Add example to compare RELU with SELU #6990
Conversation
|
So SELU is significantly worse than ReLU on this example? |
|
Yes. Which is also what @bigsnarfdude sees in bigsnarfdude/SELU_Keras_Tutorial |
|
In the paper they use more layers to show that a self normalizing neural net could work better. I guess you should add more layers to fully test the claim this work. |
|
So I repeated with: and I got no appreciable improvement:
|

|
In theory, normalization is only useful when you have very deep networks; it helps with gradient propagation. Try less dropout, more layers, and training longer. You could also use smaller layers but more of them. What's the likelihood that we're dealing with an implementation bug? |
|
In the paper the dropout rate range is .05-.1, inputs are standardized, kernel initializer is lecun_uniform and the optimizer is pure sgd. Maybe this can help... |
|
Good catch. I'll make those changes and try again. I'll also read the paper
to see what MLP architecture parameters they used.
@fchollet: Not sure if we can say if it's an implementation bug or not
until we try to replicate results from the paper.
…On Wed, Jun 14, 2017 at 6:49 PM drauh ***@***.***> wrote:
In the paper the dropout rate range is .05-.1, inputs are standardized,
kernel initializer is lecun_uniform and the optimizer is pure sgd. Maybe
this can help...
—
You are receiving this because you authored the thread.
Reply to this email directly, view it on GitHub
<#6990 (comment)>, or mute
the thread
<https://github.com/notifications/unsubscribe-auth/AGAO_LMrqtbE8j0S2wv2OaMWoyb8QafZks5sEGN4gaJpZM4N6XF->
.
|
|
The reduced size helped with the overfitting issue. The reduced dropout and |
|
Try the baseline network (relu) with both |
The latest code with: kernel_initializer='lecun_normal' graph below
|

|
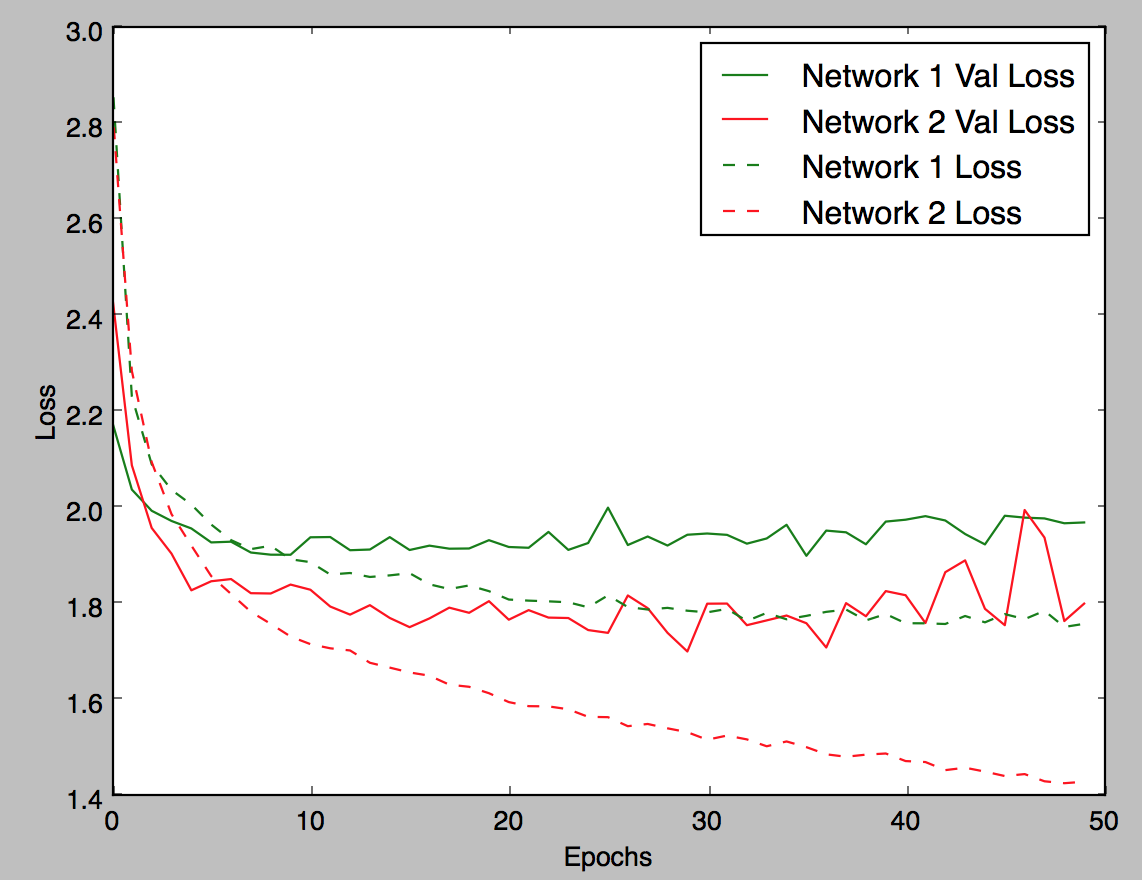
Looks like it's overfitting pretty badly, it starts overfitting at epoch 1 (selu version). Maybe increase dropout or reduce layer size? |
|
Thanks @bigsnarfdude ! So making a side by side comparison with some of the parameters: Effect of initializer:
|

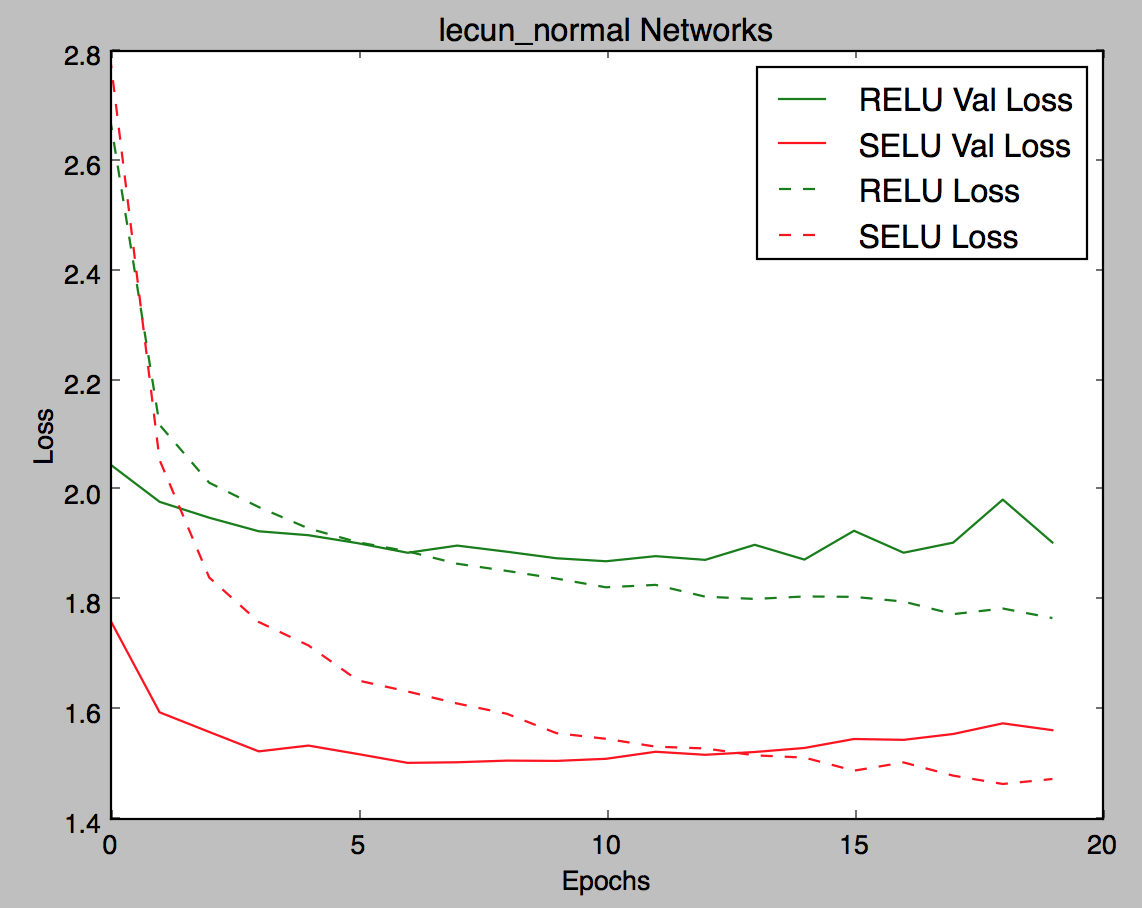


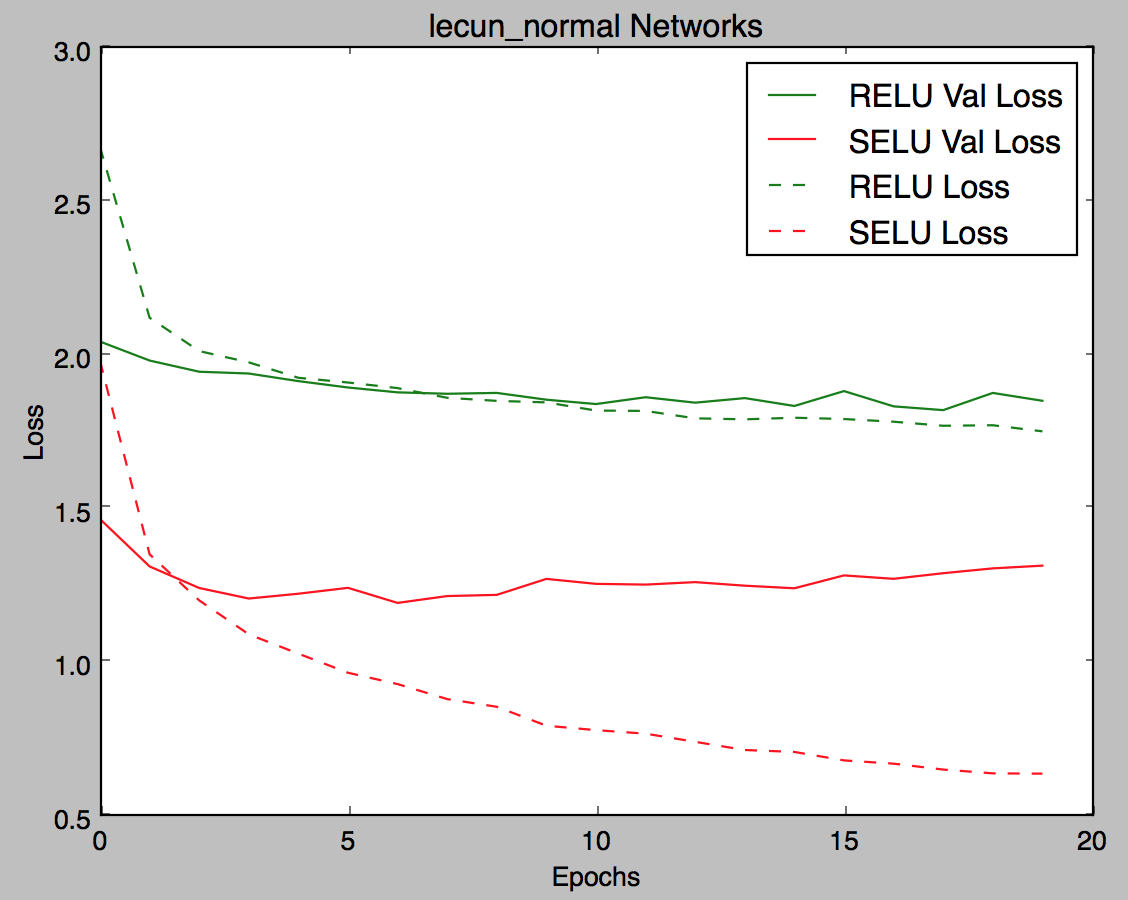
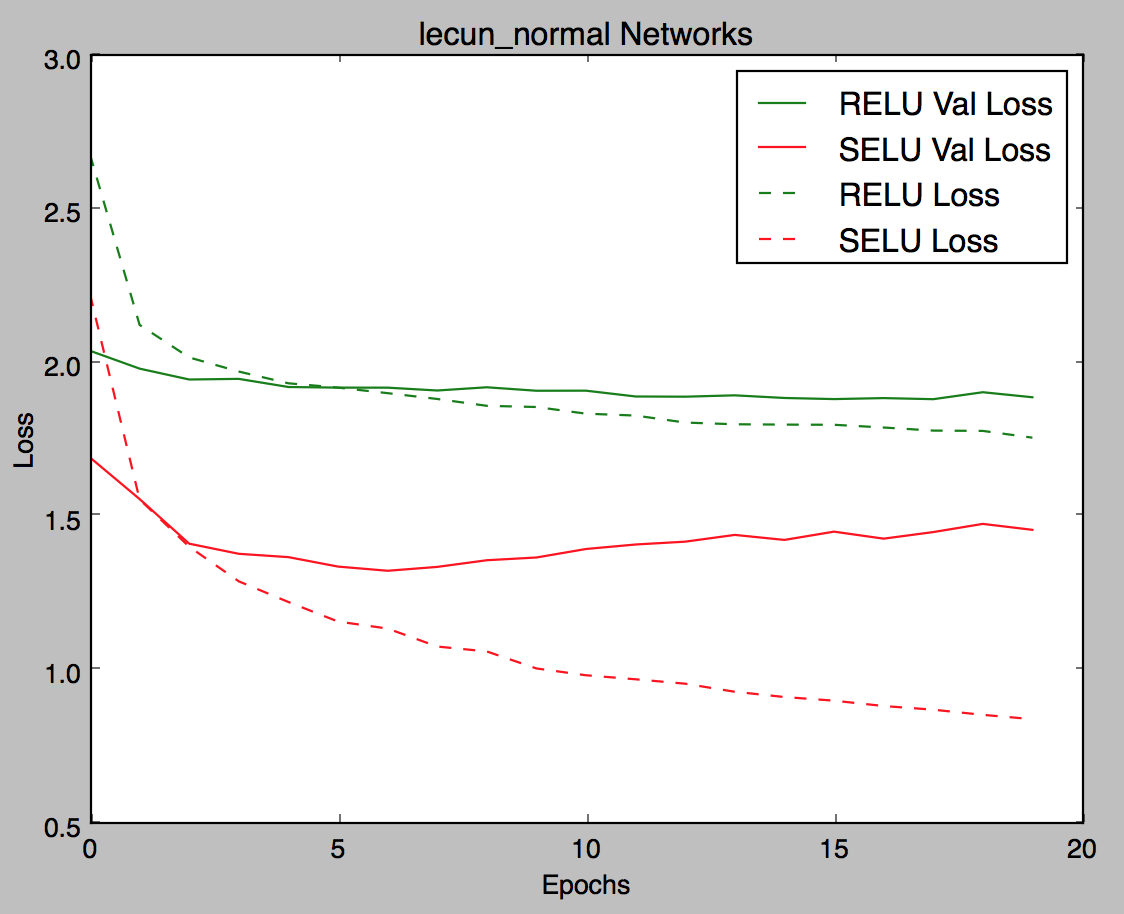



|
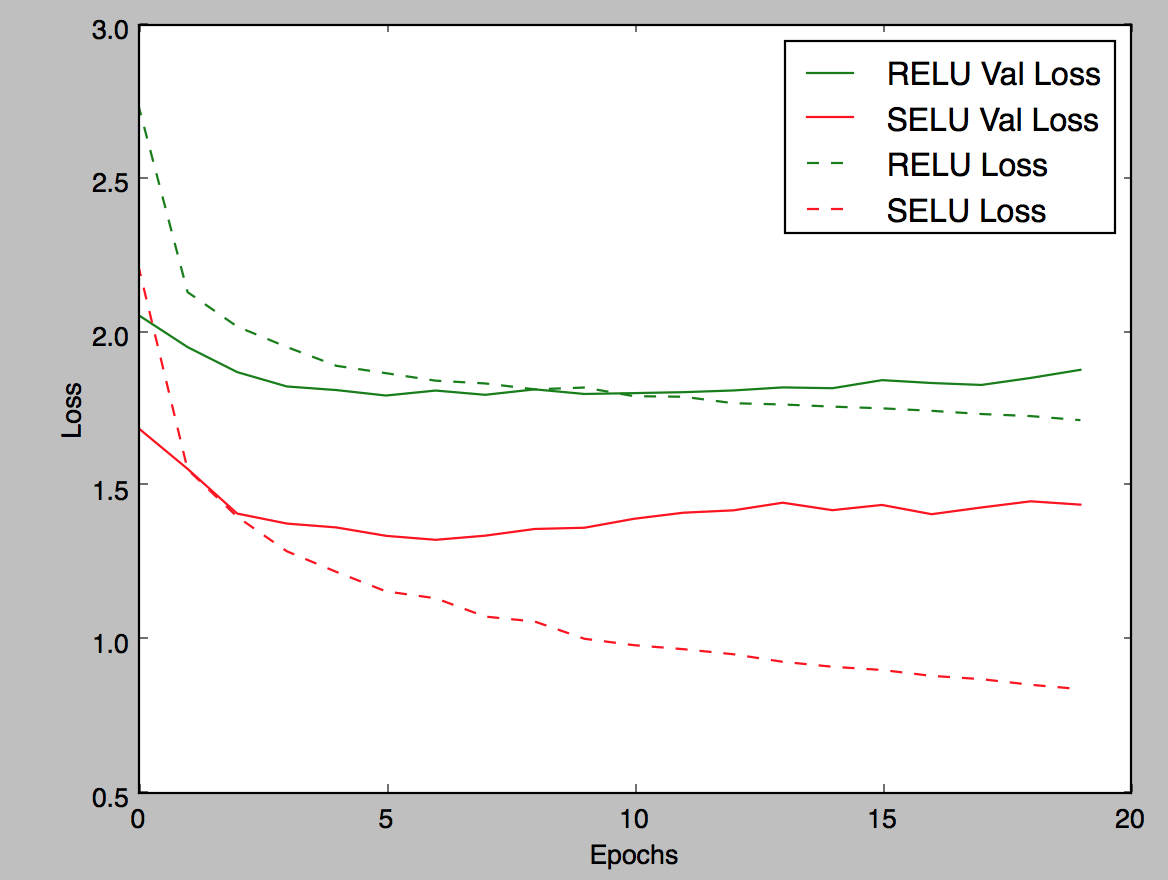
Graph for 222f613:
It does seem like synergize well together and the naive implementations are prone to dismissing it. I still think the net is overfitting. What do you think @bigsnarfdude @fchollet? |
|
@fchollet I think there might be some value in making this a command-line executable script with default arguments (using
Will make the above graphs reproducible. Opinions? |
|
Certainly, it is good to fully parameterize the models in order to be able to run different configurations by only changing one variable. But the advantages of having access to command line arguments vs. just editing global variables at the beginning of a file, are slim. I'd recommend just having a list of global parameters, with reasonable defaults. We could even make layer depth a configurable parameter. |
|
Commit 86e16ff:
|
| 'dropout': AlphaDropout, | ||
