Model Parallelism and Big Models #8771
Comments
|
Thank you, @alexorona! I'm still in the process of gathering info/reading up and doing some small experimentation, so will post my thoughts once I have something concrete to share. Here are some resources if someone wants to join in: Abbreviations:
Resources:
|
|
Update: so we have
I don't have proper benchmarks yet, but I can definitely see 3-5 times less gpu ram usage! So these would be the first go-to solution when a model doesn't fit onto a single GPU. |
|
OK, so studying @alexorona's t5 MP implementation I think we have a few issues related to how we spread out the models across different devices. For the purpose of this discussion let's use a simplistic approach of having just 2 GPUs (g1 and g2) @alexorona's current approach is to assume that encoder and decoder are of the same size and then split 1/2 encoder layers onto g1 and the other half onto g2. Repeat the same for decoder. This approach has 3 issues:
It does make the implementation relatively simple, since we just need to move half the layers of the encoder to g1 and the other half to g2 and bring the inputs/outputs to the right devices.
(note: I'm using a non-python notation of a range here) It will be trickier to allow overlap if the number of layers is different between encoder and decoder - say 6:9 or 6:12 - In which case it might be: So the model will need to be able to transparently handle switching layers and inputs/outputs not only through its encode/decoder layers but also from encoder to decoder - but it's quite doable. This uneven situation would also be the case on some weird setups like mine where the gpus are of different sizes. On my setup I have one card of 8GB and another 24GB. This won't be an issue with @alexorona's current implementation.
If any of you have had a chance to think about possible solutions and some totally different ways of approaching that please share your insights. |
|
I was so full of hope that a simple dictionary could serve as a It looks like you've really busy the last week. Responding to your comments and PRs... |
|
Thank you for your follow up, @alexorona. As you're saying that from your experience the copying overhead is negligible then your current solution would work perfectly fine in some situations, like the balanced t5, but will need to be altered in others. So very likely it's this and that, rather than not this but that. i.e. no shuttered hopes. And if this doesn't fit in other situations it can be extended with a separate device_map for encoder and decoder. Perhaps for some models it'd be most efficient to keep the encoder on one set of devices and decoder on the other, and others shared. So that means we need to come with a way of accepting a variety of different device maps. Perhaps, we make the device_map to have two parts, but the second part (decoder) to be optional and if not passed then the first one is used for both? Then the simple solution remains mainly unchanged. May I ask if you have used some existing implementation to model your current implementation after, and perhaps you have a list of various MP implementations so that we could study and find the most suitable way that would fit. So far I have only studied the way you approached it. Thank you. p.s. here are some examples of models with different encoder/decoder sizes: |
|
I have a few follow up questions, @alexorona
vs giving the whole gpu to one of them: Thank you! |
|
@alexorona I had a chance to briefly look at your approach to model-parallelism via explicit device map construction. What are your thoughts on extending this approach via the construction of a generic Megatron-style Would it make sense to extend/tweak the device map approach to model-parallelism to fit within the |
|
@alexorona, I think I found at least one culprit for needing On the other hand I don't see |
|
Meanwhile I've finished porting It supports either type of map - your split approach or the one I proposed (flat). Here are some examples: I think down the road we could support other types by simply using different keys for whatever other configuration is desired. I think eventually we will need to benchmark the different splits and see which one is more efficient. e.g. the flat approach currently suffers from the shared embeddings since they need to be constantly switched back and forth between devices! I also have much improved magical device switching functions so it should be much faster to port to MP in the future. One other design change I will propose is to drop first/last devices and instead have |
|
We also may need to take into consideration @osalpekar's suggestion at pytorch/pytorch#49961 (comment) - I haven't studied that side of things yet so can't comment at the moment. On one side it appear much more complex to setup, on the other side it might make things much easier model-side-wise. If you already familiar with that side of things please share your insights. |
|
And another suggestion is to potentially use Pipe Parallelism here: pytorch/pytorch#49961 (comment) by @pritamdamania87 The main issue would be that it'll be enabled in pt-1.8 But @pritamdamania87 raises a super-important point - and that the current implementation doesn't take advantage of the multiple gpus, other than for their memory. So all the other gpus idle while one works, which is probably not what we want. Unless I'm missing something then this means that the current approach that we have been discussing (and released) is really a no-go. Please correct me if I'm wrong. |
|
Pipeline parallelism is already supported in DeepSpeed, although I haven't played around with it. |
|
yes, and |
|
@alexorona, please have a look at this super-important comment pytorch/pytorch#49961 (comment) We were trying to get rid of it. Now it looks like we need to make sure we have it in every place we switch to a new device. So when switching to a new device we need:
|
|
I was asked to share a sort of design/explanation of what we have implemented so far, so here you go (@alexorona please correct me if I have missed anything - thank you!) Here is an example of a Note that I collapsed the huge bulk of it and it's represented by just 2 lines that I wrote myself - it was not the output of the model dump. this is some 90% of the model and that's what we want to spread out through multiple gpus. So we have the bulk of memory used by 6 x For the simplicity of the example let's say we have 2 gpus we want to split the model into. Currently the idea is to put the 6 encoder layers on gpu 0 and the same for decoder layers but on gpu 1: or alternatively, splice each group as following: and the remaining non-encoder/decoder layer modules can be all on gpu 0 or grouped closer to where they are needed. We still haven't quite finalized that map. Of course, other models may have more or less layers and they don't have to have the same number of layers in encoder and decoder. Now that we have the map, we can place different layers/blocks on different devices A simplified explanation would be with the usual drawing of the deep nn (random blocks in this example) Implementation details:
Complications:
To port a model one needs to apply the device map (stage 2 above) and then gradually deal with wrong device errors, by remapping the inputs to the devices of the params of the layer. Alex was doing each variable manually, which is a huge pain. I automated this process (it's in 2 PRs that haven't been merged yet, the Bart PR has a smarter function) Transitions:
Here one only need to change devices twice
but of course, since the user may choose to split them vertically as so: there will be more switches here. So with the automation of switching Overall, with the great foundation @alexorona laid out and with a bit of the automation I added the implementation is solid and would work just fine for those who can afford idling gpus. What we need to figure out next is how these idling gpus will co-operate with all the other great components we have been working on (fairscale/deepspeed/pytorch pipelines/etc.) |
|
Great recap @stas00 |
|
update: I made t5 work with HF trainer and --model_parallel in eval mode #9323 - needed to copy the outputs back to the first device - it's more or less fine in the training stage (it worked in the first place), but w/ beam search size 4 it's 10x slower on eval w/ MP than w/o MP - it gets hit badly by the back-n-forth data copying. |
|
The more I'm reading on various Parallelization strategies the more I see how confusing the terminology is. What's most call Model Parallel (MP) should probably be called "Model Distributed" - since all we are doing here is splitting the model across several GPUs, as such "Model Distributed" is a much closer to reality term. Next comes Pipeline Parallelism (PP) - where we split the mini-batch into micro-batches and feed into Model Parallel / Model Distributed, so that while a GPU that completed its It's much easier to understand this by studying this diagram from the GPipe paper
