On Accurate Evaluation of GANs for Language Generation #21
Comments
SummaryThis paper presents a systematic re-evaluation for a number of recently purposed GAN-based text generation models. They argued that N-gram based metrics (e.g., BLEU, Self-BLEU) is not sensitive to semantic deterioration of generated texts and propose alternative metrics that better capture the quality and diversity of the generated samples. Their main finding is that, neither of the considered models performs convincingly better than the conventional Language Model (LM). Furthermore, when performing a hyperparameter search, they consistently find that adversarial learning hurts performance, further indicating that the Language Model is still a hard-to-beat model. Motivations for GAN-based Text Generation Models
Motivations for This Paper
Types fo Benchmarked Models
Tricks to Address RL Issues for Training Discrete GAN Models
Discrete GAN ModelsSeqGAN
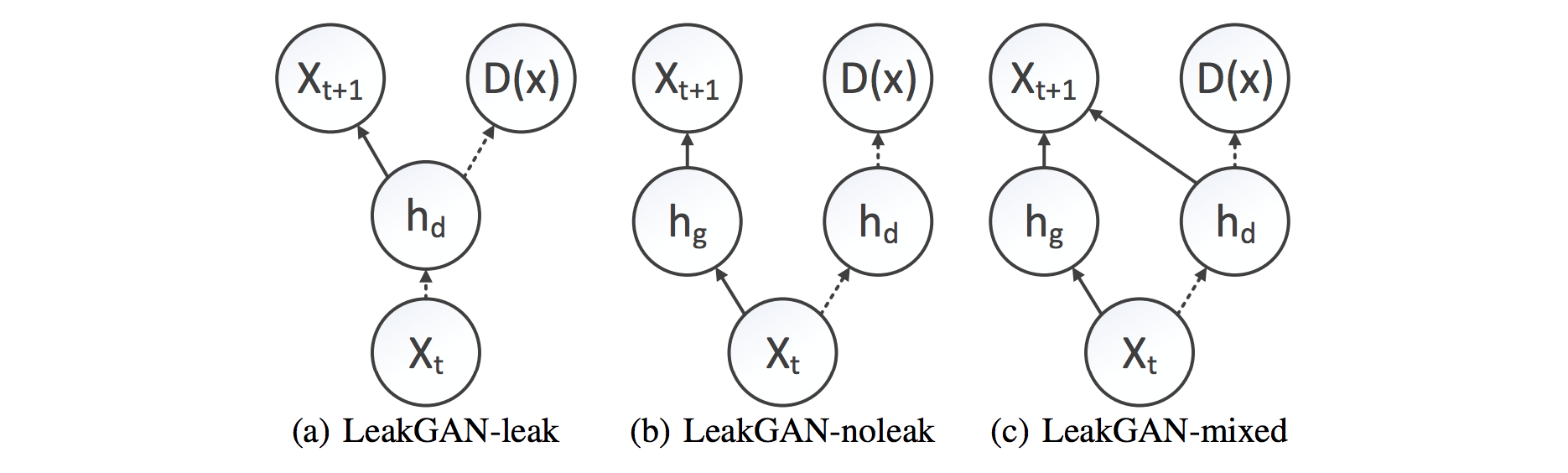
LeakGANReveal D's state to the G. They found that it is important to fuse D's and G's state with a non-linear function and thus they use a one-layer MLP to predict the distribution over the next token. In this setup, they use per-step discriminator. Three variants of the LeakGAN model that differ in how a hidden state of D is made available to G are considered: LeakGAN-leak, LeakGAN-noleak and LeakGAN-mixed:
Evaluation MethodologyMetrics
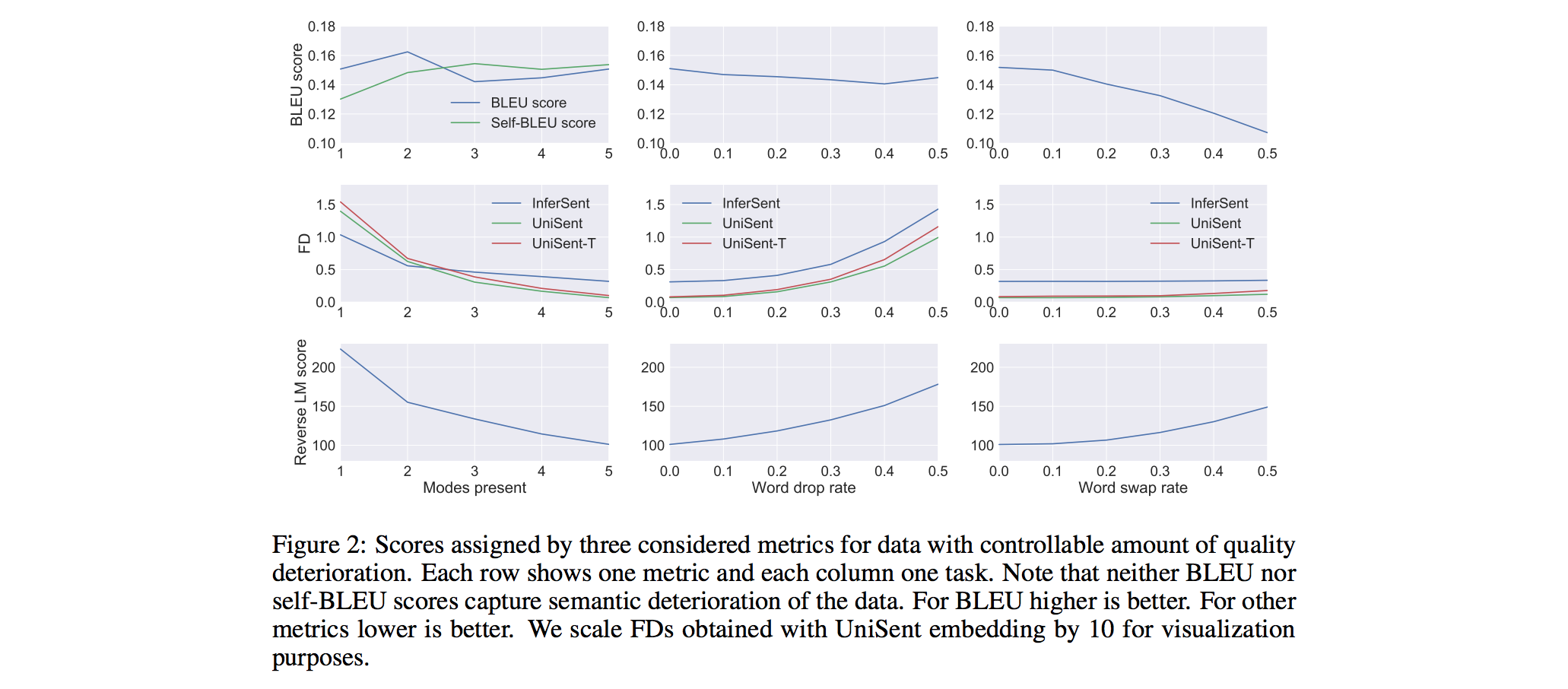
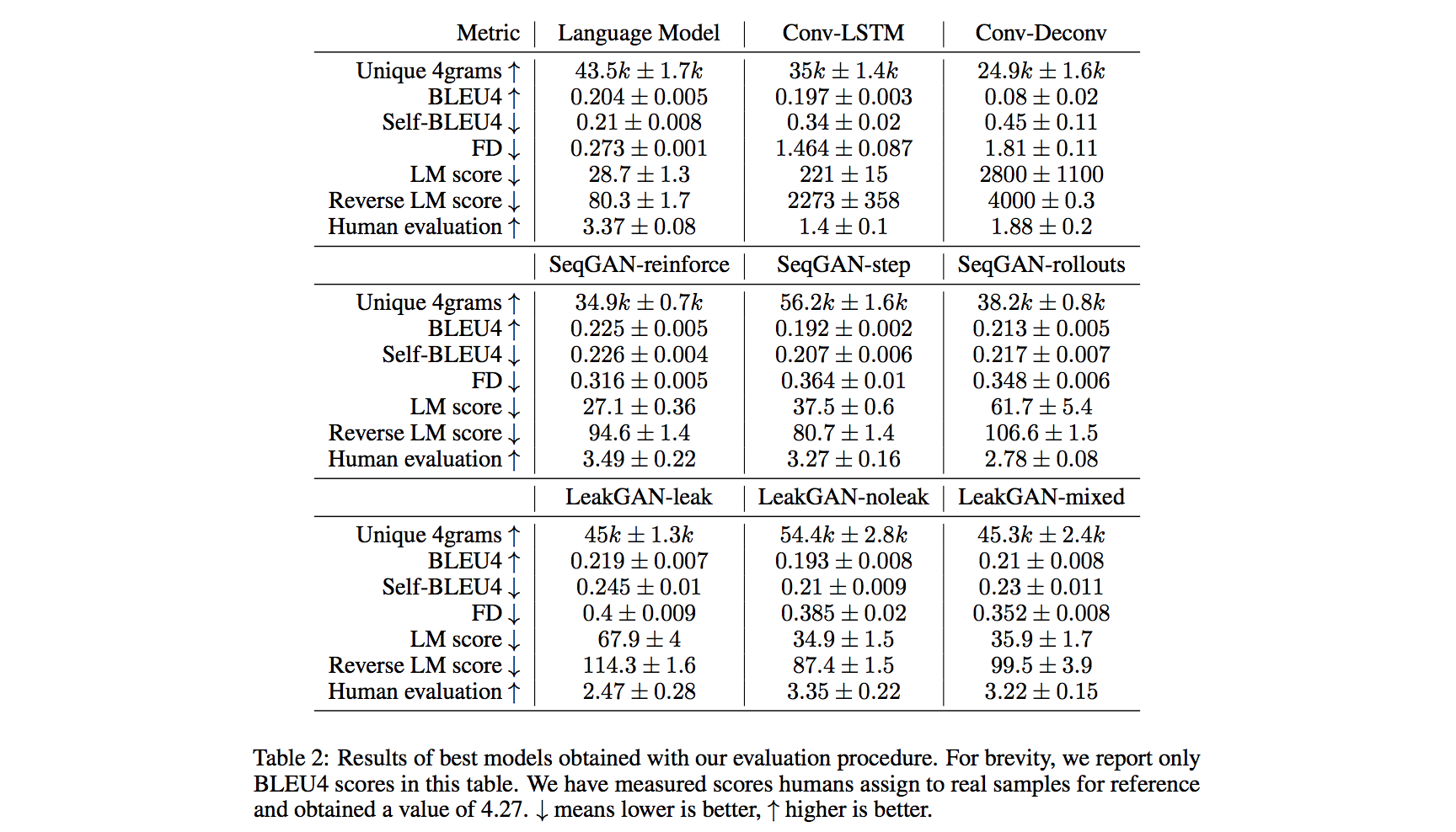
Parameter optimization procedureThey optimize each model's hyperparameters with 100 trials of random search. Once the best hyperparameters is found, they retrain with these hyperparameters 7 times and report mean and standard deviation for each metric to quantify how sensitive the model is to random initialization. Data600k unique sentences from SNLI & MultiNLI dataset, preprocessed with the unsupervised text tokenization model SentencePiece, with a vocabulary size equal to 4k. Metric Comparison
The experiments suggest that both FD and reverse LM score can be successfully used as a metric for unsupervised sequence generation models. GAN Model Comparison (Important Findings)For all GAN models, they fix the generator to be one-layer Long ShortTerm Memory (LSTM) network.
Future Research
Related Work
|
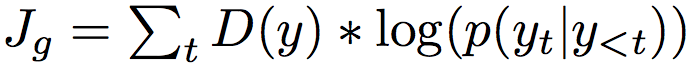
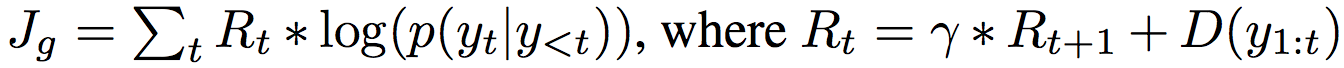

|
Dear howardyclo, |
|
@xpqiu Hi Xipeng |
Metadata
Authors: Stanislau Semeniuta, Aliaksei Severyn, Sylvain Gelly
Organization: Google AI
Conference: NIPS 2018
Paper: https://arxiv.org/pdf/1806.04936.pdf
The text was updated successfully, but these errors were encountered: