2019_vql
The latest release version of VIATRA is 2.1.1. It is formerly known as EMF-IncQuery.
VIATRA will be available in Eclipse Oxygen Modeling Tools distribution by deafult.
![]()
homepage: https://www.eclipse.org/viatra/
Navigate to the homepageof VIATRA and search for update sites at the download page: https://eclipse.org/viatra/downloads.php
Find the VIATRA release update site and copy it to your clipboard (don't leave white space): http://download.eclipse.org/viatra/updates/release
Switch back to your Eclipse instance and select the Help/Install New Software...
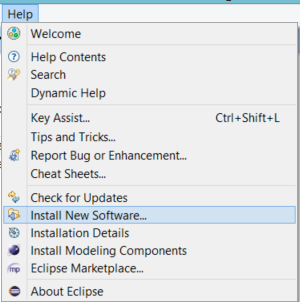
Paste the copied URL to the Work with field, than press Enter. When the view is updated, select the VIATRA Query and Transformation SDK. Tick the Contact all update sites during install... field. Press Next, then Next and finally Finish. After the install process, you should restart Eclipse.
For a faster installation, advanced users can untick the Contact all update sites during install... field, but they may have to install Xtend and Xtext technologies manually.
-
Clone and import the following projects from this git repository: https://github.com/FTSRG/mdsd-examples
hu.bme.mit.mdsd.erdiagram hu.bme.mit.mdsd.erdiagram.examplediagrams hu.bme.mit.mdsd.erdiagram.example -
Create a new Query Project and name it to
hu.bme.mit.mdsd.erdiagram.queries. -
Add dependency to the
hu.bme.mit.mdsd.erdiagramproject using the manifest file. -
Create a new query definition in a package named
hu.bme.mit.mdsd.erdiagram.queriesand a file namedqueries.vql. Also add two simple queries (and don't forget to save and build):package hu.bme.mit.mdsd.erdiagram.queries // The following imports the ecore model, // you can use auto-completion by hitting ctrl+space after the quotation mark import "hu.bme.mit.mdsd.erdiagram" pattern entity(e : Entity) { Entity(e); } pattern entityName(entity : Entity, name) { Entity.name(entity, name); }
If you did not add the dependency to the erdiagram project an error will appear at the import statement. A quick fix is available to add the dependency.
As you can see, every pattern have a unique name and several parameters. Each parameter has a type which can be omitted but recommended to add it explicitly. Inside the body of the patterns, there are different constraints. Our first example describes a type constraint and the second one a feature constraint. It states that entity variable is of eClass Entity and its name attribute is the value of name variable.
Query Results is the primary tool for debugging VIATRA queries during development. To open the view: Window/Show View/Others -> VIATRA/Query Results or you can simply press the CTRL + 3 shortcut and start to type the name of the view.
To use this view, we have to load an instance model and a set of queries into the view:
- Open our example instance model (My.erdiagram) with the Sample Reflective Ecore Model editor.
- Click the green arrow button on the view to load the instance model into the view.
- Make sure to save and leave the focus on the opened queries.vql file.
- Press the other green arrow button on the view to load the queries.

In the upper panel of the view you can examine the model and the configuration of the Query engine (use the ReteEngine for this laboratory). In the bottom panel of the view you can see the matches of the queries. Currently there are no matches - this is because the view does not know about the metamodel (ecore model) and cannot connect the model and the queries. You have two options here:
- Either start a runtime eclipse and load the instance model and the queries there (after importing the project to the runtime workspace).
- Or turn on dynamic mode which will use strings to find matches in the model: Window/Preferences/VIATRA/Query Explorer and tick the dynamic EMF check box. You will have to unload and reload the model and the queries after this configuration.
Now you can see all the matches. Also check out the context menu.

-
To get familiar with the language let's write a few validation queries, ill-formedness constraints and well-formedness constraints. First, create a query to check if the name of a
NamedElementis only an empty string:pattern unnamedElement(element : NamedElement) { NamedElement.name(element, ""); }
This pattern shows, that constant attribute value literals can be typed immediately in the parameters list. What we would really like to capture, though, is named elements that either have an empty name, or no name assigned at all:
pattern unnamedElement(element : NamedElement) { NamedElement.name(element, ""); } or { neg NamedElement.name(element, _); }
This required a disjunction (
or) with a second pattern body. The new body captured elements of type NamedElement, for which no string exists at all that would satisfy aNamedElement.namerelationship - in other words, this attribute slot is unfilled. Instead of a pattern variable (likeelement) or a concrete constant literal (like""), here we used_, which denotes an arbitrary, unspecified value; this is why the negated constraint means "no matter which string you are thinking about, it is not the name of this element". -
Create a query to check if the name starts with a non-capital letter:
pattern entityStartsWithLowerCase(entity) { Entity.name(entity, name); check (!name.matches("^[A-Z].+")); }
This pattern shows the
checkblock where you can write a wide range of Xbase expressions (similar to Java). In this case, we define a regular expression. A possible alternative would have beencheck(name.toFirstUpper != name)- this demonstrates Xbase extension methods as well. -
Create a query to check if two entities have the same name:
pattern entityNameAmbiguity(entity1, entity2, commonName) { Entity.name(entity1, commonName); Entity.name(entity2, commonName); entity1!=entity2; }
This pattern shows the
!=(not equal) operator to select two different entities from the instance model. One can also use the==operator for testing equality - but in this case, we can do the job by simply using the same pattern variablecommonNametwice.Note that formulated this way, the query is inefficient, as it will compare any two entities, which has a cost quadratic in the size of the model. A more efficient (linear-cost) solution would count the number of entities for each entity name, and then report entities that have names that have been counted more than once:
pattern entityNameAmbiguity(entity : Entity, name : java String) { Entity.name(entity, name); howManyWithSameName == count Entity.name(_, name); check(howManyWithSameName > 1); }
We have used the
countmodifier, which is an example of an aggregator. It aggregates a single value from the different possible matches of the pattern constraint associated with it. There are other aggregators as well, such assum,max, etc.. Similarly, there is also the special modifiernegthat we have used earlier; it checks for there being no matches at all for the associated constraint. -
Attributes are not required to have unique names in general, but attributes of a single entity are. So name ambiguity must be tested by counting attributes of the same name and within the same entity, which requires a helper pattern:
pattern attributeNameAmbiguity(attribute : Attribute, name : java String) { find attributeQualifiedName(entity, attribute, name); howManyWithSameName == count find attributeQualifiedName(entity, _, name); check(howManyWithSameName > 1); } pattern attributeQualifiedName(entity : Entity, attribute : Attribute, name : java String) { Entity.attributes(entity, attribute); Attribute.name(attribute, name); }
-
The previous queries were well-formedness constraints, which, perhaps surprisingly, captured the cases where the model is ill-formed. Now let's create a query that explicitly looks for well-formed elements.
This pattern shows how to reuse previously defined patterns as sub patterns. To do this, we use the
findkeyword then write the id of the sub pattern and finally add the variables. (Variables starting with_define don't care variables, hence you cannot use them in other lines of the pattern).Again, we use the
orkeyword that states the pattern has a match if the first or the second or the third or etc body has a match.pattern badEntity(entity) { find emptyNamedElement(entity); } or { find entityStartsWithSmallCase(entity); } or { find sameNamedEntities(entity, _, _); }
The whole model is considered well-formed (with respect to entities, at least) if there are no entities that satisfy any ill-formedness patterns, hence there are no matches of the query
badEntity. For that, we can use the familiarnegkeyword, combined withfindthis time.pattern wellFormedEntites() { neg find badEntity(_); }
-
Next, create a well-formedness constraint for
Relations, checking if it has bothRelationEndings. This will need a helper pattern.// It is required to have at least one positive constraint on a variable - in this case r is a Relation: pattern relationWithoutEnding(r : Relation) { neg Relation.leftEnding(r, _); } or { neg Relation.rightEnding(r, _); } pattern wellFormedRelation() { N == count find relationWithoutEnding(_); N == 0; }
Notice, that using
negis equal to using thecountkeyword and ensure it evaluates to zero. -
We can also get the number of attributes of an entity:
pattern attributeCount(e: Entity, num: java Integer) { Entitiy(e); // optional, this is already expressed in the parameter line num == count Entity.attributes(e, _); }
-
Let's find the entity that is first in the alphabet:
pattern hasBiggerName(e1, e2) { Entity.name(e1, name1); Entity.name(e2, name2); check(name1 > name2); } pattern firstEntity(e : Entity) { neg find hasBiggerName(e, _); }
The above technique is also useful when you can have two matches that are exactly the same, only the order of the parameters are different. The
check(name1 > name2);expression will determine the order and hence only one of the matches will available in the result set. Again, just like in the name collision example, this solution is quadratic and should be refactored to be linear (using the aggregatormin). -
Let's find all the super entities of an entity by using transitive closure.
pattern directSuperEntity(e, superEntity) { Entity.isA(e,superEntity); } pattern transitiveSuperEntity(e, superEntity) { find directSuperEntity+(e, superEntity); }
VIATRA provides facilities to create validation rules based on the pattern language of the framework. These rules can be evaluated on various EMF instance models and upon violations of constraints, markers are automatically created in the Eclipse Problems View.
The @Constraint annotation can be used to mark a pattern as a validation rule. If the framework finds at least one pattern with such annotation, a .validation project will be generated.
Annotation parameters:
- key: The parameters, which the constraint violation needs to be attached to.
-
message: The message to display when the constraint violation is found. The message may refer the parameter variables between $ symbols, or their EMF features, such as in
$Param1.name$ . - severity: "warning" or "error"
- targetEditorId: An Eclipse editor ID where the validation framework should register itself to the context menu.
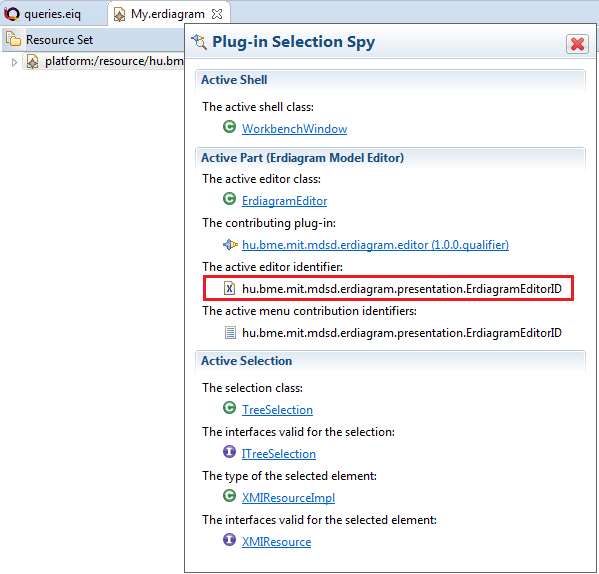
To find a specific editor id, the Plug-in Selection Spy tool can be used with a SHIFT + ALT + F1 shortcut. Or you can just check plugin.xml in hu.bme.mit.mdsd.erdiagram.editor project.
Create a constraint, using the sameNamedEntities pattern (intentionally using the first version):
@Constraint(
key = {entity1, entity2},
severity = "error",
message = "Two entities has the same name $commonName$.",
targetEditorId = "hu.bme.mit.mdsd.erdiagram.presentation.ErdiagramEditorID"
)
pattern sameNamedEntities(entity1, entity2, commonName) {
Entity.name(entity1, commonName);
Entity.name(entity2, commonName);
entity1 != entity2;
}After build a .validation plugin project will be generated. Let's start a runtime Eclipse to install the validation plugin. After opening the model, select VIATRA Validation | Initialize VIATRA Validators on Editor.
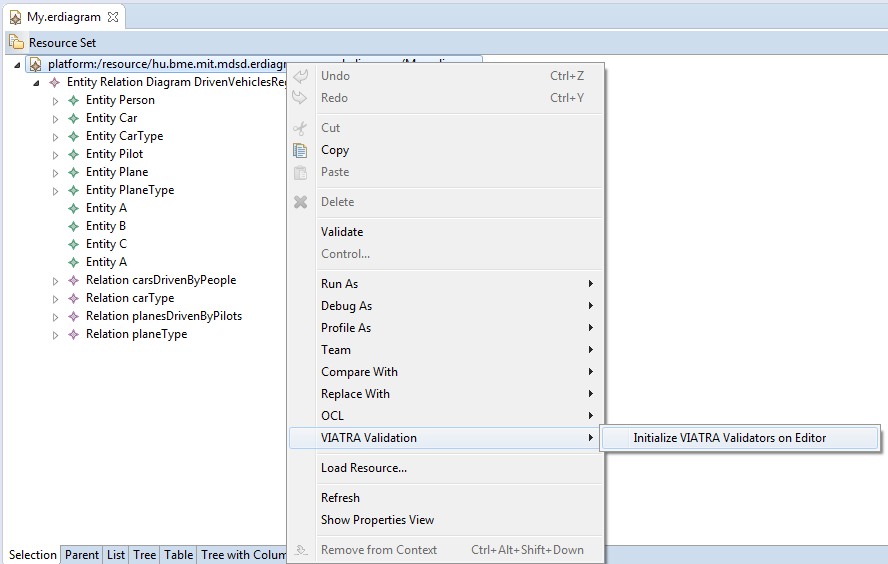
The following errors should appear (if you double click on the error, it will select the problematic EClasses):

The two errors mark the same error. To solve this, add the following parameter to the constraint annotation:
symmetric = {entity1, entity2}
After that, it will work as intended:

Of course, this symmetry problem will not come up with the count-based solution.
Let's create a derived feature between the RelationEndings, which returns the other RelationEnding of their parent Relation. For that the following three steps are required:
- Define a one way relation between
RelationEndings with multiplicity of [0..1] and name itotherEnding. Then set the following attributes of the feature:
- derived = true (to indicate that the value of the feature is computed from the model)
- changeable = false (to remove setter methods)
- transient = true (to avoid persisting the value into file)
- volatile = true (to remove the field declaration in the object)

Don't forget to save the model, reload the genmodel and regenerate the model code!
- VIATRA supports the definition of efficient, incrementally maintained, well-behaving derived features in EMF by using advanced model queries and incremental evaluation for calculating the value of derived features and providing automated code generation for integrating into existing applications.
The @QueryBasedFeature annotation can be used to mark a pattern as a derived feature realization. If the framework can find out the feature from the signature of the pattern (patter name, first paramter type, second paramter type), the annotation parameters can be empty.
Annotation parameters:
-
feature ="featureName" (default: pattern name) - indicates which derived feature is defined by the pattern
-
source ="Src" (default: first parameter) - indicates which query parameter (using its name) is the source EObject, the inferred type of this parameter indicates which EClass generated code has to be modified
-
target ="Trg" (default: second parameter) - indicates which query parameter (using its name) is the target of the derived feature
-
kind ="single/many/counter/sum/iteration" (default: feature.isMany?many:single) - indicates what kind of calculation should be done on the query results to map them to derived feature values
-
keepCache ="true/false" (default: true) - indicates whether a separate cache should be kept with the current value. Single and Many kind derived features can work without keeping an additional cache, as the VIATRA RETE network already keeps a cache of the current values.
Let's create the pattern, which finds the other ending and annotate it with
QueryBasedFeature:@QueryBasedFeature pattern otherEnding(ending : RelationEnding, other : RelationEnding) { Relation.leftEnding(relation, ending); Relation.rightEnding(relation, other); } or { Relation.rightEnding(relation, ending); Relation.leftEnding(relation, other); }
Save and build. VIATRA will modify the Ecore model with an annotation.

- Reload the ecore model for the genmodel and regenerate the model code. Now if you use the
relationEnding.getOtherEnding()on the model, it will return the correctRelationEnding. Note that you will need additional initialization code for VIATRA, or run it as a JUnit Plug-In test. You can also check that it is working by using the generated tree editor in a runtime eclipse.
Let's say we want the instance model editor tree to display attributes with labels indicating both their name and their type. There is currently no single label feature that can fulfill this role, so we have to define a derived attribute for this purpose. We can follow a procedure similarly to the previous one:
- Define an
EString-valued EAttribute calledlabelin the EClassAttribute, with multiplicity of [0..1] (default). Set the following properties, as before:
- derived = true (to indicate that the value of the feature is computed from the model)
- changeable = false (to remove setter methods)
- transient = true (to avoid persisting the value into file)
- volatile = true (to remove the field declaration in the object)
-
Don't forget to save the model, reload the genmodel and regenerate the model code!
-
Add the following VQL code to the query project:
@QueryBasedFeature
pattern label(attribute : Attribute, label : java String) {
find attributeNameOrPlaceHolder(attribute, name);
Attribute.type(attribute, type);
label == eval (name + ": " + (type as Object).toString);
}
private pattern attributeNameOrPlaceHolder(attribute : Attribute, name : java String) {
Attribute.name(attribute, name);
} or {
neg Attribute.name(attribute, _);
name == "(unnamed)";
}Save and build. VIATRA will modify the Ecore model with an annotation.
-
Reload the ecore model for the genmodel. Select the genmodel element for
Attribute, and set its "label feature" property (in category "Edit") to the new derived attributelabel. Save, and regenerate model & edit & editor code. -
Enjoy your new tree editor with nicer labels for attributes :)
-
Create a pattern that detects a circle in the type hierarchy:
pattern circleInTypeHierarchy(entity) { find transitiveSuperEntity(entity, entity); }
-
Create a pattern that detects a (transitive) diamond in the type hierarchy. Also make sure that it doesn't have more than one matches representing the same diamond:
pattern diamondInTypeHierarchy(entity1, entity2, entity3, entity4) { find transitiveSuperEntity(entity1,entity2); find transitiveSuperEntity(entity1,entity3); find hasBiggerName(entity2, entity3); //entity2 != entity3; find transitiveSuperEntity(entity2,entity4); find transitiveSuperEntity(entity3,entity4); }
-
Extend the patterns to get the inherited relations and attributes too:
pattern attribute(entity, attribute) { Entity.attributes(entity,attribute); } or { find transitiveSuperEntity(entity, superEntity); find attribute(superEntity, attribute); }
and
pattern relation(entity1, entity2) { Relation.leftEnding.target(relation, entity1); Relation.rightEnding.target(relation, entity2); } or { find transitiveSuperEntity(entity1, superEntity); find relation(superEntity, entity2); // recursion - not necessary here, just for demo }
You can these the projects in this repository by checking out the VQL branch.
- Tutorial: https://www.eclipse.org/viatra/documentation/tutorial.html
- Pattern Language: https://www.eclipse.org/viatra/documentation/query-language.html
- Validation Framework, Query-based Features: https://www.eclipse.org/viatra/documentation/addons.html