This diagram makes it very clear why what we have implemented is what it calls a a naive MP, and you can see the huge idling with 4 GPUs. It then shows how it tries to resolve this idling problem with Pipeline. There is still idling but less so. It also misrepresents the length of time forward and backward paths take. From asking the experts in general backward is ~2x slower than forward. But as I was corrected on slack, the length of the bubble is about the same regardless of their execution speed. (Thanks @deepakn94) And Deepak also stressed out that since with PP there is a splitting into micro-batches, the effective batch size has to be big enough, otherwise PP will be idling too - so it requires experimentation to find a good batch size. Bottom line, PP is an improved version of MP, according to my current understanding. I'm still still researching. I think the real Parallelization is the ZeRO paper where Sharding/Partitioning is done and then it's truly parallel processing, but I'm still trying to understand what exactly is going on there. (Need to find a good diagram visually showing what it does) Grr, I see others use sharding/partitioning as a replacement for parallelism... so confusing. I updated #8771 (comment) with resources on PP and next need to try to convert perhaps t5 to PP and see how it works in practice. There will be issues to overcome due to BN and tied weights. |

|
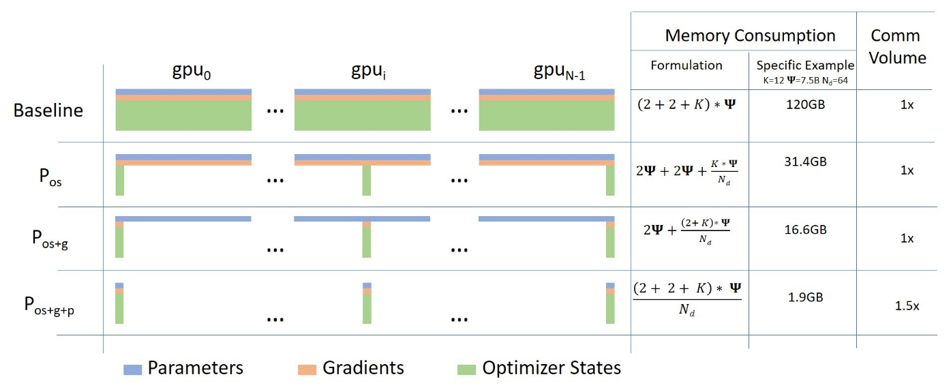
@deepakn94 helped me to finally grasp ZeRO-powered data parallelism, as it's described on this diagram from this blog post So it's quite simple conceptually, this is just your usual DataParallel (DP), except, instead of replicating the full model params, gradients and optimizer states, each gpu stores only a slice of it. And then at run-time when the full layer params are needed just for the given layer, all gpus sync to give each other parts that they miss - this is it. Consider this simple model with 3 layers and each layer has 3 params: Lx being the layer and we have 3 layers, and ax being the weights - 3 weights If we have 3 GPUs, the Sharded DDP (= Zero DP) splits the model onto 3 GPUs like so: In a way this is horizontal slicing, if you imagine the typical DNN diagram. Vertical slicing is where one puts whole layer-groups on different GPUs. But it's just the starting point. Now each of these GPUs will get the usual mini-batch as it works in DP: The inputs are unmodified - they think they are going to be processed by the normal model. So the inputs first hit the first layer La. Let's focus just on GPU0: x0 needs a0, a1, a2 params to do its forward path, but GPU0 has only a0 - so what it does is it gets sent a1 from GPU1 and a2 from GPU2. Now the forward step can happen. In parallel GPU1 gets mini-batch x1 and it only has a1, but needs a0 and a2 params, so it gets those from GPU0 and GPU2. Same happens to GPU2 that gets input x2. It gets a0 and a1 from GPU0 and GPU1. As soon as the calculation is done, the data that is no longer needed gets dropped - it's only used during the calculation. The same is repeated at every other stage. And the whole larger thing is repeated for layer Lb, then Lc forward-wise, and then backward Lc -> Lb -> La. To me this sounds like an efficient group backpacking weight distribution strategy:
Now each night they all share what they have with others and get from others what the don't have, and in the morning they pack up their allocated type of gear and continue on their way. This is Sharded DDP / Zero DP. Compare this strategy to the simple one where each person has to carry their own tent, stove and entertainment system, which would be far more inefficient. This is DataParallel in pytorch. And I think pretty much everywhere I read Sharded == Partitioned, so I think those are synonyms in the context of distributed models. |
|
edit: 2021-02-15: Note that The simplest way to quickly reproduce the following is to switch to the transformers sha of the time this was posted, that is: The amazing discovery of the day is DeepSpeed's Zero-Offload. ZeRO-Offload is a ZeRO optimization that offloads the optimizer memory and computation from the GPU to the host CPU. You can use DeepSpeed with a single GPU and train with huge models that won't normally fit onto a single GPU. First let's try to finetune the huge No cookie, even with BS=1 Now update your and let's try again: et voila! we get a BS=20 trained just fine. I can probably push BS even further. It OOMed at BS=30. Amazing! Important note - I used The config file I had to lower the ZeRO buffers from the default 5e8 to 2e8, otherwise it was OOM'ing even on BS=1. important: DeepSpeed made some changes in the non-released version as of this writing and so the above config won't work anymore. It dropped And it's not optimized yet, I just found at least one config that worked for this simple proof-of-concept test. Go and check it out! edit: I was asked about RAM usage for this task, it was 71GB peak, I re-run the same command as above with: So the peak RSS entry is 71GB: The doc is here: https://huggingface.co/transformers/master/main_classes/trainer.html#deepspeed @alexorona, I think you'd be super-happy about this one. p.s. if you need to setup the dir and the data, first do: before running any of the above scripts. Oh, and I'm on pytorch-nightly since that's the only version that works at the moment with rtx-3090. |
|
edit: 2021-02-15: Note that The simplest way to quickly reproduce the following is to switch to the transformers sha of the time this was posted, that is: OK and to finish the day here are some benchmarks - thank you @sgugger for letting me run those on your machine with dual titan rtx. Let's start with the results table:
Baseline + data setup was: Notes:
Results: Well, Deepspeed beats all solutions that were compared - it's much faster and can fit much bigger batches into the given hardware. as you can see from the previous post #8771 (comment) - the cpu offloading while is slower on training it can fit more into your hardware. and it's the winner for eval! Note: these benchmarks aren't perfect as they take a lot of time to handle you can see that BS numbers are pretty rounded - surely they can be somewhat bigger and speed somewhat better as a result, so I'm sure both sharded ddp and deepspeed can be optimized further. But that's a good start. As both sharded ddp and deepspeed are now in master https://huggingface.co/transformers/master/main_classes/trainer.html#trainer-integrations please go ahead and do your own benchmarks. And now the raw results - sorry it's not markdown'ed: Here is the config file that was used for deepspeed: https://github.com/huggingface/transformers/blob/69ed36063a732c37fdf72c605c65ebb5b2e85f44/examples/seq2seq/ds_config.json |
|
Hi, a bit of time has passed, and it seems some information here is outdated. If possible, could someone please describe what is necessary in order to train a T5-3b or T5-11b model on 1 or more 32GB or 40GB GPUs and with a sequence length in the input of up to 512 and up to 256 for the target? Has this been achieved? Are additional pieces of configuration necessary for model parallelism or is the deepspeed wrapper somehow triggering model parallelism in the hf trainer? My observations so far have been that T5 training is very unstable with --fp16 and torch.distributed.launch, and I am not sure that deepspeed can overcome this problem. Could anyone comment on the training stability? So far this conversation has mostly touched on avoiding OOM while the aspect of training results has not been given much attention. Thank you! EDIT: I would also be thankful for an explanation for why smaller buffer sizes enable larger batch sizes. |
I'm pretty sure it should be possible, certainly with t5-3b, with t5-11b I will have to try. And if you have access to NVMe you can train even larger models with DeepSpeed ZeRO-Infinity. Just give me a few more days to finalize the ZeRO-Infinity integration into transformers. This is all very new and their docs are very lacking still, but it will be fixed, so I'm trying to gather the information needed to take advantage of it, as it's not trivial to configure - need to run a benchmark first. In the good news you can extend your CPU memory with any storage, it just might be very slow if the storage is slow :)
We don't use the parallelism from Deepspeed, but mainly its ZeRO features, which more or less allow one not to worry about parallelism and be able to train huge models. Parallelism requires huge changes to the models.
Yes, all You will find a handful of issues wrt Nan/Inf in t5 and mt5. You can try this workaround I experimented with: #10956 If you have access to Ampere-based cards (rtx-3090/A100), please see: #11076 (comment) |
|
Hi @stas00, thanks for the prompt response. Am I understanding correctly that deepspeed with T5 is inadvisable at the moment because until deepspeed supports FP32 it will use FP16 which will destroy the T5 model? |
|
Most complaints were mainly about mt5 and not t5 as of recent, @PeterAJansen, could you please comment here since I know at some point you were extensively working with t5-11b w/ deepspeed - did you run into nan/inf problems there? I asked @samyam to make a PR from his full-fp32 branch https://github.com/microsoft/DeepSpeed/tree/samyamr/full-precision-for-stage3, but you can already use it. gpt-neo folks appear to have successfully started using it to overcome the over/underflow issue.
|
|
@stas00 it's a good question. I only became aware of the potential T5 fp16 issue recently, and I haven't noticed anything wonky in the models that I've been training -- but that's not to say that everything I've trained might be underperforming and able to perform vastly better, since I've been training models on new tasks rather than existing ones. To verify things are running as expected, I should probably run an fp16 version of a common dataset task that (ideally) could be trained and evaluated in less than a day. Any suggestions from the examples section? |
|
Thank you for sharing your experience, @PeterAJansen. I mostly encountered reports with mt5 as of recent. Since you own A100s (and those with RTX-3090) it shouldn't be too long before pytorch and deepspeed support native |
|
Have you managed to use activation checkpointing? |
Would be happy to follow up, but such kind of questions are impossible to answer. Who is "you"? In what context? What is the problem? May I suggest opening a new Issue and providing full context and the exact problem you're dealing with or a need you have? Thank you! |
|
Hi @stas00, Thanks for all your contributions with deepzero integration. I find it fascinating and awesome! According to your comments, it doesnt seem like deepspeed is able to use model parallelism (not data parallelism). Does this make it impossible to use t5-3b on an nvidia v100 16G 8 gpu card? I have tried a couple of different configurations of deepzero stage 3, including the provided configuration in master; however, I am only able to use a batchsize of 1 or 2. I am using a max sequence length of 512 for both input and output. I can achieve these same results if I use model.parallelism and split t5 across the 8 gpus. Thanks! |
|
In general:
Now to your specific setup. Offloading some of the memory should do the trick. Here is some helpful API to estimate the memory needs for params, optim states and gradients: https://deepspeed.readthedocs.io/en/latest/memory.html#api-to-estimate-memory-usage It still is missing the activations and temps memory needs but it already gives you a pretty good picture of which configuration to pick: Zero2 Zero3 So you can see that if you have a nice chunk of CPU memory available, it should be trivial for you to load a large bs with large seqlen. and this was written pre-NVMe offload addition, so you have that option too if you don't have much CPU memory, but consider it as an extension of CPU memory so the above numbers will still be the same gpu memory-wise. p.s. Megatron-LM has just added t5 to their arsenal, but it lacks PP as of this writing. |
|
Yes, specific problem solving is best done in a dedicated thread. So let's continue there. Please tag me so that I see it. |
|
@stas00 @sacombs Maybe there's two or three typical use cases we could articulate? After having studied the documentation and your threads on this Stas, I'm still only able to get models in the range of 1.5B parameters training on a single 16GB GPU. The advantage is that it uses far less GPU memory than it would normally take (about 30%), but it is 5 times slower. That's a very acceptable trade-off in terms of VM cost. I haven't been able to effectively train large models like GPTNeo-2.7B and T5 using multiple GPUs. It seems like the deepspeed integration automatically creates a number of nodes/workers equal to the number of GPUs, so if you can't train it on one GPU, adding multiple GPUs makes no difference. I've tried with both zero3 and zero3-nvme configurations. @stas00 Example 1: Fine-tuning t5-3B Using zero3 and zero3-nvme with Multiple GPUs Requirements
Running GPU OOM Messages
Example 2: Fine-tuning EleutherAI/gpt-neo-1.3B Using zero3 on a Single GPU Requirements
Running GPU OOM Messages
|
|
That's a great idea, @alexorona! These would be super-useful. Let's do it! Do you want to also define the actual GPU sizes? It'd be very different if one uses 80GB A100 comparatively to 16GB V100. Perhaps repasting each of these into a separate issue so that we could work on tuning these up independently? Let's start with 2-3 and then we can expand it to more. I'm a bit busy in the next few days with the bigscience first launch, but otherwise can work on it when I get some free time and we can of course ask the Deepspeed to help. Once polished these would make a great article/blog_post. |
|
Just to update: I think we will get the best outcome if one or a few people with an actual need and hardware to match will post an issue and then we will work on solving it and while at it come up with the settings/guidelines for models in question. Also I'm at the moment mostly busy with the bigscience project, which takes the lion's share of my time. So I'd be delighted to support someone with a need, but probably won't have enough incentive to carve out the time to act on both sides. I hope this makes sense. |
|
Hi, I followed what you said here, but it said that "TypeError: issubclass() arg 1 must be a class". |
|
this is a very old thread, could you please open a proper new Issue with full details of what you did, versions, the full traceback and how we could reproduce the problem and please tag me. Thank you. |
|
Based on a working Python model training script, I made the simplest changes with Trainer (by add deepspeed='ds_config,json'), but met the below error, any tips? I did not set local_rank at all, no idea why that error mentioned:
|
|
As mentioned earlier please open a new Issue and for all deepspeed integration-related issues please tag @pacman100 who is the current maintainer of it. Thank you! |
🚀 Feature request
This is a discussion issue for training/fine-tuning very large transformer models. Recently, model parallelism was added for gpt2 and t5. The current implementation is for PyTorch only and requires manually modifying the model classes for each model. Possible routes (thanks to @stas00 for identifying these):
fairscaleto avoid individual model implementationdeepspeedto possibly enable even larger models to be trainedThe text was updated successfully, but these errors were encountered: