a big utility to be able to launch the scraper from a console command, allowing automate the process on a cron-like process.
With this command you can run scraper on one publisher:
$ php bin/console app:scraper elpais
Or to all the publishers:
$ php bin/console app:scraper
Anyway you do it will scrap the pages, get the feeds and persist them (if they was previously created then will be updated), and finally shows you a summary of what was made along your command.
Can be found on src/AppBundle/Command/AppScrapCommand.php.
This is a simple implementation. I wanted the possibility of load a url, showing a loading icon, and when the url was loaded the scraping was made. So simply added that route and a call to the Scraper service. They also loads the default template for showing feeds, so technically you can navigate to /scraper and see what was scraped. But the usage I made is only for the scraper button on the header.
Can be found on src/AppBundle/Controller/DefaultController.php, on scraperAction.
I felt the need to be able to find for a Feed, as a paginated list was not enough to work with the them. So added a material design styled find bar and a route where a search query is made to the database. As I said, it is a concept test and for now I'm happy with this poor implementation. For a future, a full-text search would have to be done.
Can be found on src/AppBundle/Controller/FeedController.php, on indexSearchAction.
The homepage is the list of feeds that were made today. It uses cards as the whole page tries to follow the material design guidelines. As the feed search, it makes a search against the database. And as it, hasn't been optimiced for this task. For a real working example I would suggest to build a memcache layer and to optimice the http cache, as the landing page will be the same to absolutly all the calls for 24 hours.
Can be found on src/AppBundle/Controller/DefaultController.php, on indexAction.
A simple bunch of tests. I'm not very happy with them, as I'm not very confident with the sturdiness of the Scraper service. There are a lot of little changes on everyday newspaper covers and without the time to store a great quantity of covers ands tests to make sure that Scraper works on everyone, I'm not sure this will work every day.
Also, I'm not experienced on testing Symfony (in fact this is my first project with Symfony, ever), so testing console commands or routes is new for me. Also, this is a service that rests 100% on an online service, so this adds more difficult to the tests.
For now I have 95% of coverage on the Scraper system. As the rest of the application is quite strightforward this is the coverage more important to me, and I'm happy with this, although this means nothing if I haven't enough stored covers to test the scraper.
The tests are standard phpunit tests, so run them with:
$ phpunit
And the coverage with (to run the covarage you will need php-xdebug):
$ phpunit --covarage-html covarage
Can be mainly found on tests/Utils/Scraper2Test.
Expected: 30 hours.
Reality: 20 hours.
| Task | Expected | Reality | Observations |
|---|---|---|---|
| Install everything and create Symfony Project | 1:00 | 1:00 | |
| Prepare database server | 1:00 | 0:15 | Everything went smoothly. |
| Feed doctrine model (including CRUD) | 4:00 | 1:30 | I spent some time with the search system. |
| Scraping service | 5:00 | 7:00 | Finally went from rss to web scraping, I made the work twice. |
| Homepage | 3:00 | 2:00 | |
| Frontend tasks (html, css...) | 4:00 | 4:00 | |
| Console command | 3:00 | 2:15 | |
| Tests | 9:00 | 2:00 | I did TDD so I take that time inside scraping service mainly. |