runtime: mark termination is slow to restart mutator #45894
Comments
|
Thanks for the really detailed report! I think your analysis of the situation makes a lot of sense. Maybe we can do something more clever about flushing mcaches. Honestly,
This must happen before the next GC cycle; we can delay the whole process until sweep termination but then that just pushes the problem somewhere else. CC @prattmic |
|
Change https://golang.org/cl/315171 mentions this issue: |
|
I think you're right that this is best addressed with a change to how the runtime prepares for sweep. A secondary effect of this is that a user goroutine can end up on the hook for several milliseconds of work (when GOMAXPROCS is large), if they happen to be doing an assist at the end of mark. But because it's not quite May 1st (and with it the Go 1.17 freeze) in my time zone, I sent a proposal (CL 315171 above) to change forEachP to release and re-acquire the lock between every call to the provided function. It looks like |
|
It occurs to me that what I laid out earlier is basically what |
|
One idea that came up in brainstorming with @mknyszek is that we could potentially have This has the advantage of allowing all of the runnable Gs to get going first after STW and only afterwards start worrying about the idle Ps. In general, I don't think we'd move cost to the start of the next GC, because we should handle all the idle Ps as long as we run out of work on one M at something point. And if we never run out of work, there shouldn't be any idle Ps at all. The biggest downside to this is more complexity in the scheduler, where we've been trying to reduce complexity. There's also an argument that having the GC flush all of the idle Ps could reduce latency to start a P, but in practice I don't think that makes much difference (and is obviously the opposite case in this bug). |
|
I have a reproducer. It's in the form of a benchmark for ease of setup, though it's not exactly a benchmark. The code is at the bottom, and I've included a few screenshots of execution traces that it generates. (The benchmark tries to calculate some measures of how often the application code is able to run, but the main value is in looking at the execution traces.) This issue is a combination of a few circumstances:
Data from The execution traces below (from the reproducer at the very bottom) show the difference in speed between procresize+startTheWorldWithSema resuming lots of Ps (fast) and relying instead on the mspinning mechanism to get back to work (slow). These traces are from a server with two Intel sockets and a total of 96 hyperthreads. I've zoomed them all so the major time divisions are at 5ms intervals. Here's go1.16.3 with a fast resume during the start of mark. When there are a lot of active Ps right before the STW, the program is able to have a lot of active Ps very soon after the STW. This is good behavior -- the runtime is able to deliver.
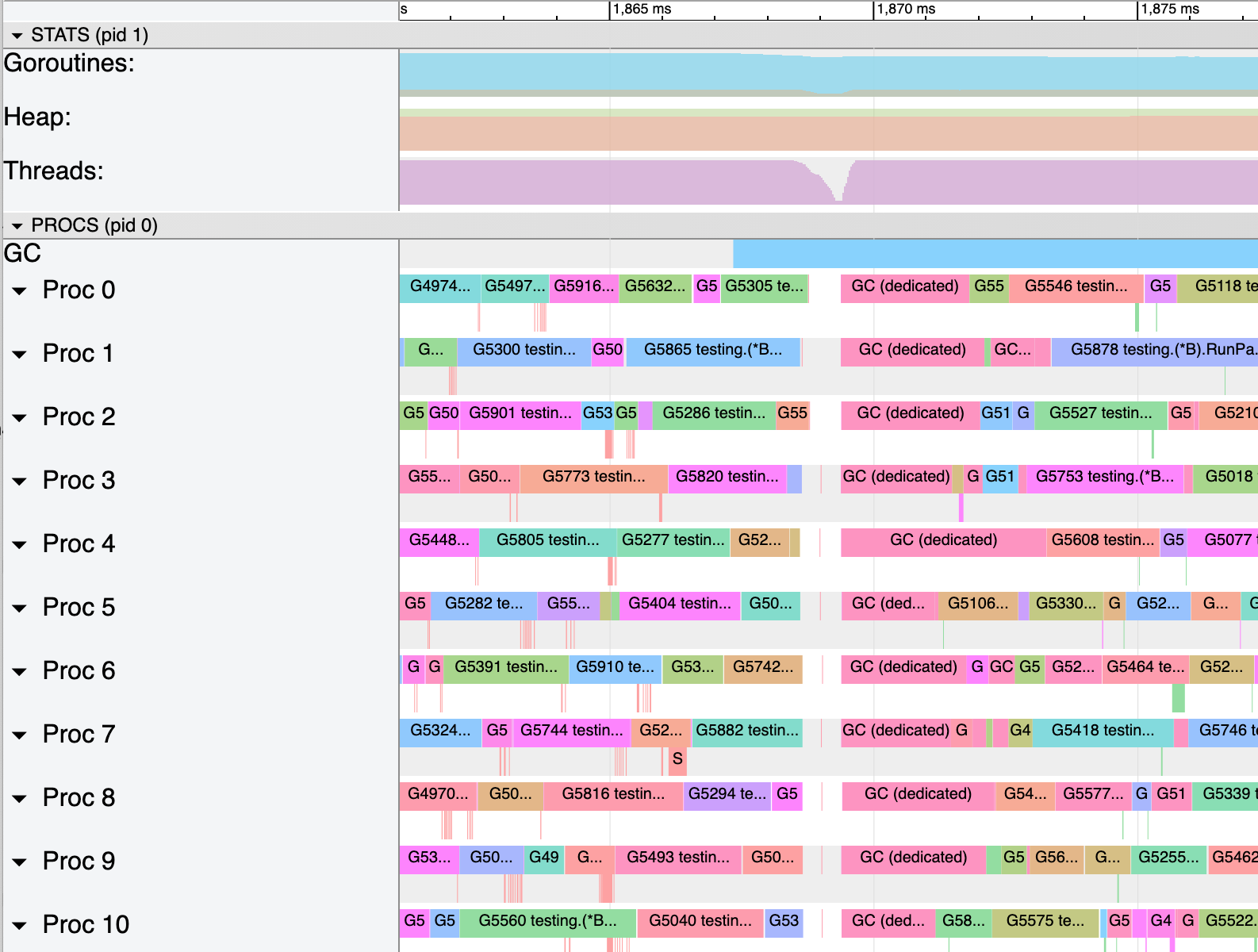
Here's another part of the go1.16.3 execution trace, showing a slow resume at the end of mark. Nearly all of the Gs are in the mark assist queue (the left half of the "Goroutines" ribbon is light green), and nearly all of the Ps are idle (very thin lavender "Threads" ribbon). Once the idle Ps start getting back to work (growing lavender, start of colored ribbons in the "Proc 0" etc rows), it takes about 4ms for the program to get back to work completely. This is the high-level bug behavior.
Here's a third part of the go1.16.3 execution trace, with an interesting middle-ground. After the STW, the lavender "Threads" ribbon grows to about 80% of its full height and stays there for a few hundred microseconds before growing, more slowly than before, to 100%. I interpret this as almost all of the Ps having had local work (so procresize returns them and they're able to start immediately), then forEachP holding sched.lock for a while and preventing further growth, and finally the mspinning mechanism finding the remaining Ps and putting them to work.
Here's Go tip at the parent of PS 6,
Here's PS 6, which (1) assigns goroutines from the global run queue to idle Ps as part of starting the world and (2) does not hold sched.lock in the parts of forEachP that do substantial work. It's from the same part of the benchmark's lifecycle as the previous image, but it only takes about 300µs for the Ps to get to work.
|




|
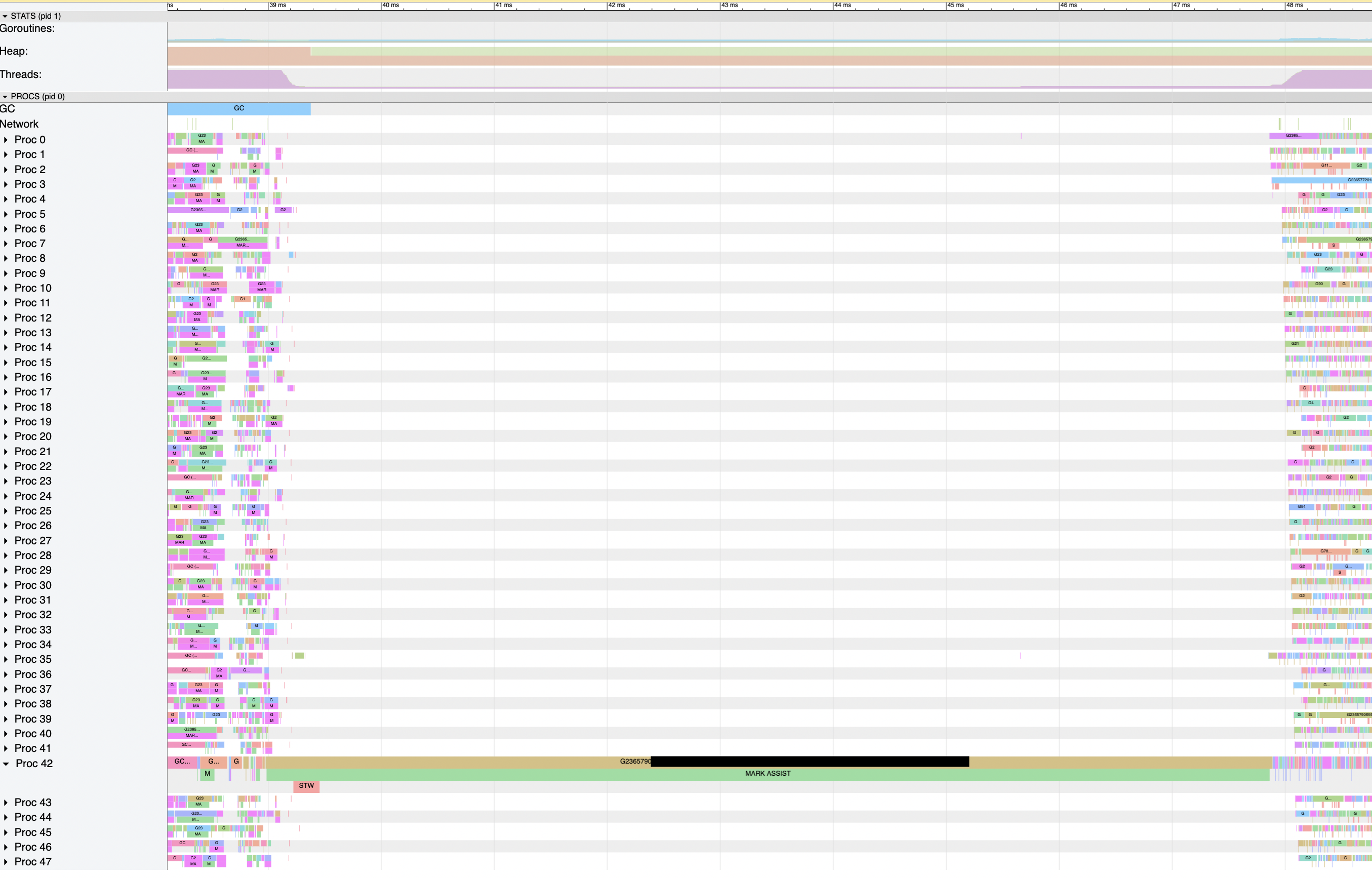
This effect still appears after an upgrade to Go 1.18. I've included an example execution trace below. Looking back at the reproducer I shared on 2021-05-05, I see it demonstrates some of the behaviors I've seen in production, but it's missing a key component: time where a single goroutine is in
The The The call to The And when a P starts running, the execution tracer draws a "proc start" line immediately after So Proc 42 in this execution trace is doing something within I collected CPU profiles from several hours of running time (on 48-thread machines) of one of the affected apps with Go 1.18. I've cut it down to time in Even if the runtime is able to get all of the Ms and Ps running quickly, they'll need serialize again for the mheap lock before they can do any work.
|


|
Wow, that STW section is tiny compared to the rest of it. I do wonder where that time is going. I really wish we could instrument the runtime and really break down into which of It is definitely weird that there aren't any Ps starting up in your execution trace. I'm not really sure how to explain it either. Starting the world calls The contention you're observing on Bottlenecks in restarting the world aside, it occurs to me that having an assist be responsible for the post-start-the-world tasks results in a pretty gnarly latency hit to whatever that goroutine was doing specifically. If other things are blocked on that goroutine, that's not great application-wide. |
|
The app depicted in the Go 1.18 execution trace uses the default setting for MemProfileRate of 512 kiB, the default GOGC=100, and a 10 GiB []byte ballast. It serves a large variety of requests that are typically much faster than the time between GCs. It does lots of small allocations at lots of unique allocation sites, around 10k locations and 100k stacks after a couple hours of run time. Each GC finds about 11 GB of garbage (live heap is about 1 GiB, plus 10 GiB ballast), so probably including 20,000 allocations known to the heap profiler. I don't know these parts (handling of specials, sweeping, mheap) well ... might every P in the app be trying to free a profiled allocation, and so be waiting on their M to have a turn on proflock? A delay getting that lock in Doing the Though in general, handing off the end-of-mark bookkeeping to a system goroutine would be nice! |
|
Yes, a big mProf can cause this behavior. (No need for dozens of threads!) Based on the CPU profiles I shared of the app on Go 1.18, that accounts for about 2/3rds of the post-STW CPU time in gcMarkTermination, so would pay dividends if fixed. The start of mprof.go is a note of "Everything here could use cas if contention became an issue." I plan to try fixing that in the next couple weeks. Is that a patch the runtime owners would be interested in for Go 1.19, @mknyszek ? Here's an execution trace from the 2021-05-05 reproducer, after adding code to allocate memory at at a few hundred thousand different call stacks, run with
|

|
Change https://go.dev/cl/399956 mentions this issue: |
The profiles for memory allocations, sync.Mutex contention, and general blocking store their data in a shared hash table. The bookkeeping work at the end of a garbage collection cycle involves maintenance on each memory allocation record. Previously, a single lock guarded access to the hash table and the contents of all records. When a program has allocated memory at a large number of unique call stacks, the maintenance following every garbage collection can hold that lock for several milliseconds. That can prevent progress on all other goroutines by delaying acquirep's call to mcache.prepareForSweep, which needs the lock in mProf_Free to report when a profiled allocation is no longer in use. With no user goroutines making progress, it is in effect a multi-millisecond GC-related stop-the-world pause. Split the lock so the call to mProf_Flush no longer delays each P's call to mProf_Free: mProf_Free uses a lock on the memory records' N+1 cycle, and mProf_Flush uses locks on the memory records' accumulator and their N cycle. mProf_Malloc also no longer competes with mProf_Flush, as it uses a lock on the memory records' N+2 cycle. The profiles for sync.Mutex contention and general blocking now share a separate lock, and another lock guards insertions to the shared hash table (uncommon in the steady-state). Consumers of each type of profile take the matching accumulator lock, so will observe consistent count and magnitude values for each record. For #45894 Change-Id: I615ff80618d10e71025423daa64b0b7f9dc57daa Reviewed-on: https://go-review.googlesource.com/c/go/+/399956 Reviewed-by: Carlos Amedee <carlos@golang.org> Run-TryBot: Rhys Hiltner <rhys@justin.tv> Reviewed-by: Michael Knyszek <mknyszek@google.com> TryBot-Result: Gopher Robot <gobot@golang.org>
What version of Go are you using (
go version)?Most of the data I have is from
go1.15.6.Does this issue reproduce with the latest release?
Yes, I have seen the same effect (as viewed from execution traces) in an app that uses
go1.16.3.What operating system and processor architecture are you using (
go env)?GOOS=linux and GOARCH=amd64
What did you do?
I have an app that uses
go1.15.6on machines with 96 hyperthreads (GOMAXPROCS=96), and an app that usesgo1.16.3on machines with 36 hyperthreads (GOMAXPROCS=36).What did you expect to see?
I expected the app's goroutines to resume work immediately after the runtime declares end of the mark termination stop-the-world phase. I expected processors to resume work one at a time, staggered by at most a few tens of microseconds, with dozens of threads resuming useful work every millisecond.
What did you see instead?
I see in execution traces that these applications are slow to resume useful work at the end of the garbage collector's mark phase. The application using Go 1.15 and 96-hyperthread machines has a particularly low latency goal (tail of a few milliseconds), and the slow resumption of work introduces about 5 to 10ms of extra idle time during each GC run.
My read of the traces, of profiles from
perf, and the runtime source is that althoughruntime.gcMarkDoneprepares goroutines to run (in large part by injecting the Gs that were blocked on assist credit into the global run queue) andruntime.gcMarkTerminationrestarts the world (so Ps can pick up and execute Gs), thegcMarkTerminationfunction follows that up immediately by usingruntime.forEachPto callruntime.mcache.prepareForSweep.When the goroutine that's finishing up the mark phase calls
runtime.forEachP, it has only recently allowed the world to restart, so most Ps are still idle. That function obtainsruntime.sched.lockand holds onto it while iterating the list of idle Ps, and calling the provided function for each one. My understanding ofsched.lockis that it guards access to the global goroutine run queue (among other things) -- and that in the two applications where I've seen this effect, nearly every goroutine in the program that would be runnable is sitting in the global run queue since nearly all of them became blocked on assist credit during the mark phase.I've included some screenshots from
go tool traceand contiguous section of the output ofgo tool trace -dbelow the fold, all from a single execution trace of the Go 1.15 app on a 96-hyperthread machine (during a load test, so it's especially busy). I'll walk through my understanding of how the events it shows line up with the code inruntime.gcMarkDoneand its callees.runtime.gcMarkTermination, https://github.com/golang/go/blob/go1.15.6/src/runtime/mgc.go#L1691runtime.startTheWorldWithSema, called fromruntime.gcMarkTermination, https://github.com/golang/go/blob/go1.15.6/src/runtime/mgc.go#L1752runtime.forEachP(probably a delayed acknowledgement of the first attempt, https://github.com/golang/go/blob/go1.15.6/src/runtime/proc.go#L1333)What I see in the
perfprofiles (collected with-Tfor timestamps,-gfor full call stacks, and-F 997for about 1ms per sample) is that the process does very little work at times (only one or two CPUs worth of samples, rather than dozens), and when I see what work it's doing during those times it is inside calls fromruntime.gcMarkDonetoruntime.systemstacktoruntime.gcMarkTermination.func4toruntime.forEachPfor several samples in a row.CC @aclements @mknyszek
The text was updated successfully, but these errors were encountered: