Learn Big Data through its Python (PySpark) API by running the Jupyter notebooks with examples on how to read, process and write data.


| Application | URL |
|---|---|
| Hadoop | localhost:9870 |
| MapReduce | localhost:8089 |
| HUE | localhost:8088 |
| Mongo Cluster | localhost:27017 |
| Kafka Manager | localhost:9000 |
| JupyterLab | localhost:8888 |
| Spark Master | localhost:8080 |
- Install Docker and Docker Compose
- Download the source code or clone the repository
- Build the cluster
docker-compose up -d
./config.sh- Remove the cluster by typing
docker-compose down

The default Docker setup on Windows and OS X uses a VirtualBox VM to host the Docker daemon. Unfortunately, the mechanism VirtualBox uses to share folders between the host system and the Docker container is not compatible with the memory mapped files used by MongoDB (see vbox bug, docs.mongodb.org and related jira.mongodb.org bug). This means that it is not possible to run a MongoDB container with the data directory mapped to the host.
– Docker Hub (source here or here)
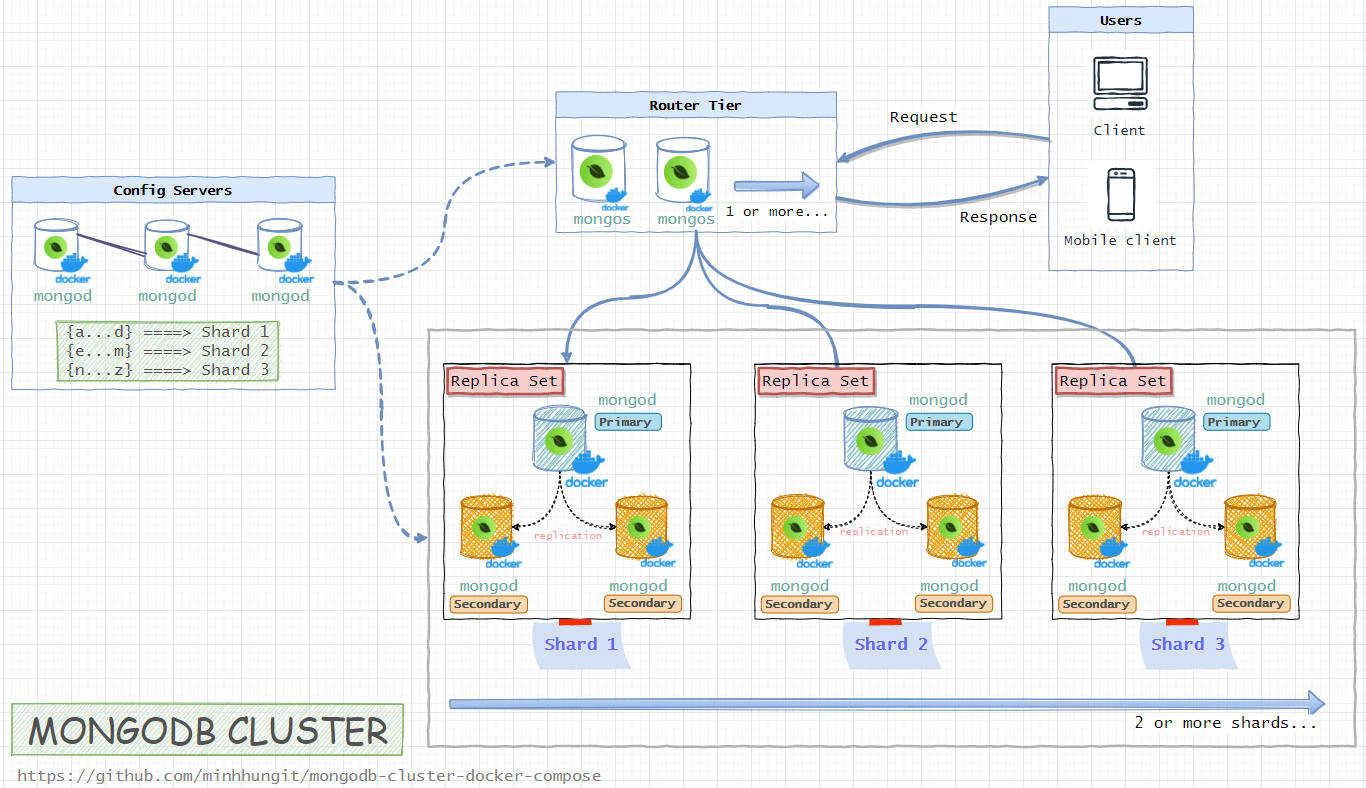
- Config Server (3 member replica set):
configsvr01,configsvr02,configsvr03 - 3 Shards (each a 3 member
PSSreplica set):shard01-a,shard01-b,shard01-cshard02-a,shard02-b,shard02-cshard03-a,shard03-b,shard03-c
- 2 Routers (mongos):
router01,router02