Incorrect Assumption There Is A TCP Connection When There May Not Be #2750
Description
Basic Infos
Where there is an unreliable network connection the ESP8266 using the Arduino Core can get stuck in an endless loop waiting for a message that will never arrive.
Hardware
Hardware: ESP-12E
Core Version: All
Description
The effect of the problem is described in another thread that links to several instance reports. It happens often for me when the ESP is connected to a WiFi AP that uses a mobile phone network for its internet connectivity.
The failure is a consequence of an incorrect assumption that the ESP8266 knows whether it has a TCP connection. The assumption is correct when the TCP connection is created and destroyed in accordance with this state diagram
but can be invalid if there is packet loss once the TCP connection gets to the ESTABLISHED state shown in green in the diagram.
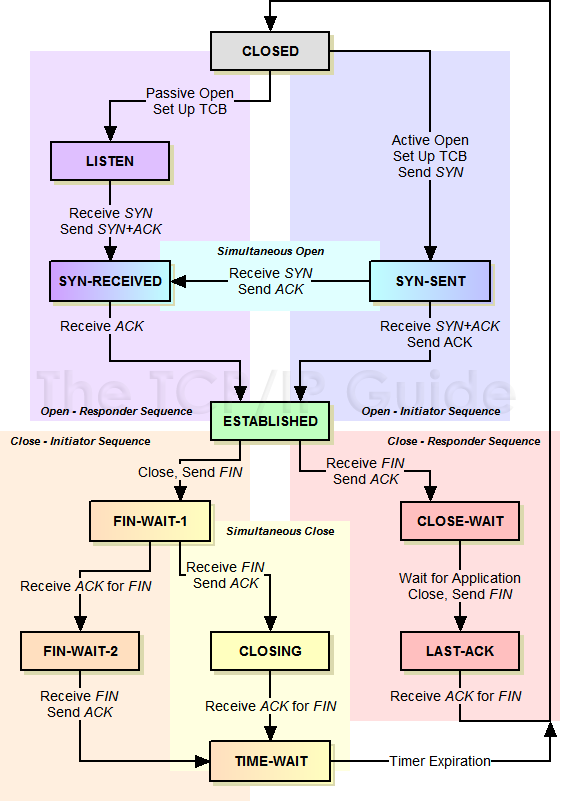
When lost packets are recovered in the TCP layer the state diagram is followed and when packets sent from the ESP are not acknowledged the ESP should know the TCP connection is broken but when the remote socket is closed incorrectly, perhaps through a power outage or packets have been sent from a remote socket but not received by the ESP it can not know. If packets are sent from the remote socket but not received, the remote machine will retry and eventually close its socket. If the ESP is waiting for incoming packets it will still think the TCP connection exists when it doesn't.
The Arduino core relies on the ESP knowing whether it has a TCP connection. An example is WiFiClient::connected() in WiFiClient.cpp where it concludes that there is a TCP connection when the TCP state is ESTABLISHED but ESTABLISHED means there has been a TCP connection, not necesarily that it still exists. In the WiFiClient.ino example client.available() is used to decide if a TCP connection exists and this function can return true when the TCP connection has been lost. Similarly in BasicHttpClient.ino it calls http.GET() which calls sendRequest which calls handleHeaderResponse() in which a loop is controlled with the erroneous connected() function that may return true when there is no TCP connection and hence loop forever.