cohens_d gives different results from cohen.d function from package psych. #222
Comments
library(dplyr)
mtcars$am <- factor(mtcars$am)
sum <- mtcars %>%
group_by(am) %>%
summarise(across(
.cols = mpg,
.fns = list(mean = mean, sd = sd, n = length),
.names = "{fn}"
))
#> `summarise()` ungrouping output (override with `.groups` argument)
sum
#> # A tibble: 2 x 4
#> am mean sd n
#> <fct> <dbl> <dbl> <int>
#> 1 0 17.1 3.83 19
#> 2 1 24.4 6.17 13Using the following to get the estimate of the population’s (pooled) sd:
We get the same results from with(sum, {
d <- mean[1] - mean[2]
sp <- sqrt(((n[1] - 1) * sd[1] ^ 2 + (n[2] - 1) * sd[2] ^ 2) / (n[1] + n[2] - 2))
d / sp
})
#> [1] -1.477947
effectsize::cohens_d(mtcars$mpg, mtcars$am)$Cohens_d
#> [1] -1.477947However, in with(sum, {
d <- mean[1] - mean[2]
sp <- sqrt(((n[1] - 1) * sd[1] ^ 2 + (n[2] - 1) * sd[2] ^ 2) / (n[1] + n[2]))
d / sp
})
#> [1] -1.526417
psych::cohen.d(mtcars$mpg, mtcars$am)$cohen.d[2]
#> [1] 1.526417(and also subtracts the first mean from the second… But that would only change the sign.) I cannot find a source for using this formulation - so I'm not sure if this is a mistake, or deliberate on the part of |

|
Thanks. In my german statistics textbook, the formula for the pooled standard deviation is:
where I therefore get the same result as the psych package |


|
Isn't this related to the Bessel's correction? (I think it mentions it here) |
|
Yes, I would expect to use Bessel's correction, to estimate the populations Cohen's d. Without it, it would say @studerus what book are you using? Interesting that it uses the sample SD instead of the estimated population SD. @DominiqueMakowski I guess I can note this in the docs of cohens_d / pooled_sd? What do you think? |
|
@mattansb |
|
My book also says that you can calculate Cohen's d from the Pearson correlation with this formula:
where p and q are the proportions of the sample sizes of the two groups from the total sample. If I use the d that I calculated above and that you get with psych, I could confirm that I get r. With the estimate from effectsize package I get different results. |
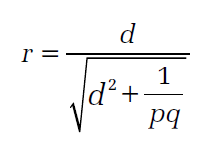
|
FWIW: effectsize::cohens_d(CO2$uptake, CO2$Treatment)$Cohens_d
#> [1] 0.6652288
-1 * psych::cohen.d(CO2[, c('uptake', 'Treatment')], 'Treatment')$hedges.g
#> uptake
#> 0.6652288Created on 2020-12-04 by the reprex package (v0.3.0) |
|
This might explain it:
Source: https://www.frontiersin.org/articles/10.3389/fpsyg.2013.00863/full |

|
Looking at McGrath, R. E., & Meyer, G. J. (2006). When effect sizes disagree: the case of r and d. Psychological methods, 11(4), 386., it seems that:
Which seems to be what However, as it is given in Harris Cooper, Larry V. Hedges, Jeffrey C. Valentine - The Handbook of Research Synthesis and Meta-Analysis-Russell Sage Foundation (2019) (and in any other places - see wikipedia, with all the references there):
Which is what we do here in Maybe we can add to The one "problem" I find here (which is unrelated to what @studerus brought here) is that the |
|
(If there's one thing you can't say about me, it's that I don't do my homework!) |
|
Okay here's what I've done:
@IndrajeetPatil Please see how this affects any of your code. |
|
Thanks for the heads-up! I think some tests for As for what the masses want, I am actually not sure. The first time we talked about this, we had compared results from |
I forgot about this!
Feel more like I'm off the deep end 🤪 Alright, closing... |
Here is an example:
gives 0.6652288
gives -0.6732924
When I calculate cohen's d manually, I can confirm the results of the psych package. So, it seems that the bug is in the effectsize package.
The text was updated successfully, but these errors were encountered: