https://arxiv.org/abs/2403.17379
Etash Jhanji's code relating to project submission for PJAS and PRSEF science fairs
Sentiment analysis is a continuously explored area of text processing that deals with the computational analysis of opinions, sentiments, and subjectivity of text. However, this idea is not limited to text, in fact, it could be applied to other modalities. In reality, humans do not express themselves in text as deeply as in speech or music. The ability of a computational model to interpret musical emotions is not as deeply explored and could have implications and uses beyond a computation discovery, in uses for therapy and music queuing.
Using the Emotion in Music Database (1000 songs), I can take 0.5-second clips of songs that are linked to continuous arousal and valence annotations on Russel's circumplex model of affect on scales from -1 to 1 as seen in this image. I trained two RNN/LSTM models. One takes a mel spectrogram of the 0.5-second audio clip and can predict the arousal and valence of that clip. The other model can predict the next arousal and valence values when given a sequence of 10 vectors.
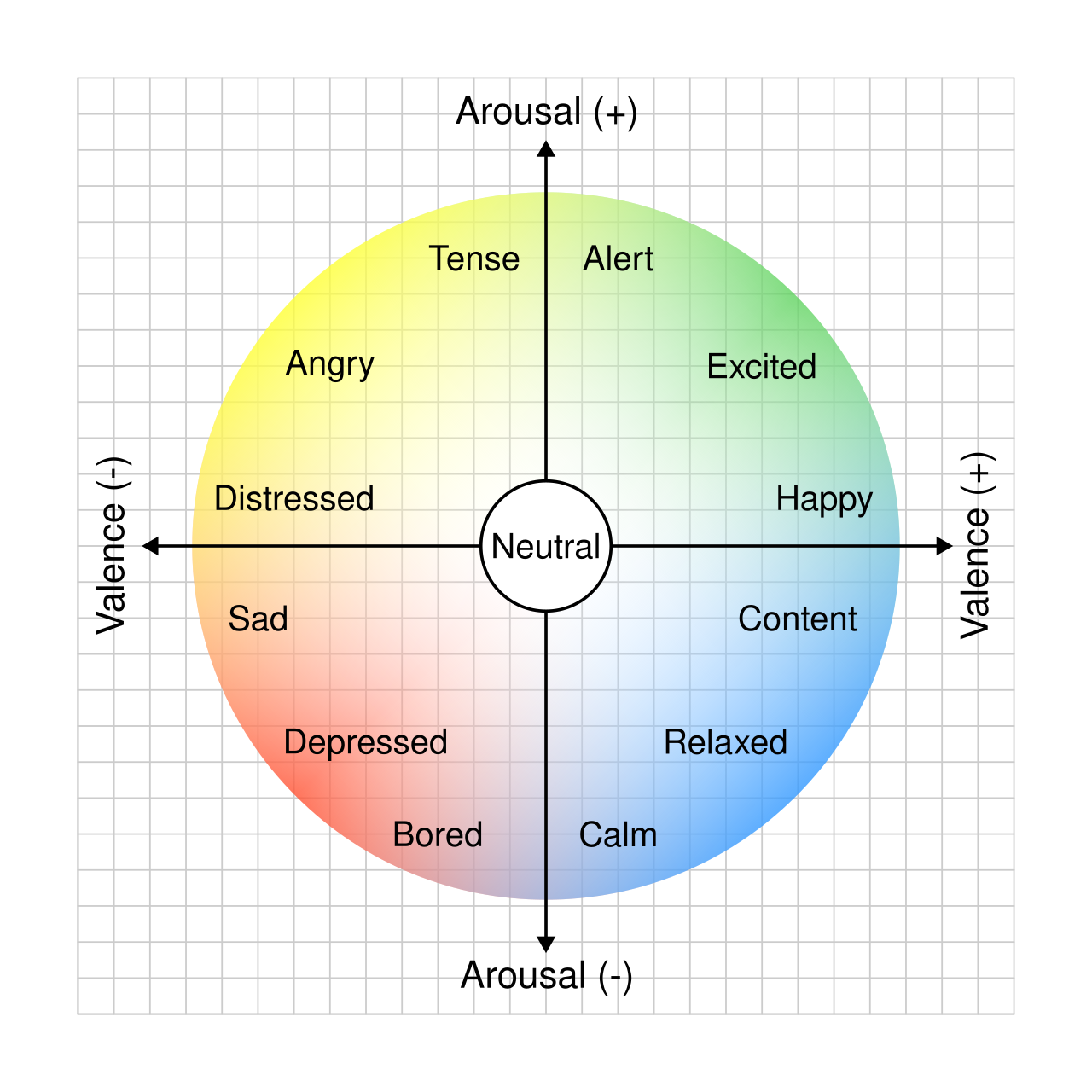{kind=link}
The emotion prediction model got an MSE loss of about 0.054 in validation and 0.044 in training meaning that RMSE are 0.232 and 0.21, respectively. These RMSE values can be accounted for by the natural variation in even human choice annotation of this data. In the dataset, the 10 volunteers per song each had unique annotations which were averaged for the continuous values. The average standard deviation of these continuous human annotations themselves was 0.3.
The "next value" predictor model showed an MSE of about 0.0004 for training and 0.0005 in validation. These results indicate that the model performed well.
I would like to express my gratitude for the EmoMusic database which is completely open source and was immensely helpful in this project
[1] M. Soleymani, M. N. Caro, E. M. Schmidt, C.-Y. Sha, and Y.-H. Yang, “1000 Songs for Emotional Analysis of Music,” in Proceedings of the 2Nd ACM International Workshop on Crowdsourcing for Multimedia, 2013, pp. 1–6. doi: 10.1145/2506364.2506365.
[2] F. Eyben, F. Weninger, F. Gross, and B. Schuller, “Recent Developments in openSMILE, the Munich Open-source Multimedia Feature Extractor,” in Proceedings of the 21st ACM International Conference on Multimedia, 2013, pp. 835–838. doi: 10.1145/2502081.2502224.
To replicate these results you must request the dataset from this link. You can then install requirements, make the dataset, and train models.
pip install requirements.txt
scripts Directory
scripts/demo.py: Potential implementation of aSongclass to host the model(s) and be released as a package- Implements the
Songclass with methodsgetEmotions(),predictNext(), andisNext()and shows example usage - More details included in comments of the file
- Implements the
scripts/models.py: Hosts both models so they can be imported to thedemo.pyclass and training filesscripts/emotion_train.py: Train the emotion predictor to predict arousal and valence values from mel spectrogram datascripts/predictor_train.py: Train an LSTM model to predict the next pair of arousal and valence values from 10 existing pairs/vectorsscripts/linreg_predictor.py: Show a (simpler) linear regression implementation of the predictor model
scripts/data_preparation Directory
scripts/data_preparation/audio_process.py: Housekeeping to check sample rate of audio filesscripts/data_preparation/create_dataset.py: Created HDF5 with Mel Spectrogram data prior to training to save timescripts/data_preparation/resample.sh: Bash script to resample audio to be 44.1kHz
scripts/plotting Directory
scripts/plotting/plot_single.py: Plot the arousal and valence values over time from a single song from the datasetscripts/plotting/plot_all.py: Plot all of the arousal and valence values of every song over time
models Directory
models/model.pth: The saved model fromemotion_train.pyto predict emotions from mel spectrogramsmodels/model_state_dict.pth: The saved model state dictionary fromemotion_train.pyto predict emotions from mel spectrogramsmodels/predictor.pth: The saved model frompredictor_train.pyto predict next arousal and valence vectormodels/predictor_state_dict.pth: The saved model state dictionary frompredictor_train.pyto predict next arousal and valence vector
results Directory
results/loss.png: Loss graph from emotion modelresults/loss.json: Loss for training and validation over epochs from emotion modelresults/predictor_loss.png: Loss graph from predictor modelresults/predictor.json: Loss for training and validation from predictor model
{kind=link}
{kind=link}