| 'dropout_rate': 0.1, | ||
| 'kernel_initializer': 'lecun_normal', | ||
| 'optimizer': 'sgd' |
There was a problem hiding this comment.
Not sure how fair the comparison is, if using a different optimizer and different dropout rate...
There was a problem hiding this comment.
I can set the optimizer to sgd in both.
What do you recommend we do with dropout? To be fair, they are not comparable 1-1 anyways (i.e Dropout(0.5) ≠ AlphaDropout(0.5))
There was a problem hiding this comment.
They performed grid search, so I'm wondering if its possible to do apple to apple comparisons as it looks we are hand tuning the SELU/SSN parameters.
Best performing SNNs have 8 layers, compared to the runner-ups ReLU networks with
layer normalization with 2 and 3 layers ... we preferred settings with a
higher number of layers, lower learning rates and higher dropout rates
| @@ -0,0 +1,153 @@ | |||
| ''' | |||
There was a problem hiding this comment.
Please start file with a one-line description ending with a period.
examples/reuters_mlp_relu_vs_selu.py
Outdated
| kernel_initializer: str. the initializer for the weights | ||
| optimizer: str/keras.optimizers.Optimizer. the optimizer to use | ||
| num_classes: int > 0. the number of classes to predict | ||
| max_words: int > 0. the maximum number of words per data point |
There was a problem hiding this comment.
Docstring needs a # Returns section
examples/reuters_mlp_relu_vs_selu.py
Outdated
| optimizer='adam', | ||
| num_classes=1, | ||
| max_words=max_words): | ||
| """Generic function to create a fully connect neural network |
There was a problem hiding this comment.
"fully-connected". One-line description must end with a period.
examples/reuters_mlp_relu_vs_selu.py
Outdated
|
|
||
|
|
||
| score_model1 = model1.evaluate(x_test, y_test, | ||
| batch_size=batch_size, verbose=1) |
There was a problem hiding this comment.
One line per keyword argument (to avoid overly long lines), same below
|
@zafarali , @bigsnarfdude |
SELU was added in #6924.
This PR adds a script to compare RELU and SELU performance in an MLP